






1.订单路径树的定义
用户从打开某网站到最终下单所点击的路径为订单路径树。
比如:打开某电商app或者网站到最终下单的路径,大部分用户的路径为:
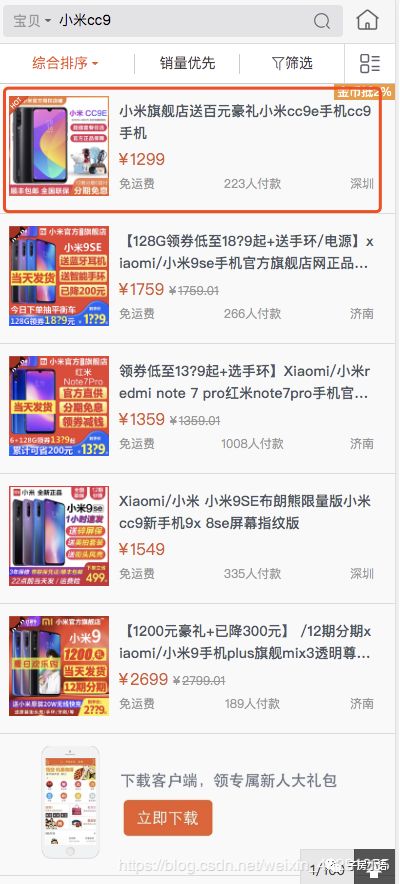
(1)主页-搜索页-商详页-加购-下单(搜索下单路径)

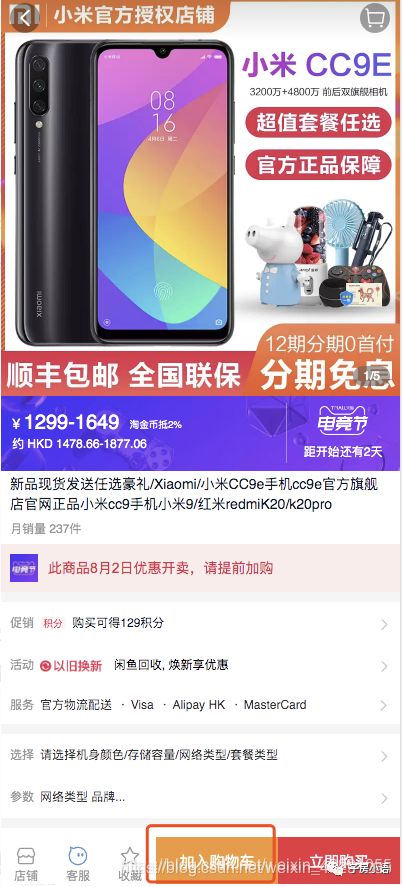
(2)首页-列表页-商详页-加工-下单(列表页下单路径)
(3)当然用户也可以进行其他的无规则的点击,最终加购下单,都会生成用户从点击到购买的路径行为。
2.订单路径树的作用
(1)可以统计某个点击位的引单效果的好坏
(2)可以统计某个广告位的引单效果的好坏
(3)转化率好坏
(4)....
3.订单路径树的生成逻辑
通过上面理解,可以看到主要涉及到用户的点击操作和最终订单生成,构建成一个完整订单路径。
因此主要需要两类数据:(1)点击流数据,即:用户的点击行为数据 (2)订单流数据
用户的点击行为数据实时上报到kafka:cl
cl 包含关键字段字段:cts(客户端时间)、rts(服务端时间)、eventid(点击位唯一标示)、uid(用户唯一id)、pv_sid(访次)、param(参数)
下单数据实时上报至kafka:od
od 包含关键字段:orderId、skuIds(sku列表)、uId(会话id)
因为cl只含有点击点击位信息,需要关联埋点方案表信息,埋点方案表涵盖:eventId(点击位唯一标示)、pageNum(页面唯一编号)、加购标示。
第一步:接入cl、od实时流数据(注意做幂等处理,cl根据所有字段生成唯一标示MD5化,od根据oderid作唯一处理),加载埋点数据至内存
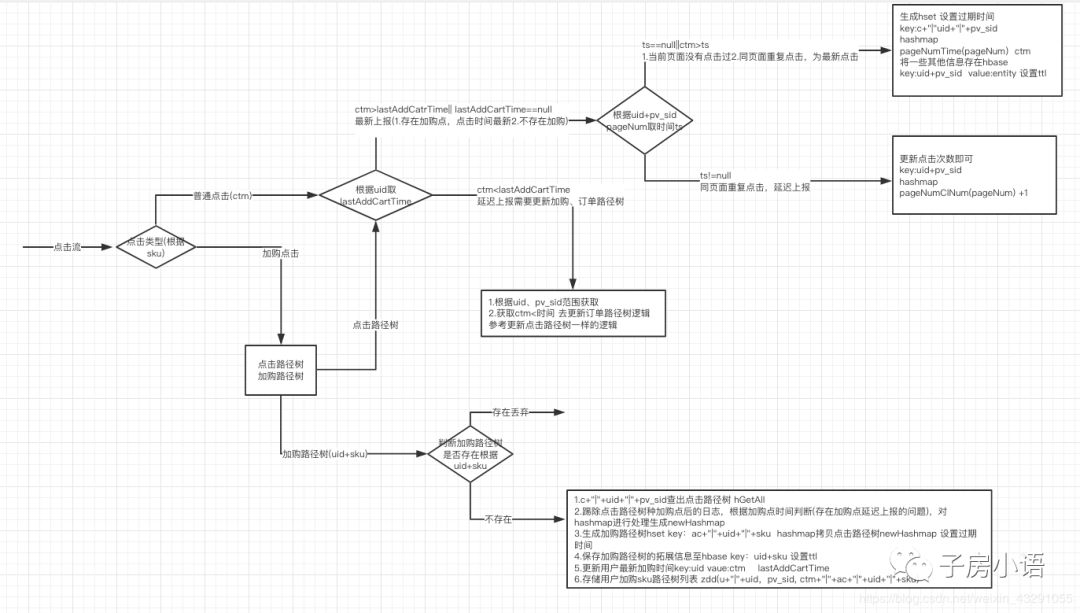
第二步:对cl数据进行处理,联上paNum,再根据paNum相对应的加购与否,如果是加购点就去解析sku
(1)生成点击路径树(普通点击)
每个key一个hset保存当前uid+pv_sid 的路径信息 关键clKey: c+“|”+uid+“|”+pv_sid
(2)生成加购路径树(加购点击)
逻辑为:拷贝点击路径树至加购路径树,关键addCartKey: ac+"|"+uid+"|"+sku
(3)订单路径树(加购路径树+订单流进行关联)
拷贝加购路径树至订单路径树,关键odKey:oc+"|"+orderId+"|"+sku
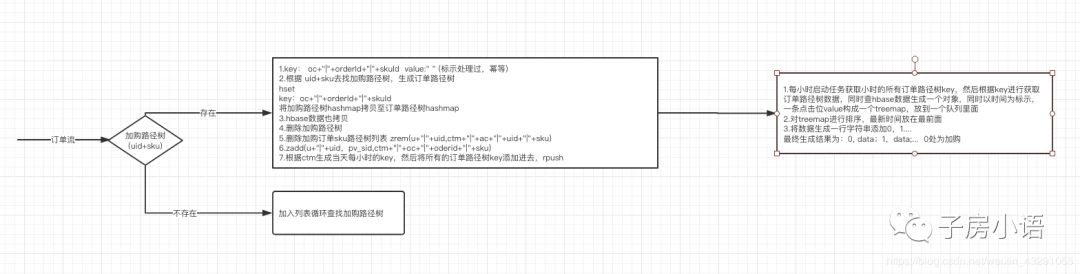
至此订单路劲树生成完成,格式为:
0,data;1,data;2,data;.... 其中0处为加购点
最终订单路径树结果可以写入到kafka(进行计算引入订单),也可写入到hbase或者hdfs(导入到hive进行查询)
订单找回率:订单路径树中的订单/订单表中的订单 (大概率在90%以上),部分原因是因为用户在不同端加购和购物导致uid和pv_sid不同
文中用到的技术:kafka、redis、hbase
(1)hbase的rowkey设计:md5加密
(2)hbase有ttl功能,因为点击路径树只需要保存24小时,加购路径树保存15天;时间设置可以修改根据需求修改,主要是节约存储资源,比如说mysql需要删除处理,所以选用hbase的原因,写入数据量较大,查询的时候根据rowkey进行查询,非常实用hbase的应用场景。
4.订单路径树优化升级方案
上述订单路径树方案存在的问题:
(1)数据延迟上报 上报顺序: a1(ctm1)、a2(ctm2)、b(加购 ctm) ctm1<ctm<ctm2 最后生产的路径树:b ,而实际路径树应该为a1、b
(2)数据量太大,hbase存储的扩展字段进行修改比较耗时。
因此做了如下优化:
(1)数据先进来保存10分钟再排序一起处理,解决延迟上报问题
(2)最新N条数据存redis(包括扩展字段),其他数据的扩展字段存hbase,因为最新数据需要进行频繁修改。
至此订单路径树生成完毕,可以使用订单路径树数据对用户订单行为进行分析、对广告的引单效果进行分析以及转换率进行分析。
订单路径树不仅仅对电商场景分析有用,对外卖(下单)、酒店、旅游(下单),甚至对电影或者视频网站也可以进行分析。

















 2488
2488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









