







 本文介绍命名实体消歧,将句中识别的实体与知识库匹配以解决歧义,可利用上下文本相似度识别。准备两个测试数据集,说明了结果提交格式和具体实现步骤,还可通过测试数据准确率优化抽取方式,代码及数据已上传至github。
本文介绍命名实体消歧,将句中识别的实体与知识库匹配以解决歧义,可利用上下文本相似度识别。准备两个测试数据集,说明了结果提交格式和具体实现步骤,还可通过测试数据准确率优化抽取方式,代码及数据已上传至github。
将句中识别的实体与知识库中实体进行匹配,解决实体歧义问题。 可利用上下文本相似度进行识别。
本文准备了两个测试数据集,entity_list.csv是50个实体,valid_data.csv是需要消歧的语句。
结果提交在submit目录中,命名为entity_disambiguation_submit.csv。
格式为:第一列是需要消歧的语句序号,第二列为多个“实体起始位坐标-实体结束位坐标:实体序号”以“|”分隔的字符串。
需要进行实体消歧的语句如下:

实体类别如下:
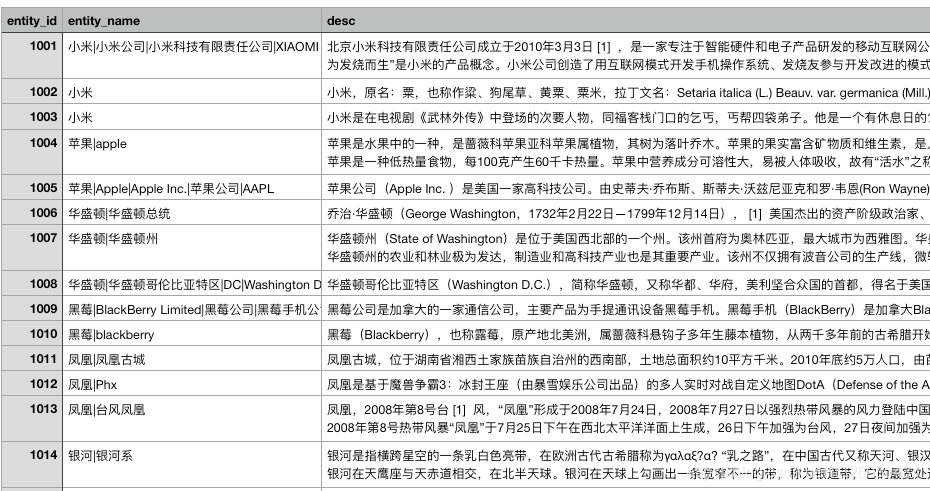
下面讲解具体的实现步骤:
1.导入数据
import jieba
import pandas as pd
# TODO:将entity_list.csv中已知实体的名称导入分词词典
entity_data = pd.read_csv('../data/entity_disambiguation/entity_list.csv', encoding = 'utf-8')
# TODO:对每句句子识别并匹配实体
valid_data = pd.read_csv('../data/entity_disambiguation/valid_data.csv', encoding = 'gb18030')
- 建立关键词组
将需要进行实体消歧的实体存进keyword_list
import collections
s = ''
keyword_list = []
for i in entity_data['entity_name'].values.tolist():
s += i + '|'
for k,v in collections.Counter(s.split('|')).items():
if v > 1:
keyword_list.append(k)
- 生成tfidf矩阵
from sklearn.feature_extraction.text import TfidfVectorizer
train_sentence = []
for i in entity_data['desc'].values:
train_sentence.append(' '.join(jieba.cut(i)))
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(train_sentence)
- 获取包含关键词的句子中关键词所属的entity_id
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
def get_entityid(sentence):
id_start = 1001
a_list = [' '.join(jieba.cut(sentence))]
res = cosine_similarity(vectorizer.transform(a_list),X)[0]
top_idx = np.argsort(res)[-1]
return id_start + top_idx
- 将计算结果存入文件
row = 0
result_data = []
neighbor_sentence = ''
for sentence in valid_data['sentence']:
res = [row]
for keyword in keyword_list:
if keyword in sentence:
# 查询关键词在句子中的索引
k_len = len(keyword)
ss =''
for i in range(len(sentence)-k_len+1):
if sentence[i:i+k_len] == keyword:
s = str(i) + '-' +str(i+k_len) + ':' # 拿到 x-x:
if i > 10 and i + k_len < len(sentence)-9:
neighbor_sentence = sentence [i-10:i+k_len+9]
elif i < 10:
neighbor_sentence = sentence [:20]
elif i + k_len > len(sentence)-9:
neighbor_sentence = sentence [-20:]
s += str(get_entityid(neighbor_sentence)) # 拿到 x-x:id
ss += s + '|' # 拿到 x-x:id|x-x:id
res.append(ss[:-1]) # 拼接成[0, 'x-x:id|x-x:id']
result_data.append(res)
row += 1
pd.DataFrame(result_data).to_csv('../submit/entity_disambiguation_submit.csv', index=False)
7.最后我们可以打印一下保存的结果
pd.read_csv('../submit/entity_disambiguation_submit.csv')
打印结果如下

格式为: 起始位置-结束位置|实体类别
我们可以看一下第一条 3-6:1008|109-112:1008|187-190:1008,确实是符合的。


在具体的实现过程中,我们可以通过测试数据的准确率去判断所抽取的字符长度是否合理,调整特征的抽取方式来优化准确率。
以上代码及训练数据已上传至github,有兴趣的同学可以点击这里查看。谢谢!

















 1728
1728

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









