







 本文深入剖析了最大熵模型,通过直观理解、数学角度和实例探讨,阐述了最大熵原理及其与朴素贝叶斯的关系。文章提供了相关算法的实现,并强调在面对不确定性时,最大熵模型如何通过最大化熵来保持概率分布的不确定性。同时,文章补充了针对MNIST数据集的应用提示,指出在实际应用中如何理解和处理特征与标签的关系。
本文深入剖析了最大熵模型,通过直观理解、数学角度和实例探讨,阐述了最大熵原理及其与朴素贝叶斯的关系。文章提供了相关算法的实现,并强调在面对不确定性时,最大熵模型如何通过最大化熵来保持概率分布的不确定性。同时,文章补充了针对MNIST数据集的应用提示,指出在实际应用中如何理解和处理特征与标签的关系。
欢迎直接到我的博客查看最近文章:www.pkudodo.com。更新会比较快,评论回复我也能比较快看见,排版也会更好一点。
原始blog链接: http://www.pkudodo.com/2018/12/05/1-7/
前言
《统计学习方法》一书在前几天正式看完,由于这本书在一定程度上对于初学者是有一些难度的,趁着热乎劲把自己走过的弯路都写出来,后人也能走得更顺畅一点。
以下是我的github地址,其中有《统计学习方法》书中所有涉及到的算法的实现,也是在写博客的同时编写的。在编写宗旨上是希望所有人看完书以后,按照程序的思路再配合书中的公式,能知道怎么讲所学的都应用上。(有点自恋地讲)程序中的注释可能比大部分的博客内容都多。希望大家能够多多捧场,如果可以的话,为我的github打颗星,也能让更多的人看到。
github:
相关博文:
- 统计学习方法|感知机原理剖析及实现
- 统计学习方法|K近邻原理剖析及实现
- 统计学习方法|朴素贝叶斯原理剖析及实现
- 统计学习方法|决策树原理剖析及实现
- 统计学习方法|逻辑斯蒂原理剖析及实现
- 统计学习方法|最大熵原理剖析及实现
正文
哪怕整书已经看过一遍了,我仍然认为最大熵是耗费我时间较多的模型之一。主要原因在于千篇一律的博客以及李航的《统计学习方法》在这一章可能为了提高公式泛化性而简化的关键点。当然了,在阅读上没有问题,可是在程序的编写上可能是我历时最久的。如果读者需要编写最大熵模型,比较建议使用我的博客配合代码学习,忘掉书上的这一章吧。
最大熵的直观理解
为了引出最大熵,我们可能需要举一个所有博客都会举的例子:如果我手里拿着一个骰子,想问你扔下去后是每一面朝上的概率是多少?所有人都能抢答出来是1/6。那么为什么是1/6呢?为什么不是1/2或者1/3?
因为六个面的概率相同呀
emmm....我暂时承认你说的有点道理。可是如果这是老千手里的骰子呢?你还会答1/6吗?
可是你没说是老千手里的骰子呀
你让我哑口无言了,但为什么大家在猜之前不会去假设是不是老千的骰子这种情况呢?
因为你没说是老千手里的骰子呀
完蛋了,又绕回来了。不过我想想也是,如果要考虑老千,那么也可能要考虑骰子是不是破损了,桌面是不是有问题......完蛋了,没头了。
所以1/6最保险呀
如果我告诉你1朝上的概率是1/2呢?
那剩下的就是1/10呀
emmm...我承认在目前的对话中你是明智的,而我像个低龄的儿童。但是我要告诉你,上面几句对话,其实就是最大熵。
当我们在猜测概率时,不确定的部分我们都认为是等可能的,就好像骰子一样,我们知道有六个面,那么在概率的猜测上会倾向于1/6,也就是等可能,换句话讲,也就是倾向于均匀分布。为什么倾向均匀分布?你都告诉我了,因为这样最保险呀!当我们被告知1朝上的概率是1/2时,剩下的我们仍然会以最保险的形式去猜测是1/10。是啊,最大熵就是这样一个朴素的道理:
凡是我们知道的,就把它考虑进去,凡是不知道的,通通均匀分布!
从另一个角度看,均匀分布其实保证的是谁也不偏向谁。我说万一是老千的骰子呢?你说万一骰子有破损呢?骰子好端端地放在那咱俩地里咕噜瞎猜啥呢。咱们与其瞎猜是啥啥啥情况,干脆就均匀分布,谁也不偏向谁。
多朴素的道理啊!
朴素贝叶斯分类器的数学角度(配合《统计学习方法》食用更佳)
在最大熵章节中我们在公式上仍然参考《统计学习方法》,除此之外会补充一些必要知识点,建议阅读完毕后浏览一下代码知道详细的用法。
最大熵模型是一个分类模型,这样,我们照旧不管中间过程,统统都不管,我们最终可能会想要这样一个式子: P(Y|X)。是啊,P(Y|X)就像一个终极的大门一样,扔进入一个样本x,输出标签y为各种值的概率。我们现在手里有一堆训练数据,此外手握终极大式子P(Y|X),是不是想到了朴素贝叶斯?我们对训练数据进行分析,获得先验概率,从而得到P(Y|X)模型进行预测。最大熵也有数据和相同的终极大式子,那么
最大熵和朴素贝叶斯有什么联系?
可以说在本质上是非常密切的,但具体的联系和区别,我希望读者正式了解了最大熵以后,我们一起放在文章末尾讨论。
文章的最初,我们需要给出最大熵公式,如果对下面这个式子不太熟悉的,可以查看《统计学习方法|决策树原理剖析及实现》一节 :

H(P)表现为事件P的熵变,也称为事件P的不确定性。对于最大熵模型而言,我们一直记得那个终极式子P(Y|X),如果放到骰子例子中,P(Y=1|X)表示扔了一个骰子,1朝上的概率,P(Y=2|X)表示2朝上的概率。我们之前怎么说的?我们只知道骰子是六面,至于其他情况我们一概不知,在不知道的情况下,我们就不能瞎做推测,换言之,我们就是要让这个P(Y|X)的不确定性程度最高。
不确定性程度最高?
可能有些读者这么一绕没回过神来,如果我告诉你点数1朝上的概率是1/2,你是不是对这个概率分布开始有了一点认识,那么会将剩下的面认为是1/10(注:1朝上概率是1/2,那么1背面的概率一定会降低,但我们没有考虑这件事情,事实上我们不应该添加任何的主观假设,因为实际上有些骰子1的背面是3,也有些是4,任何主观假设都有可能造成偏见产生错误的推断)。你推断剩余面是1/10的概率是因为我告诉了你信息,你对这个骰子开始有了一些确定的认识,也就是信息的不确定性程度——熵减少了。但事实上我没有告诉你这一信息,你对P(Y|X)的分布是很不确定的,那么我们能不能用使用下面这个式子,让H(P)最大化来表示我们对P(Y|X)的极大不确定呢?事实上当我们令下式中H(P)最大时,P(Y|X)正好等于1/6。也就是说,如果我们要让熵最大,P(Y|X)必须为1/6。换句话说,只有我们把骰子的每一面概率当做1/6时,才能充分表示我们对骰子每一面的概率分布的极度不确定性,骰子的概率这件事情的混乱度最高,同时也传递了一个信息:我们对这件事情没有添加任何主观的假设,对任何未知的东西没有偏见和主观假象,这是最保险、最安全的做法。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1241
1241

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










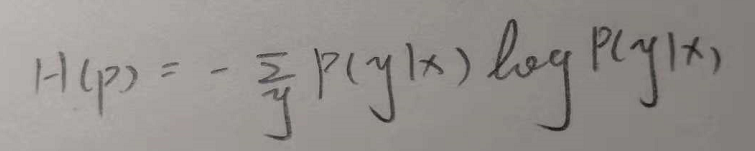{kind=link}