







对字节跳动 effective_transformermer的理解
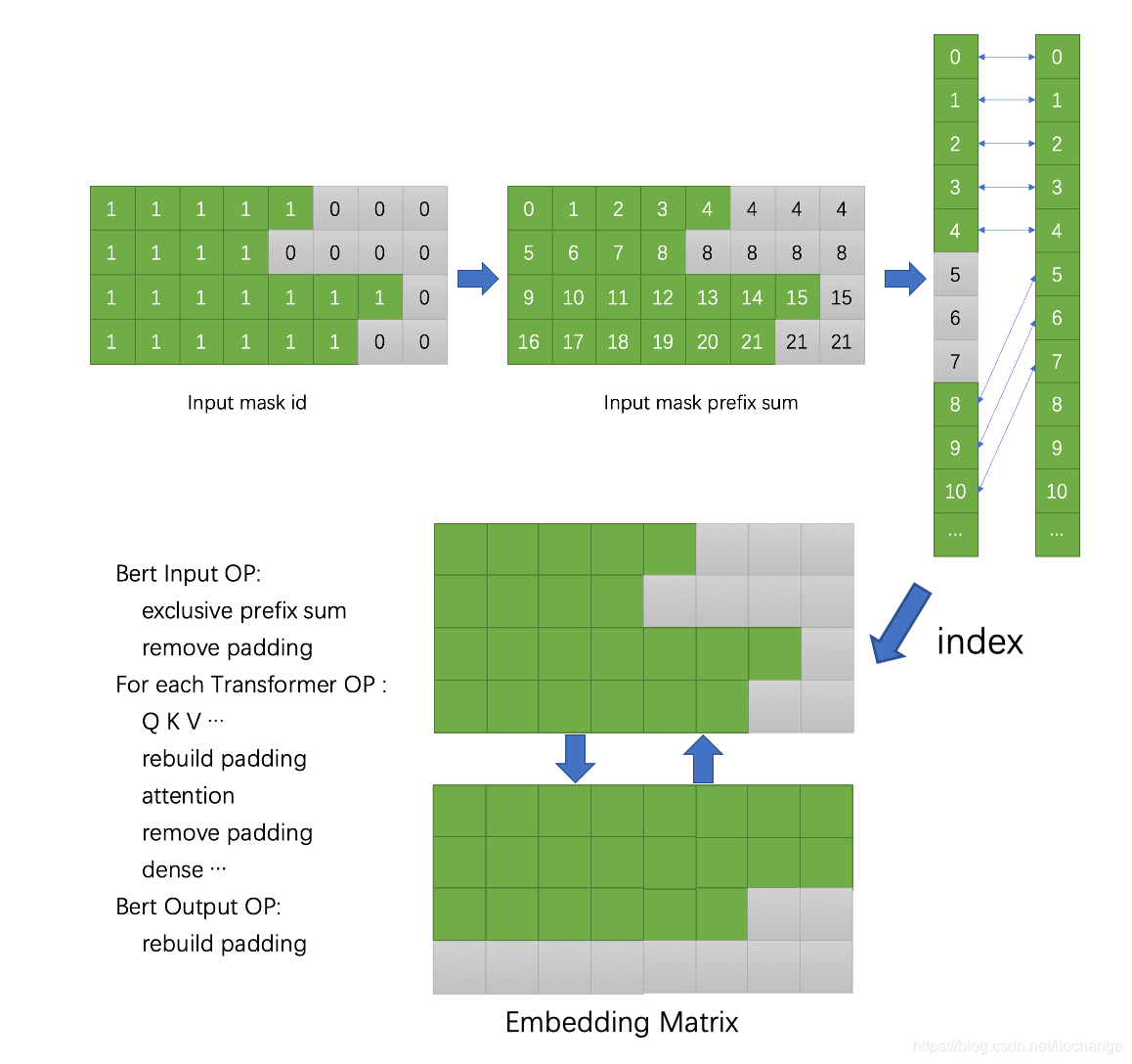
transformer模型在self-attention的时候,需要用到统一输入batch的长度。但是其他模块不需要。因此,在其他模块(FF模块)可以移除pad token再进行计算,从而加快模型训练和测试的速度
对字节跳动 effective_transformermer的理解
transformer模型在self-attention的时候,需要用到统一输入batch的长度。但是其他模块不需要。因此,在其他模块(FF模块)可以移除pad token再进行计算,从而加快模型训练和测试的速度
 3816
3816











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言



























