







黑历史三
花了三四天的时间去搞排序,一开始的时候只是想写快排,然而和别人对比很慢,与sort对比更慢...于是心生不愤,开始研究sort
然后看着别人对sort源代码的分析(http://www.udpwork.com/item/12284.html),写了一个出来,嗯,性能和sort差不多了
然后问题又来了,在某种情况下,sort只需0.X秒,我那渣渣代码居然要30+秒,根本不是一个数量级....
然后又花了一天重写.....
结果:
1,阅读源码后,个人感觉就理论来说,sort已经是最接近nlogn底线的排序算法了,几乎没有提升的空间,即使有,也不会是我能想出来的。
2,于是,我想,如果转换成数组或指针排序,能不能快那么一点呢。
3,于是,我重写代码,用数组,指针代替迭代器,并且减少函数调用。
4,还是有一点成果的的,倒序数排序增幅有80%~120%(不知道为什么会这样),随机数排序有10%左右增幅。
5,主要是为了练习,有错误或改进请指出。
一个小小的sort排序,有很多很多的技巧,集合了堆排,快排,插入排序三种排序,不但加快了排序速度,而且在任何情况下复杂度都能接近nlogn。
首先,加入了递归深度限制,这个其实就是分治法递归树的高度,当超过这个限制时调用堆排,使快排无法恶化下去。
这个递归深度的值由排序规模N决定
inline int __lg(int n)
{
int k;
for (k = 0; n > 1; n >>= 1)
++k;
return k;
}首先,我们输入一个数组和数组规模
void QuickSort(int *a, int n)
{
Quick_Sort(a, 0, n, __lg(n) * 2);
}快排的枢纽采用三点取中值法
inline int MidValue(int &f, int &m, int &l)
{
if (f > m)
{
if (m > l) return m;
else return(f > l ? l : f);
}
else
{
if (f > l) return f;
else return(l > m ? m : l);
}
}分割采用了双端扫描,无需顾虑边界问题。
int Patition(int *a, int first, int last, int pivot)
{
while (true)
{
while (a[first] < pivot) ++first;
--last;
while (a[last] > pivot) --last;
if (!(first < last)) return first;
int e = a[first]; a[first] = a[last]; a[last] = e;
++first;
}
}然后用数值16(谁知道他们经过什么测验得出的数字.....)决定快排底线,当元素低于16就采用插排。
const int threshold = 16;void Quick_Sort(int *a, int first, int last, int depth_limit)
{
while (first + threshold < last)
{
if (depth_limit == 0)
{
partial_sort(&a[first], &a[last], &a[last]);
return;
}
--depth_limit;
int cut = Patition(a, first, last,
MidValue(a[first], a[(first + last) / 2], a[last - 1]));
Quick_Sort(a, cut, last, depth_limit);
last = cut;//这个其实就是尾递归....
}//以下是插排 if (first == 0)
{
int min = 0;
for (int i = 1; i < last; ++i)
min = a[i] < a[min] ? i : min;
swap(a[0], a[min]);
}
for (int i = first + 1; i < last; ++i)
Unguarded_Iinear_Insert(&a[i], a[i]);
}有趣的是,插排采用了unguarded思想,不用考虑边界问题,减少比较次数,加快了速度。具体请看(http://www.udpwork.com/item/12284.html)
首先,我们的快排把元素分为若干个小于或等于16的小区间,而且每个小区间递增
所以我们用插排排序小区间时,有两种情况,
1,普通的小区间,每一个元素都比上一个小区间的任意一个元素大,所以我们根本不用考虑边界问题,直接对比插入。
2,最左边(第一个)小区间,这个比较特殊,因为它没有上一个区间,所以我们需要找出这个小区间里的最小值,与第一个元素a[0]调换,然后就能不顾虑边界插排。
Unguarded_Iinear_Insert实现代码
void Unguarded_Iinear_Insert(int *last, int value)
{
int *next = last;
--next;
while (value < *next)
{
*last = *next; last = next; --next;
}
*last = value;
}(end)
接下来就是与sort战个痛快:
首先是5000万个随机int型数排序:
先上手写排序
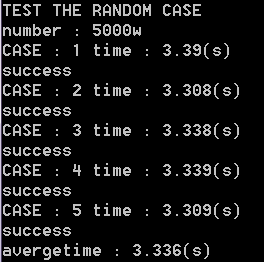
然后上我们的sort
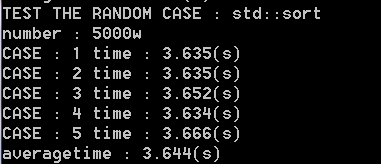
然后是倒序数排序,手写居然快很多,原因不明...
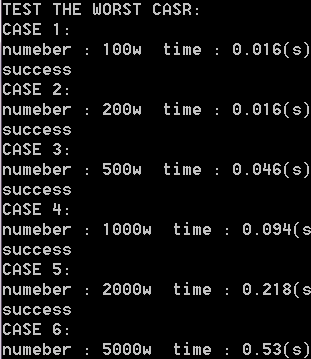

语死早,写得不好不要打我。
(全文完)














 998
998











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









