







时间复杂度和空间复杂度
常数操作:
-
固定时间的操作,执行时间和数据量无关
-
位运算 > 算数运算 > 寻址 > 哈希运算,都是常数操作,哈希运算操作时间最慢
-
链表的get(i)方法不是常数操作,因为链表不是连续的存储空间,靠着指针链接着,要靠头节点一个个的往下查,是一定要查找这么多个数的
-
例如:
int a=3, b=5相加的时间和int a=3000万,b=20亿相加的时间差不多寻址中拿到a[1007]和a[1007万]时间也是差不多,因为是靠偏移量来查找的
时间复杂度:
- 一个和数据量有关、只要高阶项、不要低价项、不要常数项的操作次数的表达式
O(...)表示趋向那个级别的规模- 忽略常数项原因:当N->无穷时常数项已经不重要了,例如:
y = x^2, y = k*x,无论K多大,最终x^2的曲线最终会超过k*N的直线 - 忽略低价项的原因:影响整体级别的规模是高阶项
- 选择排序,是
(0~N-1),到(1~N-1),再到(2~N-1)等,所以是N+(N-1)+(N-2)+(N-3)+...+1,这是一个等差数列,首项是1,公差是1,因为只要高阶项,所以时间复杂度是O(n^2),冒泡排序也类似
等差数列求和公式:
S = n / 2 * (2 * a1 + (n - 1) * d)其中,S是等差数列的和;n是项数;a1是首项;d是公差。
也可以认为任何等差数列的都符合:
a * n^2 + b * n + c,其中a、b、c都是常数
- 严格固定流程的算法,一定要强调最差情况!比如插入排序
- 算法流程上利用随机行为作为重要部分的,要看平均或者期望的时间复杂度,因为最差的时间复杂度无意义,比如:生成相邻值不同的数组,从
[0~3]之间中随机出来,组成相邻值不同的数组,单次随机为O(1),最差情况为O(无穷)当数组第一个数是1,后面一直随机出来是1那就无法形成符合要求的数组,则获取出来的时间复杂度无意义。这期望的时间复杂度是O(n)。、 - 时间复杂度的内涵:描述算法运行时间和数据量大小的关系,而且当数据量很大很大时,这种关系相当的本质,并且排除了低价项、常数时间的干扰
空间复杂度:
- 强调额外空间;常数项时间,放弃理论分析、选择用实验来确定,因为不同常数操作的时间不同
- 与入参和出参的空间无关,比如:通过设计一个算法完成这个功能,如果没有申请额外的空间去进行操作,则空间复杂度为
O(1),如果申请了一个长度为N的辅助数组,则则空间复杂度为O(N)
最优解:
- 先满足时间复杂度最优,然后尽量少用空间的解
时间复杂度的均摊:
-
涉及动态数组,先申请一个固定大小的数组,当数组不够用时,再申请一个相应倍数的数组,把旧数组中的值拷贝到旧数组中,一共加入了N个数总代价,单次调用是
O(1)

-
因为一次扩容后可能很久不会再扩容了,每次都计算整体的复杂度太麻烦就把每次扩容能分摊到的时间复杂度进行计算,看整个过程调用了多少次来估计整体的时间复杂度
-
把每一个单次操作理解为常数操作,就可以好估计这个函数的时间复杂度
-
并查集、单调队列、单调栈、哈希表等结构,均有这个概念
分析复杂度常见的错误:
-
不要用代码结构来判断时间复杂度,通过两个for循环嵌套就说是时间复杂度是O(N^2)是错误的
-
比如只有一个while的循环的冒泡排序,其实时间复杂度是
O(N^2)// 只用一个循环完成冒泡排序 // 但这是时间复杂度O(N^2)的! public static void bubbleSort(int[] arr){ if (arr == null || arr.length < 2) { return; } int n = arr.length; int end = n - , i = 0; while (end > 0) { if (arr[i] > arr[i + 1]) { swap(arr, i, i + 1); } if (i < end - 1){ i++; } else{ end--; i = 0; } } } // 数字中交换i和j位置的数 public static void swap(int[] arr, int i, int j){ int temp = arr[i]; arr[i] = arr[j]; arr[j] = temp; } -
比如:
N/1 + N/2 + N/3 + ... + N/N,这个流程的时间复杂度是O(N * logN),著名的调和级数for (int i = 1; i <= N; i++) { for (int j = i; j <= N; j += i) { // 这两个嵌套for循环的流程,时间复杂度为O(N * logN) // 1/1 + 1/2 + 1/3 + 1/4 + 1/5 + ... + 1/n,也叫“调和级数”,收敛于O(logN) // 所以如果一个流程的表达式:n/1 + n/2 + n/3 + ... n/n // 那么这个流程时间复杂度O(N * logN) } }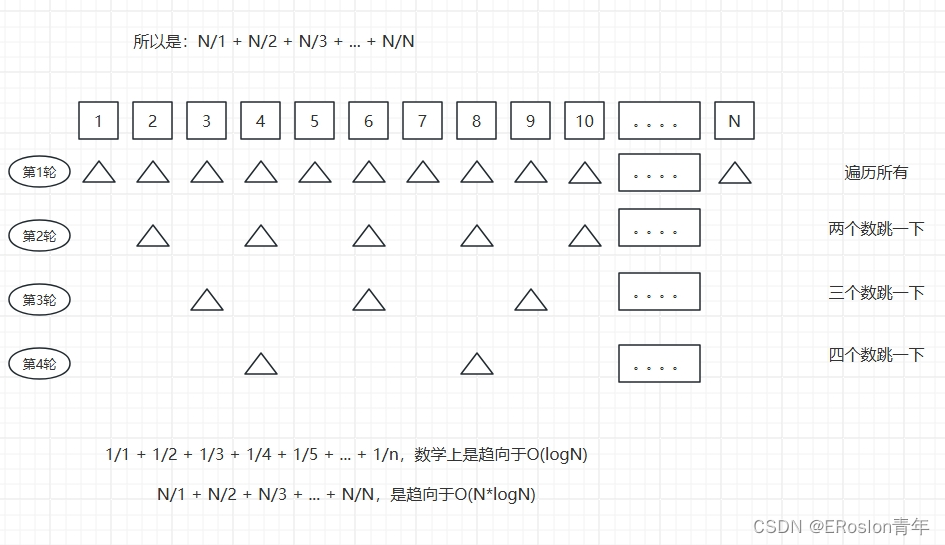
-
时间复杂度只能是对算法流程充分理解才能分析出来,而不是简单的看代码结构!这个是一个常见的错误!甚至有些算法的实现用了多层循环嵌套,但时间复杂度是
O(N)的
常见复杂度一览:
O(1) O(logN) O(N) O(N*logN) O(N^2) ... O(N^K) O(2^N) ... O(K^N) ... O(N!)- 时间复杂度非常重要,可以直接判断某个方法能不能通过一个题目,根据数据量猜解法。















 2580
2580











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









