







目录
1、multiprocessing多进程模块
1)使用进程池pool:
- pool( )类:指定进程池中同时执行的进程数为8,当一个进程执行完毕后,如果还有新进程等待执行,则会将其添加进去。

- pool.apply_async( ):为非阻塞,即不用等待当前运行的子进程执行完毕(各子进程并行执行,且主进程与子进程之间、各子进程之间都不会互相等待),随时根据系统调度来进行进程切换。
- pool.apply( ):阻塞型,各子进程需依次执行,主进程会被阻塞直到函数执行结束
- 多进程执行过程中,子进程出错时,将直接跳出,执行主进程,且不会报错
- 主进程向子进程传递的参数不可以为类实例、导入的模块等(linux不可,windows则可以传递类实例);且注意传递的参数尽量不要太大(如大的模型、大的数据集),否则会占用很大内存,严重影响速度。
- 启动子进程的方式有三种:fork、spawn、forkserver,不同的方式会涉及主进程向子进程的参数传递问题,具体解释和区别可以参考https://www.cnblogs.com/devilmaycry812839668/p/16982843.html
(1)可以借助循环,为同一个目标函数传递不同的参数

(2)可以借助循环,多进程执行不同的目标函数
import multiprocessing
pool = multiprocessing.Pool(3)
result = []
for i in range(3):
if i ==0:
pool.apply_async(func=func_classify,args=(port_id, db_name, paper_name,))
elif i==1:
pool.apply_async(func=func_yjd,args=(port_id, db_name, paper_name,))
elif i==2:
pool.apply_async(func=func_senseDeal,args=(port_id, db_name, paper_name, tick_list,))
pool.close()
pool.join()
pool.close() 关闭pool,使其不再接受新的任务。
pool.terminate() 结束工作进程,不再处理未完成的任务。
pool.join() 主进程(main)阻塞,等待子进程的退出(防止子进程没有执行完,主进程就已经执行完毕并退出程序),要在close或terminate之后使用。
2)多进程写同一个list/dict
import time
import multiprocessing as mp
class a:
def __init__(self) -> None:
self.manager = mp.Manager
self.mp_lst = self.manager().list() # 关键在于对list、dict的定义,换成[]、{}则最终打印出来的结果为空
self.mp_dict = self.manager().dict()
def proc_func(self,i, j):
self.mp_lst.append(i)
self.mp_dict[i] = j
time.sleep(0.1)
def flow(self):
pool = mp.Pool(9)
for i in range(20):
pool.apply_async(self.proc_func, args=(i, i*2))
pool.close()
pool.join()
if __name__ =='__main__':
p = a()
p.flow()
print(p.mp_lst)
3)不使用进程池:
multiprocessing.Process( ):执行过程(这种方式与Threading线程模块使用类似)

2、threading多线程模块
import threading
from threading import Lock, RLock
import time
- 线程之间比进程之间的隔离程度要小,他们共享内存、文件句柄等。(同一进程中的多线程共享资源);
- python中,多线程并不能真正的并行执行(尤其是涉及复杂计算的过程,I/O过程相对好一些),无法通过多线程提升处理速度;(由于 GIL (CPython 解释器)的存在,多个线程不能够真正并行执行。对于 CPU 密集型任务,这可能导致性能瓶颈,因为在任何时刻只有一个线程能够利用 CPU)
1)直接调用Thread()类
设6个多线程并发执行:

参数:
- target 是被 run()方法(在start方法中)调用的回调对象. 默认应为None, 意味着没有对象被调用。
- args是目标调用参数的tuple,默认为空元组(),如果只有一个参数也需要在末尾加逗号。
- name 为线程名字。默认形式为’Thread-N’的唯一的名字被创建,其中N 是比较小的十进制数。
注意:
(1).join()设置线程阻塞(类似于pool.join())。
import threading
import time
def p(i):
print(i)
time.sleep(10)
def tt():
cur = 0
start= time.time()
while cur<10:
for i in range(cur, cur+4):
if cur == 10:
break
thrd = threading.Thread(target=p, args=(i,))
thrd.start()
cur += 1
print('mm')
thrd.join() # 此处阻塞主线程之后的操作,即所有子线程都执行完之后,才开始运行该语句之后的操作
end= time.time()
print(end-start) # 用时10.01928186416626s,join语句放在start之后的话,用时100.08447313308716s
print('over')
(2)加互斥锁:
- 当资源不允许多个线程并行操作时,对该资源添加互斥锁。(此外还有一种递归锁RLock())
- A线程处理不可并行操作的共享资源时,得到了lock,并添加到该资源上,B线程同时要处理该资源时,需要等待A释放该lock。
lock=threading.Lock()
lock.acquire()
lock.release()
2)自定义线程类
即继承threading.Thread类,重写其中的run()方法:
(1)自定义代码示例:
import time
def myFunc(n):
print('这是我的函数', n)
class myThread(threading.Thread):
def __init__(self, num, target=None, args=None):
super(myThread,self).__init__()
self.num=num
self.num+=1
self.target=target
self.args=args
def run(self):
time.sleep(2)
print('这是线程-'+str(self.num))
time.sleep(0.5)
if self.target:
self.target(*self.args)
for i in range(3):
t=myThread(i, target=myFunc, args=(i,))
# t.setDaemon(True) #把子线程设置为守护线程(主线程结束后,子线程也将立即结束),必须在start()之前设置
t.start()
t.join() # 设置主线程等待子线程结束
结果:(第一个如没有加入t.join()的结果;第二个图加入时的结果)

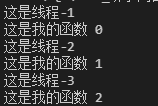
3、设置守护进程,实现超时进程的处理/中止
示例:
- 主进程中使用进程池设置3个子进程,每个子进程调用定义了“守护进程”的my_daemon();
- “守护进程”中通过定义1个子线程调用执行函数my_func(),并使用get(timeout)方法,子线程执行时间超过timeout后则直接中止。
def my_func(m):
print(m)
if m%2==0:
time.sleep(10)
else:
time.sleep(2)
print('进程号执行完毕:', os.getpid())
def my_daemon(n, timeout):
# 守护进程
thrd_pool = ThreadPool(1)
print('当前进程号:', os.getpid())
res = thrd_pool.apply_async(my_func, args=(n,))
try:
out = res.get(timeout) # Wait timeout seconds for func to complete.
return out
except multiprocessing.TimeoutError as e:
print('Aborting due to timeout进程号中止:', os.getpid())
def multi_trd():
timeout=4
cur = 0
start= time.time()
pool = multiprocessing.Pool(3) # maxtasksperchild=1参数会使得每个进程仅处理一个任务,执行完后回收,再创建新的进程,每次进程号均不同,且在这个例子中总用时比不加该参数多1秒
for i in range(10):
pool.apply_async(my_daemon, args=(i, timeout,))
print('mm')
pool.close()
pool.join()
end= time.time()
print(end-start)
print('over')
4、async/await同步与异步
- 示例参考:https://blog.csdn.net/qq_43380180/article/details/111573642
- 定义函数时加上async修饰即为协程函数(异步函数),执行该函数得到协程对象,其内部代码不会执行;
- 异步函数的特点是能在函数执行过程中挂起,去执行其他异步函数b(),等到挂起条件(使用await修饰,如await asyncio.sleep(5))消失后,也就是5秒到了,不管b()执行是否结束,再回来执行。
- await + 可等待对象(协程对象/异步函数,Future,Task对象(IO等待)),等待到对象的返回结果后,才会继续执行后续代码
- 将协程添加到asyncio.create_task()中,则该协程将很快的自动计划运行(create_task()中的所有task会同时执行)
import asyncio
import time
async def say_after(delay, what):
await asyncio.sleep(delay)
print(what)
async def main():
print(f"started at {time.strftime('%X')}")
await say_after(1, 'hello')
#await say_after(1, 'hello')执行完之后,才继续向下执行
time.sleep(3)
await say_after(2, 'world')
print(f"finished at {time.strftime('%X')}")
task1 = asyncio.create_task(
say_after(1, 'hello'))
task2 = asyncio.create_task(
say_after(2, 'world'))
# task1、task2两个任务同时执行,主程序会等待所有task执行完,然后结束。(下面耗时为啥4秒??!)
await task1
time.sleep(3)
print('oo')
await task2
print(f"finished at {time.strftime('%X')}")
print(main()) # <coroutine object main at 0x1053bb7c8>, 执行该函数得到协程对象,其内部代码不会执行
asyncio.run(main())
结果:
<coroutine object main at 0x000001AB6BDF3680>
e:\CQF\work_yanxue\AI_yanxue\LLM\mycode\tt.py:52: RuntimeWarning: coroutine ‘main’ was never awaited
print(main()) # <coroutine object main at 0x1053bb7c8>, 执行该函数得到协程对象,其内部代码不会执行
RuntimeWarning: Enable tracemalloc to get the object allocation traceback
started at 16:09:43
hello
world
finished at 16:09:49
hello
oo
world
finished at 16:09:53
















 529
529











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









