







2018.11.23
上一篇采用 Selenium 和 Ajax 参数分析两种方法来爬取了基金信息。链接:
https://blog.csdn.net/luckycdy/article/details/84342640
本篇介绍更快、更强的工具-Scrapy 框架!
爬虫要求:
目标 url:http://gs.amac.org.cn/amac-infodisc/res/pof/fund/index.html
抓取信息:每条基金的 基金名称 私募基金管理人名称 托管人名称 成立时间 备案时间 以及 运作状态 基金信息最后更新时间。
即将下图中的基金名称每一条都点进去
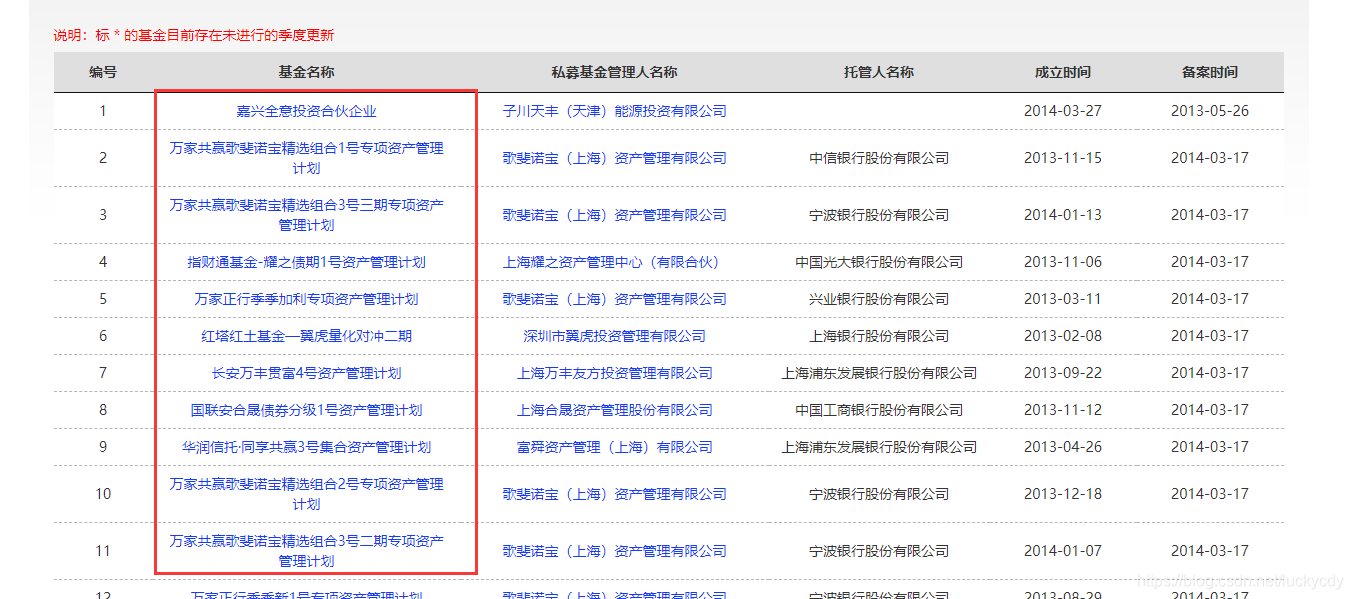
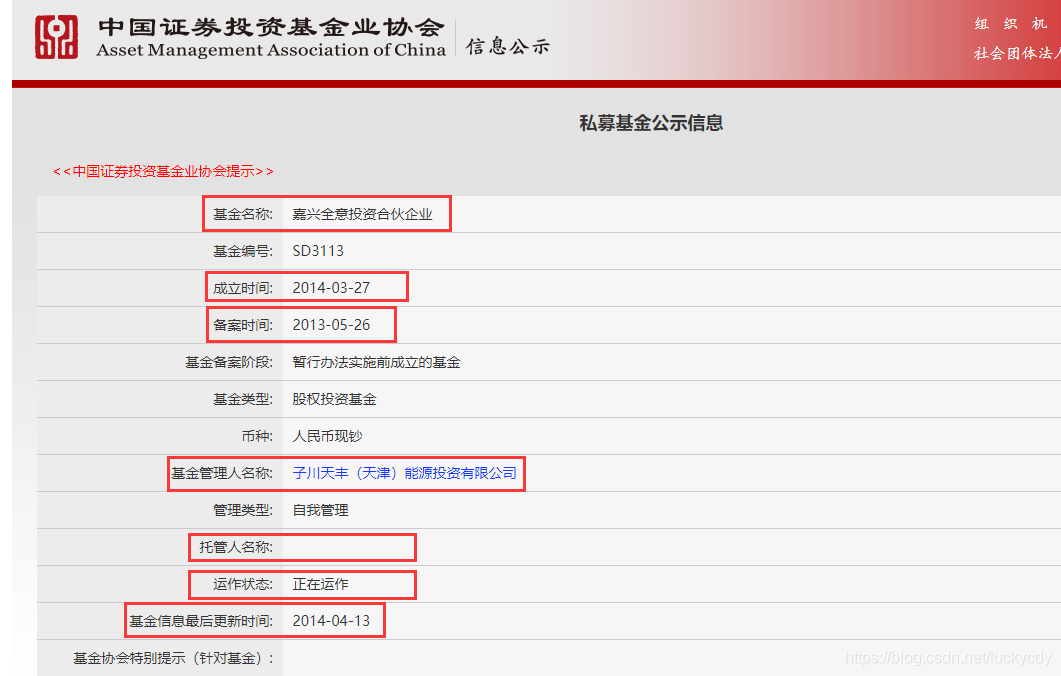
点进具体链接后,抓取每条基金的如下信息:
一、环境 & 安装工具:
在安装好 Anaconda 的前提下,再进行安装 Scrapy:
在 Anaconda 控制台(Anaconda Prompt)中输入 conda install scrapy ,在安装过程中,是否安装所需要的框架,选择是(输入 y)。
验证:在控制台中输入 python 进入 Python,然后输入import scrapy,不报错,即说明 Scrapy 安装成功。
二、分析:
如上一篇所述,我们发现在目标 URL 中,所解析出来的 json 数据中不包含 ‘运作状态’ 这一项,只能在点进去具体 url 后,才会有该信息。
思路:我们可以先爬取目标url第一页(http://gs.amac.org.cn/amac-infodisc/res/pof/fund/index.html ),从中解析出 100 个(即该页所显示的基金数目)具体基金的url(如第一个嘉兴全意投资合伙企业的链接:http://gs.amac.org.cn/amac-infodisc/res/pof/fund/351000133588.html ),将第一页的这 100 个 url 爬取并解析完后,再去爬取目标 url 的第二页。循环以上步骤,直到爬完 1000 页。
三、Scrapy 实战:
① 创建爬虫项目:
先新建一个文件夹,以后专门用来存放 Scrapy 项目,如 F:\Python\code\spider\scrapy(建议不带中文字符)。
打开 cmd(建议 win10 用户使用 Windows PowerShell),进入到该目录下,并运行命令 scrapy startproject 来创建一个名为 Fund 的 scrapy项目
cd F:\Python\code\spider\scrapy
scrapy startproject Fund
然后我们可以看到在该目录下生成了该项目的一些文件,这些文件后续会用到,暂时先不管。
我们继续进入到文件夹中的的 spider 文件夹下,来创建一个爬虫实例,名为 fund,域名为:gs.amac.org.cn
cd F:\Python\code\spider\scrapy\Fund\Fund\spiders
scrapy genspider fund gs.amac.org.cn
至此,我们就需要到各个文件中去修改代码来完成自己所需的功能了。
② 修改 spiders 文件夹下的 fund.py,此文件是用来存放爬虫的主体的,即解析用到的代码放在此处。
该文件中定义了一个类,名叫 FundSpider,并且继承了 Scrapy.Spider 类。它有一些默认参数:
name : 爬虫名称,该名称是你在 cmd 中最后所想要运行的爬虫的名称,且不能与其他爬虫名称重复。
allowed_domains:允许的域范围,该项可以不要。
start_urls:存放初始链接的列表。该项也可以不要。
以及一个解析函数 parse(self,response),该函数有一个参数 response,是爬虫请求 start_urls 中的链接生成的响应。该函数也可以根据自己要求自行修改、新增。
将该类进行修改:
①因为是 Ajax 的 Post payload 数据,所以要将爬虫的请求头进行修改,我们这里采用简单的,直接在爬虫的类中进行对 headers 的定义。
②工作流程:先爬取整体列表页面,解析出需要爬取的信息页面的 url,然后再爬取信息页面,最后进行数据的处理。
遇到的坑:
①headers 全部复制成与网页一致,会出错,需要删减。
②post 的 payload 数据,原本的int 类型需要改成字符串
③post 的 poyload 数据为空时,即{},直接 body = '{}'就行,不需要进行 json 格式化。
④最好不要在 scrapy 中用 requests 库,会产生较多阻塞。
⑤request 返回的数据格式是 textResponse 类型,没有 response.json()的形式,需要写成 json.loads(response.body_as_unicode())。
2018.12.03
爬虫部分代码如下:
# -*- coding: utf-8 -*-
import scrapy
import json
# from scrapy.spider import CrawlSpider
from Fund.items import FundItem
class FundSpider(scrapy.Spider):
name = 'fund' #爬虫名称
# headers = { # 请求头,
# 'Accept': 'application/json, text/javascript, */*; q=0.01',
# 'Accept-Encoding': 'gzip, deflate',
# 'Accept-Language': 'zh-CN,zh;q=0.9',
# 'Cache-Control':'max-age=0',
# 'Connection': 'keep-alive',
# 'Content-Length': '2',
# 'Content-Type': 'application/json',
# 'Host': 'gs.amac.org.cn',
# 'Origin': 'http://gs.amac.org.cn',
# 'Referer': 'http://gs.amac.org.cn/amac-infodisc/res/pof/fund/index.html',
# 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36',
# 'X-Requested-With': 'XMLHttpRequest'
# }
headers = { # 请求头
"Host": "gs.amac.org.cn",
"Accept": "application/json, text/javascript, */*; q=0.01",
"Origin": "http://gs.amac.org.cn",
"X-Requested-With": "XMLHttpRequest",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36",
"Content-Type": "application/json",
"Referer": "http://gs.amac.org.cn/amac-infodisc/res/pof/fund/index.html",
"Accept-Language": "zh-CN,zh;q=0.9",
}
max_page = 2 # 需要爬取的页数
temp_page = 0 # 爬取第x页
base_url2 ='http://gs.amac.org.cn/amac-infodisc/res/pof/fund/' # 具体信息页的链接前半段
urls = [f'http://gs.amac.org.cn/amac-infodisc/api/pof/fund?rand=0.03238375864053089&page={page}&size=100' for page in range(max_page)] # 列表页 url
def start_requests(self):
'''
爬虫发起的第一个请求
'''
yield scrapy.Request(
self.urls[0],
method="POST",
headers=self.headers,
body="{}",
callback=self.parse,
dont_filter=True
)
def parse(self,response):
response = json.loads(response.body_as_unicode())
for num in range(100):
url2 = self.base_url2 + response.get('content')[num].get('url')
yield scrapy.Request(url2,callback=self.info_parse) # 发起 request 请求,并进入回调函数
self.temp_page += 1 # 爬取第 x 页
if self.temp_page < self.max_page:
yield scrapy.Request(
self.urls[self.temp_page],
method="POST",
headers=self.headers,
body="{}",
callback=self.parse,
dont_filter=True # 防止 scrapy 对该 url 去重
)
def info_parse(self,response):
item = FundItem() # 实例化一个 item
item['name'] = response.xpath('/html/body/div[1]/div[2]/div/table/tbody/tr[1]/td[2]/text()').extract_first()
item['manager'] = response.xpath('/html/body/div[1]/div[2]/div/table/tbody/tr[8]/td[2]/a/text()').extract_first()
item['people'] = response.xpath('/html/body/div[1]/div[2]/div/table/tbody/tr[10]/td[2]/text()').extract_first()
item['time1'] = response.xpath('/html/body/div[1]/div[2]/div/table/tbody/tr[3]/td[2]/text()').extract_first()
item['time2'] = response.xpath('/html/body/div[1]/div[2]/div/table/tbody/tr[4]/td[2]/text()').extract_first()
item['state'] = response.xpath('/html/body/div[1]/div[2]/div/table/tbody/tr[11]/td[2]/text()').extract_first()
item['time3'] = response.xpath('/html/body/div[1]/div[2]/div/table/tbody/tr[12]/td[2]/text()').extract_first()
yield item
2018.12.04
以上代码有提到 FundItem 类,该类是文件 items.py 中的。该文件主要涉及 scrapy 的需要处理的数据。
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class FundItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
num = scrapy.Field()
name = scrapy.Field()
manager = scrapy.Field()
people = scrapy.Field()
time1 = scrapy.Field()
time2 = scrapy.Field()
state = scrapy.Field()
time3 = scrapy.Field()
接下来还需要进行对数据进行保存,这里简单保存为 json 格式即可。使用 pipelines.py 文件。
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
from scrapy.exporters import JsonItemExporter
class FundPipeline(object):
def __init__(self):
# x = 'F:\Python\code\spider\scrapy\Fund\Fund\url.json'
self.file = open('url.json', 'wb')
self.exporter = JsonItemExporter(self.file, encoding="utf-8", ensure_ascii=False)
self.exporter.start_exporting()
def close_spider(self, spider):
'''爬虫结束时运行,结束传输,关闭文件'''
self.exporter.finish_exporting()
self.file.close()
def process_item(self, item, spider):
self.exporter.export_item(item)
return item
使用该文件需要提前在 settings.py 中打开。其中我主要修改了爬虫的 robots 协议,开启线程数量,打开 pipeline。
BOT_NAME = 'Fund'
SPIDER_MODULES = ['Fund.spiders']
NEWSPIDER_MODULE = 'Fund.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'Fund (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Configure maximum concurrent requests performed by Scrapy (default: 16)
CONCURRENT_REQUESTS = 16
ITEM_PIPELINES = {
'Fund.pipelines.FundPipeline': 300,
}
以上 4 个文件修改完后,记得保存,然后在 cmd 中(cd 到 spiders 目录下)输入scrapy crawl fund,运行爬虫,即可保存完成爬取,保存文件。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









