







k-近邻算法(KNN)
KNN一种可以用于分类和回归任务的算法,KNN隐藏着强大的功能和高可用性,该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
k-近邻模型
度量空间是定义了集合中所有成员之间距离的特征空间。超参k用来指定估计过程应该包含多少个邻居。超参是用来控制算法如何学习的参数,它不通过训练数据来估计,一般需要人为指定,最后通过某种距离函数,从度量空间选出k个距离测试实例最近邻居。
二元分类
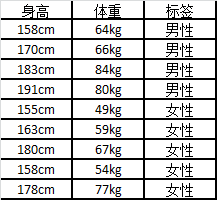
#In[1]
import numpy as np
import matplotlib.pyplot as plt
X_train=np.array([
[158,64],
[170,86],
[183,84],
[191,80],
[155,49],
[163,59],
[180,67],
[158,54],
[170,67]
])
y_train=['male','male','male','male','female','female','female','female','female']
plt.figure()
plt.title('Human Heights and Weights by Sex')
plt.xlabel('Height in cm')
plt.ylabel('Weight in 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1439
1439











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









