









矩阵分解模型做如下假设:
1.每个用户可描述为n个属性或特征。比如,第一个特征可以对应某个用户对动作片的喜好程度。
2.每个物品可描述为n个属性或特征。比如,接上一点,第一个特征可以用对应某部电影与动作片的接近程度。
3.将用户和物品对应的属性相乘后求和,该值可能很接近用户会对该物品的评级。
1.显式矩阵分解
当要处理的数据是由用户所提供的自身的偏好数据时,这些数据被称作显式偏好数据。这类数据包括如物品评级、赞、喜欢等用户对物品的评价。
这些数据大都可以转换用户为行、物品为列的二维矩阵。矩阵的每一个数据表示为某个用户对特定物品的偏好。大部分情况下用户只会和少数物品接触,所以该矩阵只有少部分数据非零,即该矩阵很稀疏。
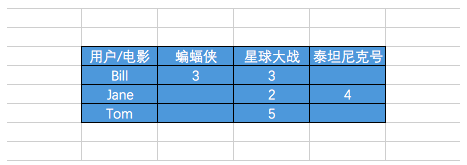
对这个矩阵分解,找到他的两个低阶矩阵。假设我们的用户和物品数目分别是U和I,那对应的“用户-物品”矩阵的维度为U*I。那对应的两个低阶矩阵分别是用户的U*k矩阵,和物品的I*k矩阵。这两个矩阵也被称为因子矩阵。因子矩阵通常是稠密的。
由于对“用户-物品”矩阵直接建模,用这些模型进行预测也相对直接:要计算给定用户对某个物品的预计评级,就从用户因子矩阵和物品因子矩阵分别选取相应的行(用户因子向量)与列(物品因子向量),然后计算两者的点积即可。
而对于物品之间相似度的计算,可以直接用物品矩阵中的因子向量做相似度计算。
因子分解类模型的的利弊:
利:求解容易,表现出色
弊:不好解释,吃资源(因子向量多,训练阶段计算量大)
2.隐式矩阵分解
隐式矩阵就是针对隐式反馈数据。在这类数据中,用户对物品的偏好不会直接给出,而是隐含在用户与物品的交互之中。二元数据(比如用户是否观看了某部电影或是否购买了某个商品)和计数数据(比如用户观看某部电影的次数)便是这类数据。
处理隐式数据的方法相当多。SparkMllib实现了一个特定的方法。它将输入的评级数据视为两个矩阵:一个二元偏好矩阵P和一个信心权重矩阵C。
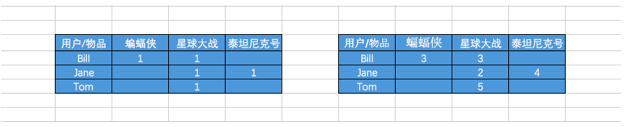
隐式模型仍然会创建一个用户因子矩阵和一个物品因子矩阵。但是,模型所求解的是偏好矩阵而非评级矩阵的近似。
从根本上说,矩阵分解从评级情况,将用户和物品表示为因子向量。若用户和物品因子之间高度重合,则可表示这是一个好推荐。两种主要的数据类型为显示反馈和隐式反馈,其中前者比如评级(用稀疏矩阵表示),后者比如购物历史、搜索记录、浏览历史和点击数据(用密集矩阵表示)。














 1248
1248











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









