






1.KNN算法概述
KNN(K-NearestNeighbor)算法的基本法则是:相同类别的样本之间在特征空间中应当聚集在一起,换一种方式说就是未标记的样本的类别由距离其最近的k个邻居决定。KNN算法可解决分类或者回归问题。KNN是通过测量不同特征值之间的距离进行分类,而且在决策样本类别时,只参考样本周围k个“邻居”样本的所属类别。因此比较适合处理样本集存在较多重叠的场景,主要用于聚类分析、预测分析、文本分类、降维等,也常被认为是简单数据挖掘算法的分类技术之一。
KNN算法核心思想如此简单,只需要找到离未知点最近的k个点就可以判定其类别,或许有同学会问那其相较于现在的较为复杂的算法比如卷积神经网络有何优势呢,在此我想提出一个观点:算法没有绝对的好坏,我们能根据问题的特点找到其适用的算法,才能发挥出每个算法的优势,提高解决问题的效率。
2.背景知识
2.1 K的取值
K值得选取非常重要,因为:如果当K的取值过小时,一旦有噪声得成分存在们将会对预测产生比较大影响,例如取K值为1时,一旦最近的一个点是噪声,那么就会出现偏差,K值的减小就意味着整体模型变得复杂,容易发生过拟合;如果K的值取的过大时,就相当于用较大邻域中的训练实例进行预测,学习的近似误差会增大。这时与输入目标点较远实例也会对预测起作用,使预测发生错误。K值的增大就意味着整体的模型变得简单;如果K==N的时候,那么就是取全部的实例,即为取实例中某分类下最多的点,就对预测没有什么实际的意义了;K的取值尽量要取奇数,以保证在计算结果最后会产生一个较多的类别,如果取偶数可能会产生相等的情况,不利于预测。
常用的方法是从k=1开始,使用检验集估计分类器的误差率。重复该过程,每次K增值1,允许增加一个近邻。选取产生最小误差率的K。一般k的取值不超过20,上限是n的开方,随着数据集的增大,K的值也要增大。
2.2 距离度量
曼哈顿距离

hamming距离


3.实例
接下来举一个例子,更加直观地了解knn算法
假设集美大学计算机工程学院的同学都和我一样热爱学习和运动,课后(晚上)不是在图书馆学习就是在操场运动,而同学们在操场还是在图书馆取决于天气的话,我们就可以根据庄重文操场的人数和陈延奎图书馆的人数之比来判断当天天气是晴、雨还是多云。
| 日期 | 庄重文操场人数 | 陈延奎图书馆人数 | 天气 |
| 10.25 | 700 | 500 | 多云 |
| 10.26 | 750 | 460 | 多云 |
| 10.27 | 1000 | 230 | 晴 |
| 10.28 | 800 | 420 | 多云 |
| 10.29 | 690 | 500 | 多云 |
| 10.30 | 730 | 490 | 多云 |
| 10.31 | 60 | 1200 | 雨 |
| 11.1 | 80 | 1100 | 雨 |
| 11.2 | 1260 | 200 | 晴 |
| 11.3 | 240 | 1200 | 雨 |
| 11.4 | 200 | 1090 | 雨 |
| 11.5 | 1200 | 200 | 晴 |
| 11.6 | 900 | 320 | 晴 |
| 11.7 | 97 | 1170 | 雨 |
| 11.8 | 118 | 1108 | 雨 |
| 11.9 | 1203 | 200 | 晴 |
| 11.10 | 1180 | 88 | 晴 |
| 11.11 | 1111 | 99 | 晴 |
| 11.12 | 67 | 1222 | 雨 |
上表便是我们的数据集,即训练样本。该样本的特征有两个:1.庄重文操场人数2.陈延奎图书馆人数。在上表中还有每个日期的天气情况,即分类标签。

我们在这里用曼哈顿距离公式计算未知点与其他六个点的距离:
def classify0(inX, dataSet, labels, k):
# numpy函数shape[0]返回dataSet的行数
dataSetSize = dataSet.shape[0]
# 在列向量方向上重复inX共1次(横向),行向量方向上重复inX共dataSetSize次(纵向)
diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet
# 二维特征相减后取绝对值
sqDiffMat = abs(diffMat)
# sum()所有元素相加,sum(0)列相加,sum(1)行相加
sqDistances = sqDiffMat.sum(axis=1)
print("曼哈顿距离分别为",sqDistances)运行结果:

(800,400)和10.25(700,500)的距离是:200
(800,400)和10.26(750,460)的距离是:110
(800,400)和10.27(1000,230)的距离是:370
(800,400)和10.28(800,420)的距离是:20
(800,400)和10.29(690,500)的距离是:210
(800,400)和10.30(730,490)的距离是:160
(800,400)和10.31(60,1200)的距离是:1540
(800,400)和11.1(80,1100)的距离是:1420
(800,400)和11.2(1260,200)的距离是:660
(800,400)和11.3(240,1200)的距离是:1360
(800,400)和11.4(200,1090)的距离是:1290
(800,400)和11.5(1200,200)的距离是:600
(800,400)和11.6(900,320)的距离是:180
(800,400)和11.7(97,1170)的距离是:1473
(800,400)和11.8(118,1108)的距离是:1390
(800,400)和11.9(1203,200)的距离是:603
(800,400)和11.10(1180,88)的距离是:692
(800,400)和11.11(1111,99)的距离是:612
(800,400)和11.12(67,1222)的距离是:1555
3.1 该实例的python代码实现:
1.准备训练集
import numpy as np
def createDataSet():
#19组二维特征
features = np.array([[700,500],[750,460],[1000,230],[800,420],[690,500],[730,490],[60,1200],[80,1100],[1260,200],[240,1200],[200,1090],[1200,200],[900,320],[97,1170],[118,1108],[1203,200],[1180,88],[1111,99],[67,1222]])
#19组特征的标签
labels = ['多云','多云','晴','多云','多云','多云','雨','雨','晴','雨','雨','晴','晴','雨','雨','晴','晴','晴','雨']
return features, labels
features,labels = createDataSet()
print(features,'\n',labels)运行结果如下:

2.KNN算法
import numpy as np
import operator
def createDataSet():
#19组二维特征
features = np.array([[700,500],[750,460],[1000,230],[800,420],[690,500],[730,490],[60,1200],[80,1100],[1260,200],[240,1200],[200,1090],[1200,200],[900,320],[97,1170],[118,1108],[1203,200],[1180,88],[1111,99],[67,1222]])
#19组特征的标签
labels = ['多云','多云','晴','多云','多云','多云','雨','雨','晴','雨','雨','晴','晴','雨','雨','晴','晴','晴','雨']
return features, labels
features,labels = createDataSet()
print(features,'\n',labels)
def classify0(inX, dataSet, labels, k):
# numpy函数shape[0]返回dataSet的行数
dataSetSize = dataSet.shape[0]
# 在列向量方向上重复inX共1次(横向),行向量方向上重复inX共dataSetSize次(纵向)
diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet
# 二维特征相减后取绝对值
sqDiffMat = abs(diffMat)
# sum()所有元素相加,sum(0)列相加,sum(1)行相加
sqDistances = sqDiffMat.sum(axis=1)
# 返回distances中元素从小到大排序后的索引值
sortedDistIndices = sqDistances.argsort()
# 定一个记录类别次数的字典
classCount = {}
for i in range(k):
# 取出前k个元素的类别
voteIlabel = labels[sortedDistIndices[i]]
# dict.get(key,default=None),字典的get()方法,返回指定键的值,如果值不在字典中返回默认值。
# 计算类别次数
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
# python3中用items()替换python2中的iteritems()
# key=operator.itemgetter(1)根据字典的值进行排序
# key=operator.itemgetter(0)根据字典的键进行排序
# reverse降序排序字典
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
# 返回次数最多的类别,即所要分类的类别
return sortedClassCount[0][0]
features,labels = createDataSet()
test = [800,400]
test_label = '多云'
for k in range(1,20):
test_class = classify0(test,features,labels,k)
print("预测类别:",test_class,"真实类别:",test_label,"k值:",k)

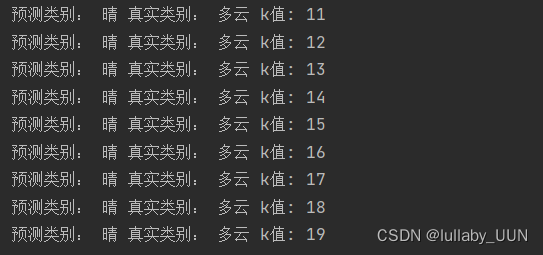
在该实例中,虽然测试集只有一个数据,我们也能够感受到k的不同取值对预测结果的影响。在该实例中,当k选取过大时候,会导致预测类别和真实类别不符合,也就是欠拟合。














 1042
1042











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









