







文章中的截图均来自李航老师的《统计学习方法》一书。
1.过拟合产生的原因以及造成的影响
统计学习有3个要素,模型、策略以及算法。给定一组数据集,需要通过模型对数据的分布进行拟合。先把原始的数据集划分为训练集、验证集和测试集,训练集用来对模型的参数进行更新,测试集用来衡量训练好的模型的性能。如果模型在训练集上的准确率很高、在测试集上的准确率很低,那么说明发生了过拟合,即模型对训练集拟合的过好了。造成的影响就是模型的泛化能力低,模型对于训练集以外的数据很难拟合。就相当于为了准备考试,使劲刷题,题库里(训练集)的题目都做对了,但是真正考试的时候(测试集)却得分很低,题库外的题就做不对了。
2.极大似然估计要解决一个什么问题呢
已知一系列的样本以及样本的符合某种概率分布函数,但是分布函数中的一些参数是未知的,通过这些样本来估计概率分布函数的未知的参数。
求解步骤:求似然函数的导数,对似然函数取对数并求导,令导数为0,目的是为了下溢出。
贝叶斯估计:就是待估计的参数的某些统计量是已知的,比如符合某种分布,相比较于极大似然估计,对待估计的参数又确定了一丢丢。
3.感知机是什么?应用场景是什么?假设空间是什么?
感知机是机器学习算法的基石,很基础也很简单。
感知机的只能从处理线性可分的问题,只能处理二分类问题。通过构造一个超平面,将样本分为两类。对于线性不可分的问题,感知机是没法处理的。
感知机的对偶形式会使得求解的过程大大地化简。
某个算法的对偶形式肯定可以将原来的算法的复杂度降低,或者说原来的问题是不可以求解的,使用对偶形式以后,问题可以变得求解了。
4.感知机原始形式以及python实现
4.1原始形式算法描述

4.2 原始形式Python代码实现
Input:[3,3,1],[4,3,1],[1,1,-1]三个样本点
Output:感知机分离超平面
初始值:
w
=
[
w
1
,
w
2
]
T
=
[
0
,
0
]
T
w=[w_1,w_2]^T=[0,0]^T
w=[w1,w2]T=[0,0]T; b=0;
η
=
1
\eta=1
η=1; epoch number = 10
## 感知机原始形式的求解 ##
import numpy as np
import pandas as pd
import time
if __name__ == '__main__':
# 建立训练集
time_start= time.time()
x1 = [3,3,1]
x2 = [4,3,1]
x3 = [1,1,-1]
data = np.array([x1,x2,x3]).reshape(3,-1)
x_image = data[:,:-1] # 获得训练集中的特征值
x_label = data[:,-1] # 获得训练集数据的标签值
# 参数初始化,w,b是需要进行梯度更新的
w = [0,0]
b = 0
lr = 1
# 训练周期
epoch = 10
for epoch_num in range(epoch):
for i in range(np.size(x_label)):
loss = x_label[i]*(np.dot(w,x_image[i]) + b) #计算该点是否被误分类,然后进行梯度下降
if loss <= 0:
w = w + lr*x_label[i]*x_image[i]
b = b+lr*x_label[i]
loss = 0
print('[Epoch num: %d] [W: %s] [b:%.4f]' % (epoch_num,str(w),b))
print('-----------------------------------------------')
time_end = time.time()
runing_time = time_end -time_start
print('Finised Training')
print('w:',w)
print('b:',b)
print('Running Time: %.5f s' % runing_time)
运行结果得到:

5 感知机对偶形式以及Python实现
5.1 对偶形式算法描述

5.2 对偶形式的Python代码实现
Input:[3,3,1],[4,3,1],[1,1,-1]三个样本点
Output:感知机分离超平面
初始值:
α
=
[
α
1
,
α
2
,
α
3
]
T
=
[
0
,
0
,
0
]
T
\alpha=[\alpha_1,\alpha_2,\alpha_3]^T=[0,0,0]^T
α=[α1,α2,α3]T=[0,0,0]T; b=0;
η
=
1
\eta=1
η=1; epoch number = 10
## 感知机对偶形式的求解 ##
import numpy as np
import pandas as pd
import time
if __name__ == '__main__':
# 建立训练集
time_start= time.time()
x1 = [3,3,1]
x2 = [4,3,1]
x3 = [1,1,-1]
data = np.array([x1,x2,x3]).reshape(3,-1)
x_image = data[:,:-1] # 获得训练集中的特征值
x_label = data[:,-1] # 获得训练集数据的标签值
gram = np.dot(x_image,x_image.T) # 计算gram矩阵
alpha = np.zeros(3)
print(alpha)
b = 0
lr = 1
epoch = 10
for epoch_num in range(epoch):
for i in range(np.size(x_label)):
loss1 =np.dot(alpha*x_label, gram[:, i])
loss1 = loss1 + b
#print(loss1)
#print(x_label[i]*loss1)
cond = x_label[i] * loss1
if cond <= 0:
alpha[i] = alpha[i] + lr # 昨天在写这个模块的时候,更新的地方写错了,少了i;对应的是每一个样本的alpha_i进行更新;
b = b + lr*x_label[i]
cond = 0
print('[Epoch num: %d] [Alpha: %s] [b:%.4f]' % (epoch_num,str(alpha),b))
print('-----------------------------------------------')
time_end = time.time()
running_time = time_end - time_start
print(alpha)
print(b)
# 计算w,b得到分类器的表达式
w = np.dot(x_label*alpha,x_image)
print('-------------------')
print('The weight w is: %s'%(str(w)))
print('The bias b is: %f' % (b))
print('Running Time:%.5f s'%(running_time))
运行结果

6 使用sklearn实现感知机
主要包括:导入库,喂数据,训练分类器
## 使用的是sklearn 实现感知机
## 流程大概是:导入库,喂数据,fit训练分类器
from sklearn.linear_model import Perceptron
x_train = data[:,:-1] # 获得训练集中的特征值
print(x_train)
y_train = data[:,-1] # 获得训练集数据的标签值
classifier = Perceptron(fit_intercept=False,max_iter=10,shuffle=False)
classifier.fit(x_train,y_train)
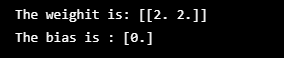
print('The weighit is: %s'%(str(classifier.coef_)))
print('The bias is : %s'%(str(classifier.intercept_)))
结果:
7 总结
使用sklearn是最方便的一个,你需要做的就是处理数据,sklearn把基本的框架都给你搭建好了。自己在学习的时候,最好亲手用Python写一下,梯度怎么更新的,数据怎么存储的,怎么查找到你想要的数据,矩阵怎么相乘,亲手实现一遍会对原理的理解更上一个层次,在这个过程中踩坑是不可避免的。
8回顾
又重新手打了一遍代码
## 感知机模型的实现
import numpy as np
import time
import matplotlib.pyplot as plt
class Perceptron:
def __init__(self):
self.delta = 0.5
self.w = None
self.b = 0
def fit(self, x_train, y_train):
self.w = np.array([1]*x_train.shape[1])
x_image = x_train
y_label = y_train
for loop in range(10): ## loop是遍历数据集的次数,这个表示把数据集用几次来更新模型的参数
for i in range(x_image.shape[0]):
condition = y_train[i]*(np.dot(x_train[i],self.w) + self.b)
if condition <= 0:
self.w = self.w + self.delta*y_train[i]*x_train[i] #必须是+,在李航的书中更新时候也是+,
# 为什么是-的时候,就不可以呢?讲道理的话,只是一个符号的作用啊
self.b = self.b + self.delta*y_train[i]
else:
self.w = self.w
self.b = self.b
loop += loop
return self.w,self.b
def predict(self,x_test):
test_image = x_test
condi = np.dot(test_image, self.w) + self.b
if condi>=0:
print('The predict label is: 1')
else:
print('The test label is : 0')
def draw(x,y):
for i in range(x.shape[0]):
if y[i] >= 0:
plt.scatter(x[i][0],x[i][1],color = 'r',marker='*')
else:
plt.scatter(x[i][0],x[i][1])
if __name__ == '__main__':
x1 = [3,3,1]
x2 = [4,3,1]
x3 = [1,1,-1]
data = np.array([x1,x2,x3]).reshape(3,-1)
x_image = data[:,:-1] # 获得训练集中的特征值
x_label = data[:,-1] # 获得训练集数据的标签值
x_test = np.array([1,1.5])
clf = Perceptron()
w,b = clf.fit(x_image,x_label)
clf.predict(x_test)
print(w,b)
draw(x_image,x_label)
x = np.linspace(0,4,20)
y_ =(-w[0]*x-(b))/w[1] ## 画出分离超平面
plt.plot(x,y_)
运行结果:

Talk is cheap, show me your code.














 1491
1491











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









