







 本文详细介绍了在Vast.ai上配置GPU服务器的过程,包括添加支付方式、租用主机、配置SSH密钥认证及使用Jupyter Notebook进行文件传输的方法。
本文详细介绍了在Vast.ai上配置GPU服务器的过程,包括添加支付方式、租用主机、配置SSH密钥认证及使用Jupyter Notebook进行文件传输的方法。
Vast.ai GPU服务器连接
1. 首先需要在Billing下添加一张信用卡,然后冲$10刀
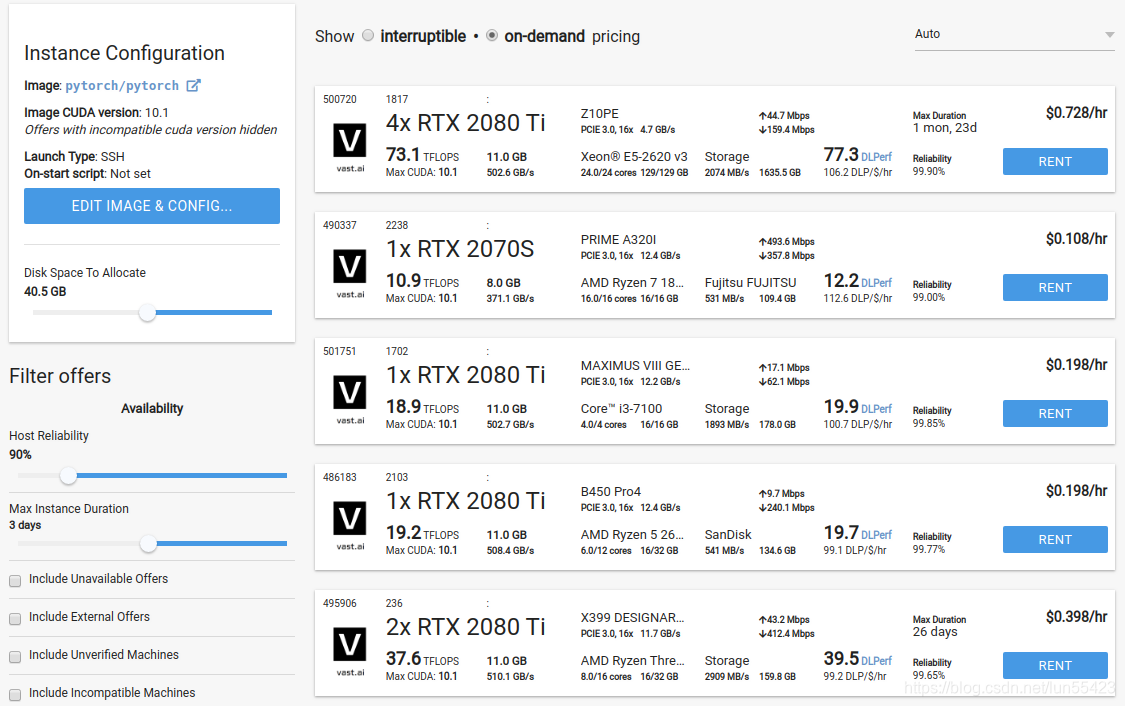
2. 选一台主机,然后RENT!
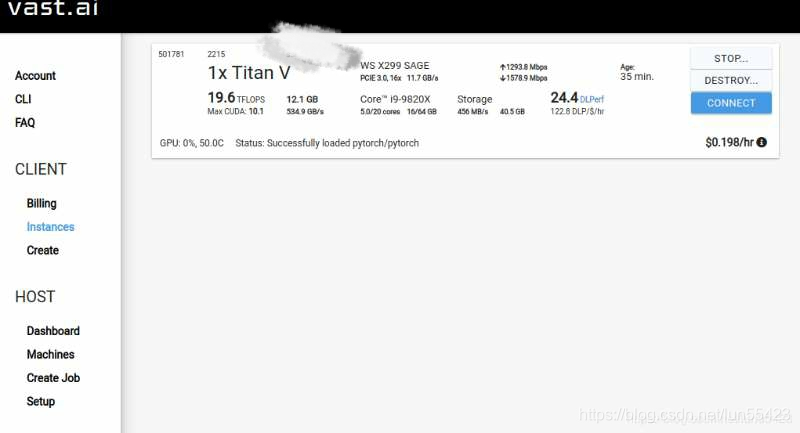
3. 成功以后可以在Instance里面看到
第一次创建Instance时需要配置SSH, 具体操作网站有提示,也可以参照如下步骤:
There is no ssh password, we use ssh key authentication. If ssh asks for a password, typically this means there is something wrong with the ssh key that you entered or your ssh client is misconfigured. On Ubuntu or Mac, first you need to generate an rsa ssh public/private keypair using the command:
ssh-keygen -t rsa
Next you may need to force the daemon to load the new private key:
ssh-add
这一步如果出现Permission Deny需要先启动SSH-AGENT:
eval 'ssh-agent'
然后再执行
ssh-add
Then get the contents of the public key with:
cat ~/.ssh/id_rsa.pub
Copy the entire output to your clipboard, then paste that into the “Change SSH Key” text box under console/account. The key text includes the opening “ssh-rsa” part and the ending “user@something” part. If you don’t copy the entire thing, it won’t work.
example SSH key text:
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQDdxWwxwN5Lz7ubkMrxM5FCHhVzOnZuLt5FHi7J9pFXCJHfr96w+ccBOBo2rtCCTTRDLnJjIsMLgBcC3+jGyUhpUNMFRVIJ7MeqdEHgHFvAZV/uBkb7RjbyyFcb4MMSYNggUZkOUNoNgEa3aqtBSzt33bnuGqqszs9bfDCaPFtr9Wo0b8p4IYil/gfOYBkuSVwkqrBCWrg53/+T2rAk/02mWNHXyBktJAu1q7qTWcyO68JTDd0sa+4apSu+CsJMBJs3FcDDRAl3bcpiKwRbCkQ+N6sol4xDV3zQRebUc98CJPh04Gnc01W02lmdqGLlXG5U/rV9/JM7CawKiIz7aaqv bob@velocity
4. 上传文件或文件夹到服务器
Jupyter Notebook
直接用Upload上传即可
利用scp传输文件
1、从服务器下载文件
scp -P PORT root@IPADDR:/REMOTEDIR/file LOCAL_FILE
将服务器/REMOTEDIR目录下的file下载到本机LOCAL_FILE目录下
2、上传本地文件到服务器
scp -P PORT LOCAL_FILE root@IPADDR:/REMOTEDIR
将本机LOCAL_FILE上传到服务器
例如Connect提供如下信息:ssh -p 7417 root@52.204.230.7 -L 8080:localhost:8080
那么,PORT=7417,IPADDR=52.204.230.7
3、从服务器下载整个目录
scp -r username@servername:remote_dir/ /tmp/local_dir
例如:scp -r codinglog@192.168.0.101 /home/kimi/test /tmp/local_dir
4、上传目录到服务器
scp -r /tmp/local_dir username@servername:remote_dir
例如:
scp -P 22 -r test codinglog@192.168.0.101:/var/www/ 把当前目录下的test目录上传到服务器
的/var/www/ 目录

















 4536
4536

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









