










 Block-RecurrentTransformer是新提出的序列模型,其在处理长序列时具有线性复杂度。它以块为单位进行递归操作,结合自注意力和交叉注意力实现高效计算。与传统的Transformer层相比,该模型在参数量和计算时间上保持相同成本,但在长序列语言建模任务中显著提高了困惑度。在PG19书籍、arXiv论文和GitHub源代码等数据集上,模型表现优于Long-RangeTransformerXL基线,并且运行速度更快。
Block-RecurrentTransformer是新提出的序列模型,其在处理长序列时具有线性复杂度。它以块为单位进行递归操作,结合自注意力和交叉注意力实现高效计算。与传统的Transformer层相比,该模型在参数量和计算时间上保持相同成本,但在长序列语言建模任务中显著提高了困惑度。在PG19书籍、arXiv论文和GitHub源代码等数据集上,模型表现优于Long-RangeTransformerXL基线,并且运行速度更快。
Block-Recurrent Transformer
论文地址:https://arxiv.org/abs/2203.07852v1
github:https://github.com/lucidrains/block-recurrent-transformer-pytorch
摘要
We introduce the Block-Recurrent Transformer, which applies a transformer layer in a recurrent fashion along a
sequence, and has linear complexity with respect to sequence length. Our recurrent cell operates on blocks of tokens
rather than single tokens, and leverages parallel computation within a block in order to make efficient use of accelerator
hardware. The cell itself is strikingly simple. It is merely a transformer layer: it uses self-attention and cross-attention to
efficiently compute a recurrent function over a large set of state vectors and tokens. Our design was inspired in part by
LSTM cells, and it uses LSTM-style gates, but it scales the typical LSTM cell up by several orders of magnitude. Our
implementation of recurrence has the same cost in both computation time and parameter count as a conventional
transformer layer, but offers dramatically improved perplexity in language modeling tasks over very long sequences.
Our model out-performs a long-range Transformer XL baseline by a wide margin, while running twice as fast. We
demonstrate its effectiveness on PG19 (books), arXiv papers, and GitHub source code.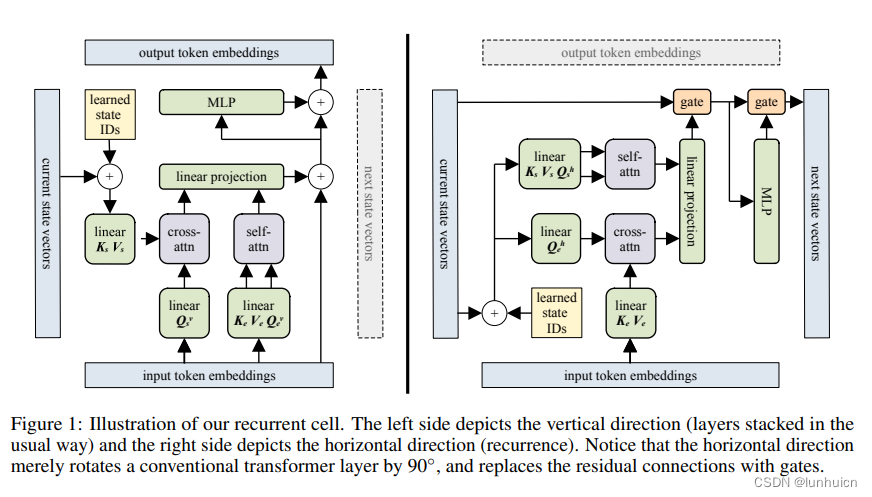




Install
$ pip install block-recurrent-transformer-pytorch
Usage
import torch
from block_recurrent_transformer_pytorch import BlockRecurrentTransformer
model = BlockRecurrentTransformer(
num_tokens = 20000, # vocab size
dim = 512, # model dimensions
depth = 6, # depth
dim_head = 64, # attention head dimensions
heads = 8, # number of attention heads
max_seq_len = 1024, # the total receptive field of the transformer, in the paper this was 2 * block size
block_width = 512, # block size - total receptive field is max_seq_len, 2 * block size in paper. the block furthest forwards becomes the new cached xl memories, which is a block size of 1 (please open an issue if i am wrong)
num_state_vectors = 512, # number of state vectors, i believe this was a single block size in the paper, but can be any amount
recurrent_layers = (4,), # where to place the recurrent layer(s) for states with fixed simple gating
use_compressed_mem = False, # whether to use compressed memories of a single block width, from https://arxiv.org/abs/1911.05507
compressed_mem_factor = 4, # compression factor of compressed memories
use_flash_attn = True # use flash attention, if on pytorch 2.0
)
seq = torch.randint(0, 2000, (1, 1024))
out, mems1, states1 = model(seq)
out, mems2, states2 = model(seq, xl_memories = mems1, states = states1)
out, mems3, states3 = model(seq, xl_memories = mems2, states = states2)

















 7421
7421

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









