







第四十五周学习笔记
论文阅读概述
- Context and Attribute Grounded Dense Captioning,本文通过将global,neighboring和local的图像特征融合,实现更加准确的dense caption,并引入coarse-to-fine损失函数,来辅助caption model选择更加准确的词
- Dense Relational Captioning:Triple-Stream Networks for Relationship-Based Captioning,本文根据通常的dense caption结果都是sub-pred-obj的词性的规律来辅助,对于一张图片,根据每两个object生成一个dense caption
- Self-critical Sequence Training for Image Captioning,本文采用强化学习中的策略梯度算法来进行image caption学习,具体方法是REINFORCE+baseline,在CIDEr上优化,将CIDEr从104.9提升到了114.7
- METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments,本文提出了新的nlg自动度量METEOR,它提出了BLEU的缺点:无法度量recall,词的匹配机制不精确,高阶n-gram的匹配只是句子结构的间接而非直接度量。通过一对一匹配完成recall度量,精确、词根、词意匹配完成词的精确匹配,引入chunk来实现句子结构的匹配
- Show, Control and Tell: A Framework for Generating Controllable and Grounded Captions,本文着重解决控制image caption的输出这一问题,在输入处加上一个控制的信号来构建可控的、有针对的image caption模型,
Self critical Sequence Training
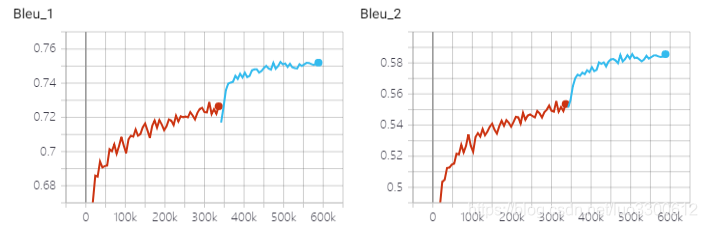

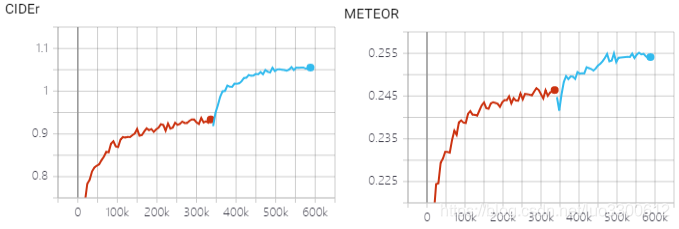
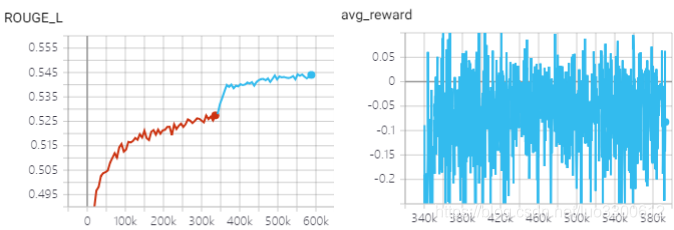
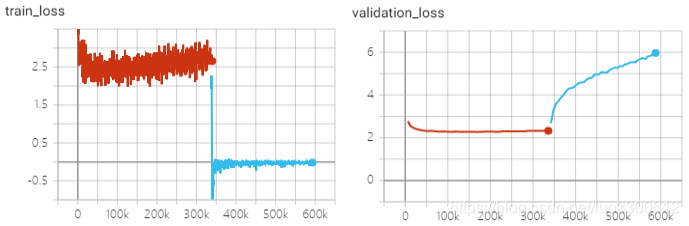
本次实验跑了self-critical sequence trainig的模型,包括两个阶段,第一个阶段是交叉熵预训练阶段,第二个阶段是对CIDEr-D使用强化学习训练
强化学习训练后,模型的各项metric都大幅上升,在此前,交叉熵训练已几乎达到饱和,说明交叉熵作为损失函数,与最终语言生成模型的metric并不一定一致,尤其是使用强化学习后,validation loss增加但各项metric也在增加,也说明了这个问题
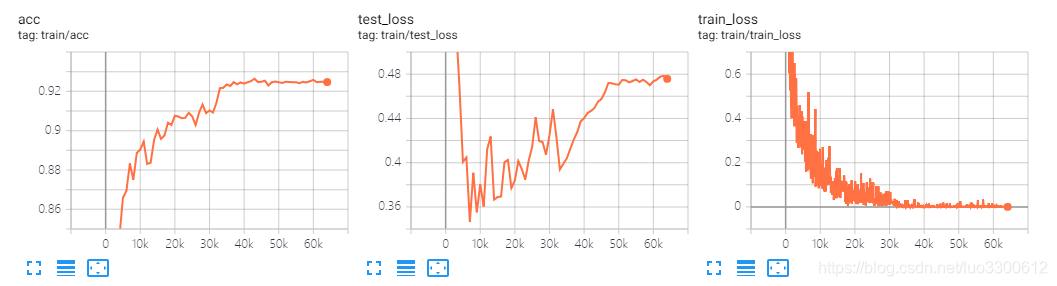
VGG CIFAR10
vgg16效果比resnet20好一点,最高acc为92.58%,随着训练过程,test loss增加但acc却几乎保持没变,
本周小结
- 论文阅读,完成
下周目标
- 论文阅读














 1917
1917











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









