







 本文总结了密集事件描述(dense event caption, DEC)领域的几篇重要论文,探讨了如何从2017年开始利用深度学习解决视频多事件描述问题。DEC旨在对视频中的每个事件生成一句话描述,通过引入注意力机制、双向信息融合和端到端模型等方法,不断优化事件定位和描述的准确性。文章分析了各方法的优缺点,指出了未来研究的方向,如更好的事件提案提取和端到端训练策略。"
126103890,10826678,配置Modbus转Profinet网关与ARX-MA100空气质量监测系统,"['工业自动化', 'PLC编程', 'Modbus通讯', '物联网', '数据采集']
本文总结了密集事件描述(dense event caption, DEC)领域的几篇重要论文,探讨了如何从2017年开始利用深度学习解决视频多事件描述问题。DEC旨在对视频中的每个事件生成一句话描述,通过引入注意力机制、双向信息融合和端到端模型等方法,不断优化事件定位和描述的准确性。文章分析了各方法的优缺点,指出了未来研究的方向,如更好的事件提案提取和端到端训练策略。"
126103890,10826678,配置Modbus转Profinet网关与ARX-MA100空气质量监测系统,"['工业自动化', 'PLC编程', 'Modbus通讯', '物联网', '数据采集']
密集事件描述(dense event caption)论文总结
密集事件描述(DEC)
何为密集事件描述(DEC),其实它是视频描述(video caption)的一个分支,视频描述自2015年的S2VT方法以来开始广泛的使用深度神经网络尤其是RNN模型来解决视频描述任务,本人也写了本文也写了视频描述论文相关的综述:
https://blog.csdn.net/sinat_35177634/article/details/88568491
但视频描述在2017年以前多集中在解决使用单个句子来描述整个视频,也有使用多个句子整合成一段话来描述视频。但我们知道视频不同于图像,视频较之图像多了时序信息,这就导致视频有了更多的对象、更多的动作和更多的场景事件。对于短视频使用单句来描述视频或许效果还可以,但是对于长视频,单句无法表达视频的全部信息。于是2017年CVPR的一篇论文Dense-Captioning Events in Videos应运而生,简单来说就是先将长视频分成各个事件,然后对每个视频生成一句话来描述这个事件,如图所示。DEC的发展也依仗于2016年提出的数据集activityNet,这个数据集不仅包含视频,同时其中的视频已经根据event划分好了segment,同时也对每个segment生成了对应的描述,这里多提一句,activityNet这个数据集不仅可以用于DEC任务,同时也可以用于视频动作识别,视频目标检测等等。并且这个数据集主要针对人类的动作。到了2018年关于DEC的研究得到了广泛的关注,在2018年发表的论文也可以体现出来,下面就是本人对DEC任务论文的总结。
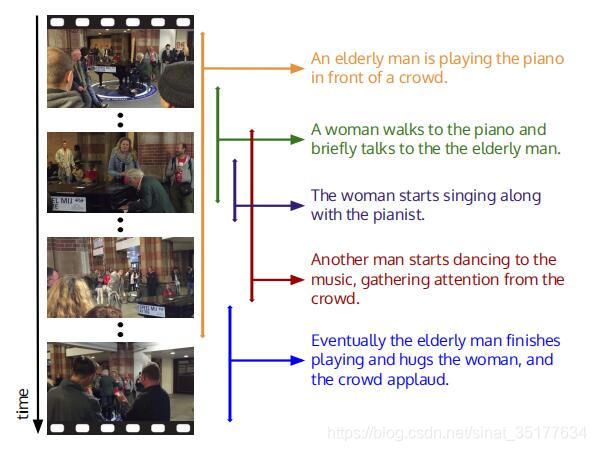
Dense-Captioning Events in Videos 2017 CVPR
这篇文章可以看做是DEC的开山之作,同时也得益于2016年提出的数据集activityNet,这是个视频数据集,主要针对人类的动作,数据集已经标注好了每个视频的segment,并且标注了每个segment的动作类别和对应的caption,这样对我们训练和测试DEC模型成为可能。
这篇论文提出了两个问题,问题一是在一个视频中,有多个segment,并且这些segment可能有交叉和重叠,当前(2017年之前)的方法,最好的action proposal是DAPs,它只能定位没有交叉和重叠的action segment。第二个问题,虽然对每个action segment有一个caption,但是caption之间是有关系的,需要利用上下文关系来生成当前的caption,那么这篇论文是如何解决这个问题的呢,请看下文。
首先来看一下整个流程图:
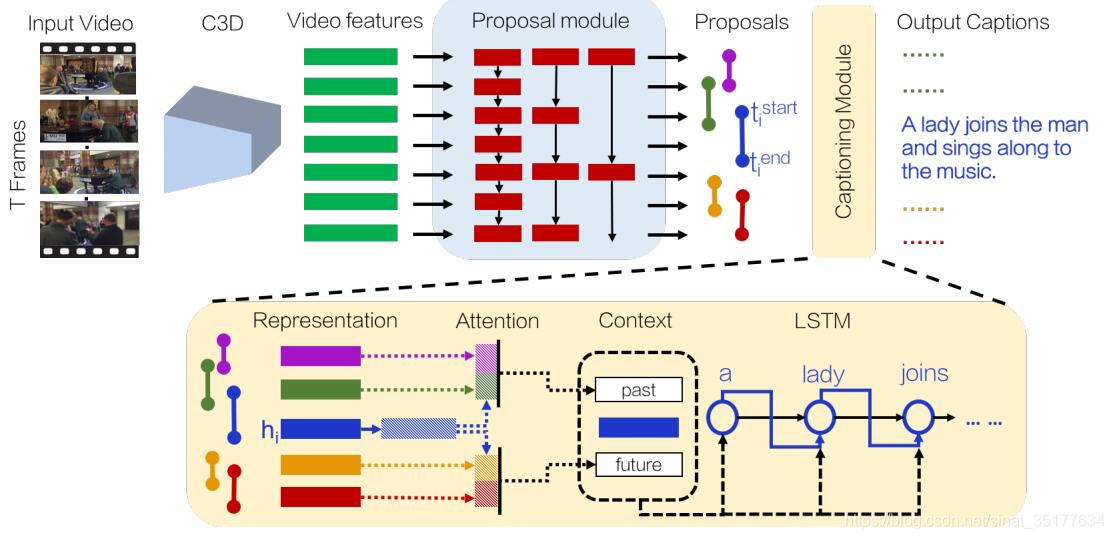
如图输入为整个视频,先使用C3D网络来提取特征,在使用DAPs来提取action proposal,为了可以得到交叉重叠的segment,对视频特征使用不同的stride来采样输入到DAPs模型中,这样就得到了不同的action proposal,再对每个proposal生成caption,这里为了使用到上下文即其他的segment信息,使用了attention机制,对当前segment前面的segment特征加权得到一个past的特征,再对segment之后的segment特征加权得到一个future特征,再和当前的segment特征融合为一个整体特征,输入到LSTM网络中生成caption。
以上是该方法的整体流程,在训练过程中,对action proposal和caption generate两个模块交替训练,以下是部分测试集的结果:

上图主要表明了该方法使用的attention机制是有效的,其中online context是仅使用了past特征。(毕竟在action proposal使用的是别人的方法于是重点强调了自己的创新点)。一下的实验结果:
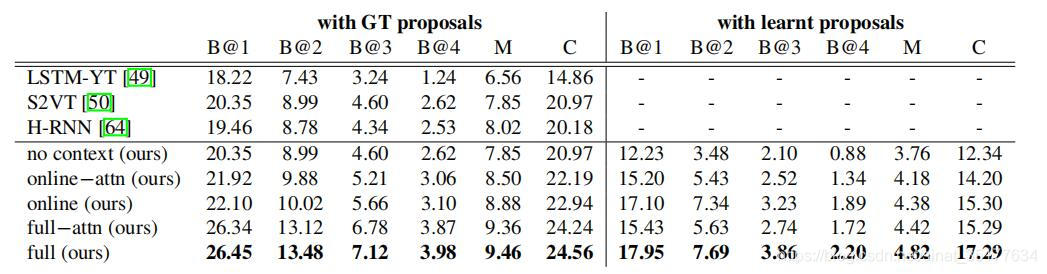
我们可以看到在使用ground truth proposals测试时文章提出的方法明显好于其他的方法,这再次证明了文章在caption generate模块使用的attention机制是有效的,由于文章是第一篇DEC方法于是在使用learnt proposal测试时没有对比的方法。其中我们可以发现使用learnt proposal得到的结果明显不如使用GT proposal得到的结果,这说明提取action proposal的方法有待改善。同时在生成caption的模块中使用的是传统的S2VT方法(2015),也可以使用更先进的方法,比如双向LSTM,或者加上类别信息等,或者语音等特征来强化生成caption的结
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3359
3359

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









