







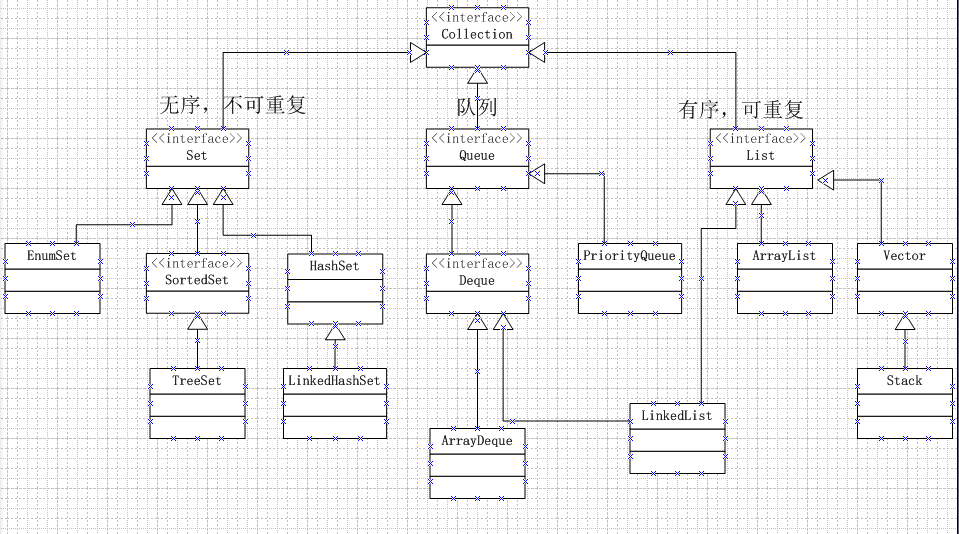
- 四大集合概述
- Set集合
- List集合
- Queue集合
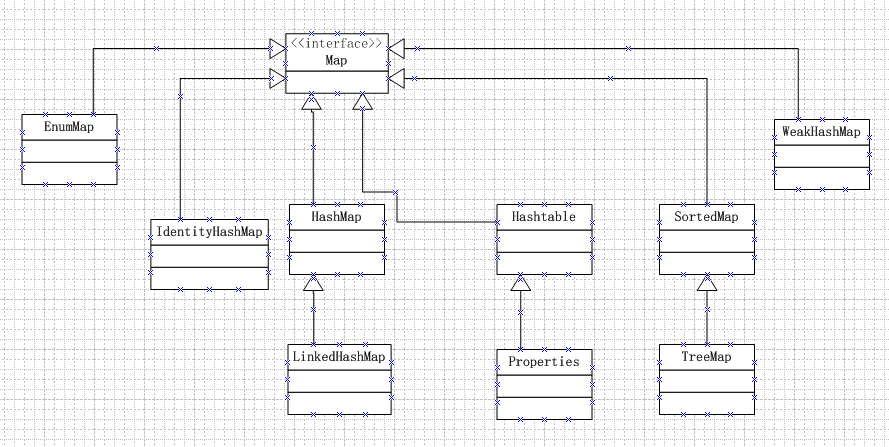
- Map集合
- 重要的工具类:Collections
- 一些其他的接口
四大集合概述
与数组相比,集合最大的特点是具有映射关系,它里面只能盛装对象(对象的引用),而数组却是什么都能装,什么都能放,所以才有了那句屌屌的言论”有了数组和对象,就可存放下一切数据”。
提到集合,就不得不说Collection和Map,这两个接口是集合的根,java中所有的集合都是由它们派生出来的。闲言少叙,可参看文章末尾的继承树。
set集合
基本特点:无序(插入的顺序),不可重复。
常见的实现类:HashSet、TreeSet、EnumSet
使用建议:不要修改元素的实例变量,否则极易出错。
- HashSet
特点:不是线程同步的,元素可以为null
原理:通过hashCode()值决定存储位置。查询时调用hashCode()方法,直接定位到该元素,是查询速度快的主要原因。两个相等元素必须满足equal()方法返回true;hashCode值相同。
Set中使用最广泛,按照典型的Hash算法来存储元素,适合普通的插入、删除。
- LinkedHashSet
HashSet的子类,使用双向链表维护顺序,性能略低,迭代速度快(链表嘛)。因需要维护链表,插入、删除比HashSet稍慢。
- TreeSet
特点:实现自SortedSet接口(Set接口的派生接口),不是线程安全的。元素必须实现Comparable接口,所以不能为null,总是处于排序状态(自然按大小排序)。两个相等元素的标准:compareTo()是否返回0。
原理:红黑树存储集合元素。支持自然排序和定制顺序。
很明显,适合排序。
- EnumSet
特点:不是线程同步的。构造器不可访问,元素有序,且必须是同一枚举类的枚举值,所以不能为null。
原理:以位向量的形式存储。几种set中性能最好,批量操作,更显优势。
适合枚举类。
List集合
基本特点:有序、可重复。
基本原理:两个相等元素的标准:equal()方法是否返回true。
- ArrayList
特点:不是线程安全的。
原理:动态封装了一个允许再分配的Object[]数组,默认长度10,随机访问性能好(get方法,其实访问的是数组)。
可能是用的最多的集合,通常用Collections工具类来解决安全问题,用ArrayDeque解决栈结构的数据。
- Vector
特点:上古时代的集合产物。线程安全的。
Vector及其子类Stack(栈结构)性能较差,不推荐使用。
Queue集合
基本特点:模拟队列(先进先出),一般不允许插队,即随机访问队列中的元素。
- PriorityQueue
特点:不标准的队列实现类,元素不可以为null。
原理:元素按大小排序(不标准,比较蛋疼),不是先进先出的标准队列。
之所以说PriorityQueue比较蛋疼,是因为如果直接调用它的toString()方法,输出的并不是标准的大小顺序;但是如果你逐个调用poll()方法输出的时候,又能看到它按大小顺序输出队列。
支持自然排序和定制排序。自然排序要求元素必须是同一个类的实例,并实现Comparable接口。定制排序需要传入一个Comparator对象,不要求元素实现Comparable接口。与TreeSet类似。
- ArrayDeque
特点:不是Queue的直接实现类。实现的是Queue的子接口Deque(双端队列或者“栈”)。
原理:与ArrayList类似,一个动态的Object[]数组,默认长度16,随机访问性能好。
用到“栈”时,就想ArrayQueue吧,Stack老掉牙了。
- LinkedList
特点:杂交产物。可按索引访问,可当双端队列使用。功能极强。
原理:实现了List接口,也实现了Deque接口。
相比ArrayList,ArrayDeque等基于数组的实现,LinkedList更适合频繁的插入、删除(只需移动指针),前者更适合随机访问(get方法)。
一般的:
(1)遍历集合,ArrayList、Vector应使用get方法,LinkedList应使用Iterator。
(2)频繁的插入、删除使用LinkedList链表集合,原因从实现原理上想。
Map集合
基本特点:保存带映射关系的数据。
原理:与Set惊人的像,连名字都一样。源码中,Set的实现是基于Map的,它就是一个所有value为null的Map。同时Map提供了内部类Entry来返回一个“key-value”的Set集合。
- Hashtable
特点:上古时代的产物。线程安全。key和value都不允许为null。
不推荐使用。
- HashMap
原理:基于数组实现。
特点:性能略高。线程不安全。允许一个key为null,无数个value为null。
它们俩与HashSet十分相似。都不能保证元素顺序,也不允许相同的key值,甚至连判断key值是否相等的标准都一样。判断value值相等则要简单些:equal方法返回true即可。
- LinkedHashMap
特点:HashMap的子类,对应LinkHashSet类,有序(插入的顺序)。
因维护链表的开销,性能略低于HashMap,迭代访问全部元素时有较好的表现。
- Properties
特点:Hashtable的子类。
可方便地读取ini、xml等属性文件。
- TreeMap
特点:对应与TreeSet,它也实现自SortMap接口(Map接口的派生接口)
原理:红黑树结构存储数据。每个节点对应一个key-value对。
支持自然排序和定制排序。要求仍一样,自然排序时,所有的key必须实现Comparable接口,且是同一个类的对象;定制排序时,需要传入一个Comparator对象(注意equals方法和compareTo方法比较结果要一致)。
- WeakHashMap
特点:名字上应该也看出来了。key只保留了对象的弱引用,当key所引用的对象没有其他强引用时,这些对象可能被回收(一提到可能,里面文章就大了),如果垃圾回收了key所对应的实际对象,WeakHashMap就毫不犹豫地删除了该key对应的 key-value对。
所以呃,不要让WeakHashMap的key保留任何强引用,否则那就没意思了。
- IdentityHashMap
原理:实现机制与HashMap基本一致。
只是判断key是否相等条件更苛刻,必须严格满足key1==key2,够厉害了吧。
- EnumMap
特点:所有key必须是某个枚举类的枚举值,所以不允许null作为key
原理:基于数组形式,性能最好。
存储的顺序与枚举类中枚举值定义的顺序一致,不是存入的先后顺序哟。
工具类:Collections
操作集合必须知道的一个类,估计有不少人跟我一样,开始接触java时,想进办法来实现集合的某种操作,不成想,多年以后才发现,原来人家早就给你封装好了,而且还更优雅更高效。
常用的操作:
(1)排序
- 反转 reverse
- 自然排序 sort
- 洗牌 shuffle
- 交换 swap
- 整体迁移 rotate
(2)查找、替换
- 二分查找 binarySearch
- 最值 max/min
- 填充 fill
- 频率统计 frequency
- 替换 replaceAll
- 位置索引 indexOfSubList/lastIndexOfSubList
(3)同步控制
应该是用的比较多的。synchronizedXxx()方法。
线程不安全的集合也列一下:
HashSet、TreeSet、EnumSet(set的三个实现均不安全)ArrayList、ArrayDeque,LinkedList、HashMap、TreeMap等
(4)不可变集合
- 空集合 emptXxx
- 单个元素集合 singletonXxx
- 不可变集合 unmodifiableXxx
一些其他的接口
- Enumeration
名字太长的古老接口,是Iterator的先人,它里面只有两个方法hasMoreElements和nextElement,作用就很明显了。
Enumeration因其方法有限,所以不推荐使用。
附:面试中经常会比较HashMap和Hashtable的区别,这里也总结一下,主要有三点:
- HashMap不是线程安全,Hashtable线程安全,前者性能略高;
- HashMap允许一个key为null,多个value为null,如果多个key相同(均为null),则后面的会覆盖前面的;HashSet也只允许一个元素为null,如果多个元素相同(均为null),则后面的会覆盖前面的;Hashtable的key和value都不允许null出现。
- 继承树顶端都是Map接口,前者父类是AbstractMap,后者是Dictionary,比较古老(名字不规范),不推荐使用。
总结自用,欢迎留言拍砖。















 19万+
19万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









