







🧡🧡实验内容🧡🧡
编写胶囊网络分类软件(编程语言不限,如 Python 等),实现对 MNIST 数据集分类的操作。
🧡🧡代码🧡🧡
import torch
from torch import nn
from torch.optim import Adam
import torch.nn.functional as F
from torchvision import transforms, datasets
import time
import matplotlib.pyplot as plt
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_set = datasets.MNIST('data', train=True, download=True, transform=transform)
test_set = datasets.MNIST('data', train=False, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_set, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_set, batch_size=1000, shuffle=True)
# !nvidia - smi
# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
# @title 胶囊 net
def squash(inputs, axis=-1):
inputs = inputs.to(device)
norm = torch.norm(inputs, p=2, dim=axis, keepdim=True)
scale = norm ** 2 / (1 + norm ** 2) / (norm + 1e-8)
return scale * inputs
# 预胶囊层
class PrimaryCapsule(nn.Module):
def __init__(self, in_channels, out_channels, dim_caps, kernel_size, stride=1, padding=0):
super(PrimaryCapsule, self).__init__()
self.dim_caps = dim_caps
self.conv2d = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding)
def forward(self, x):
outputs = self.conv2d(x)
outputs = outputs.view(x.size(0), -1, self.dim_caps)
return squash(outputs)
# 胶囊层(重构层)
class DenseCapsule(nn.Module):
def __init__(self, in_num_caps, in_dim_caps, out_num_caps, out_dim_caps, routings=3):
super(DenseCapsule, self).__init__()
self.in_num_caps = in_num_caps
self.in_dim_caps = in_dim_caps
self.out_num_caps = out_num_caps
self.out_dim_caps = out_dim_caps
self.routings = routings
self.weight = nn.Parameter(0.01 * torch.randn(out_num_caps, in_num_caps, out_dim_caps, in_dim_caps))
def forward(self, x):
x_hat = torch.squeeze(torch.matmul(self.weight, x[:, None, :, :, None]), dim=-1)
x_hat_detached = x_hat.detach() # 通过detach()方法获得的张量不再具有梯度,即它是一个常量张量,不会对反向传播产生影响。
# The prior for coupling coefficient, initialized as zeros.
# b.size = [batch, out_num_caps, in_num_caps]
b = torch.zeros(x.size(0), self.out_num_caps, self.in_num_caps)
b = b.to(device)
# print(f"b shape={b.shape}")
assert self.routings > 0, 'The \'routings\' should be > 0.'
for i in range(self.routings):
# c.size = [batch, out_num_caps, in_num_caps]
c = F.softmax(b, dim=1)
c = c.to(device)
# print(f"c shape={c.shape}")
if i == self.routings - 1:
# dim=-2:倒数第二个维度求和, keepdim=True:保持计算前后维度不变
outputs = squash(torch.sum(c[:, :, :, None] * x_hat, dim=-2, keepdim=True))
else: # Otherwise, use `x_hat_detached` to update `b`. No gradients flow on this path.
outputs = squash(torch.sum(c[:, :, :, None] * x_hat_detached, dim=-2, keepdim=True))
b = b + torch.sum(outputs * x_hat_detached, dim=-1)
# print(f"outputs shape={torch.squeeze(outputs, dim=-2).shape}")
return torch.squeeze(outputs, dim=-2) # 将倒数第二维去掉
# 组合以上
class CapsuleNet(nn.Module):
def __init__(self, input_size, classes, routings):
super(CapsuleNet, self).__init__()
self.input_size = input_size
self.classes = classes
self.routings = routings
# Layer 1: Just a conventional Conv2D layer
self.conv1 = nn.Conv2d(
input_size[0], 256, kernel_size=9, stride=1, padding=0)
# Layer 2: Conv2D layer with `squash` activation, then reshape to [None, num_caps, dim_caps]
self.primarycaps = PrimaryCapsule(
256, 256, 8, kernel_size=9, stride=2, padding=0)
# Layer 3: Capsule layer. Routing algorithm works here.
self.digitcaps = DenseCapsule(in_num_caps=32 * 6 * 6, in_dim_caps=8,
out_num_caps=classes, out_dim_caps=16, routings=routings)
self.relu = nn.ReLU()
def forward(self, x, y=None):
x = self.relu(self.conv1(x))
x = self.primarycaps(x)
x = self.digitcaps(x)
# 对(64,10,16),计算最后一维向量的长度,即对应10个分类类别的存在概率,16蕴含特征的空间、局部位置等信息
length = x.norm(dim=-1)
return length
# @title Train and Test
def test(data_iter, net):
acc_sum, n = 0.0, 0
with torch.no_grad():
for X, y in data_iter:
X = X.to(device)
y = y.to(device)
if isinstance(net, torch.nn.Module):
net.eval() # 评估模式, 这会关闭dropout
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
net.train() # 改回训练模式
else:
if ('is_training' in net.__code__.co_varnames): # 如果有is_training这个参数
# 将is_training设置成False
acc_sum += (net(X, is_training=False).argmax(dim=1) == y).float().sum().item()
else:
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
n += y.shape[0]
return acc_sum / n
def train(train_iter, test_iter, net, loss, optimizer, epochs):
batch_count = 0
loss_list = []
test_acc_list = []
for epoch in range(epochs):
train_loss_sum, train_acc_sum, n, start = 0.0, 0.0, 0, time.time()
for X, y in train_iter:
X = X.to(device)
y = y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
optimizer.zero_grad()
l.backward()
optimizer.step()
train_loss_sum += l.item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().item()
n += y.shape[0]
batch_count += 1
# print(f"batch_count: {batch_count}")
test_acc = test(test_iter, net)
loss_list.append(train_loss_sum / batch_count)
test_acc_list.append(test_acc)
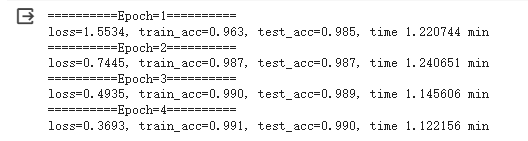
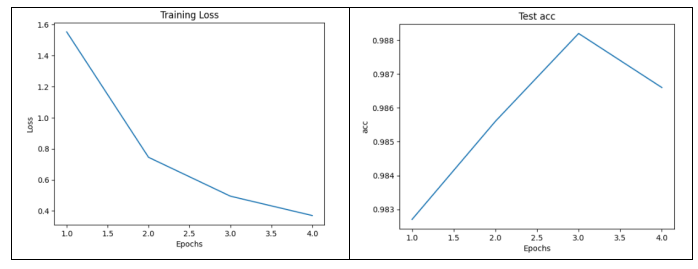
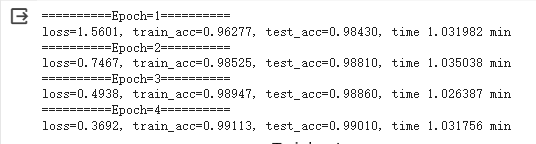
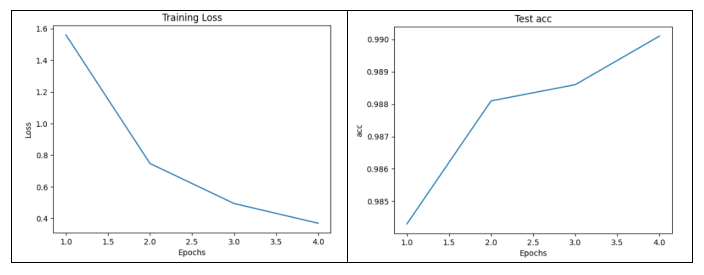
print('==========Epoch=%d========== \nloss=%.4f, train_acc=%.5f, test_acc=%.5f, time %f min'
% (epoch + 1, train_loss_sum / batch_count, train_acc_sum / n,
test_acc, (time.time() - start) / 60))
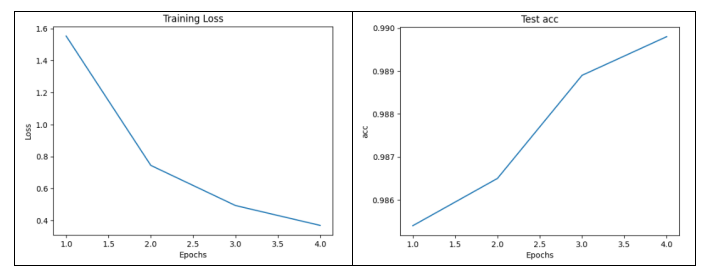
# 绘制损失函数随训练轮数的变化图
plt.plot(range(1, epochs + 1), loss_list)
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.title('Training Loss')
plt.show()
# 绘制准确率随训练轮数的变化图
plt.plot(range(1, epochs + 1), test_acc_list)
plt.xlabel('Epochs')
plt.ylabel('acc')
plt.title('Test acc')
plt.show()
batch_size, lr, epochs = 100, 0.001, 4
net = CapsuleNet(input_size=[1, 28, 28], classes=10, routings=8)
net = net.to(device)
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
loss = loss.to(device)
train(train_loader, test_loader, net, loss, optimizer, epochs)
🧡🧡分析结果🧡🧡
数据预处理:
加载数据集:
加载torch库中自带的minst数据集
转换数据:
转为tensor变量(相当于直接除255归一化到值域为(0,1)),再设置mean和st
d标准化到(-1,1)区间。
设置基本参数:
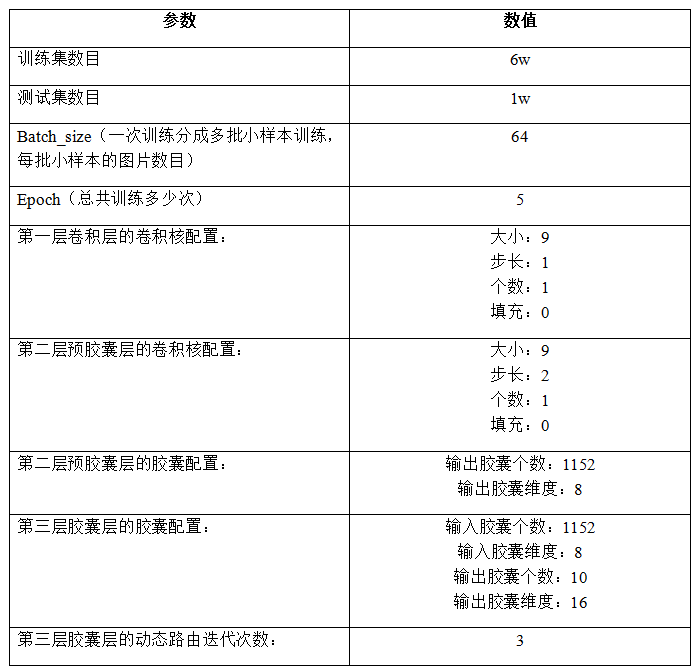
构建胶囊网络:
- 第一层:(64,28,28,1) => (64,20,20,256)
- 卷积核大小为9,步长为1,故图片由28×28缩小为20×20,输出特征数设为256- 第二层:(64, 20, 20, 256) => (64,6,6,256) => (64, 1152, 8)
- 先进行一层卷积操作,卷积核大小为9,步长为2,故图片由20×20缩小为6×6,输出特征数仍然为256。
- 将输出通道数256分割成32×8的向量,合并中间维度(64, 6×6×32, 8) =>(64, 1152, 8),即有1152个胶囊,每个胶囊维度为8。
进行squash激活。- 第三层:(64, 1152, 8) => (64, 10, 16)
- 输入的胶囊个数为1152,维度为8,目标是转为胶囊个数为10,维度为16。
- 对输入向量扩维:(64, 1152, 8) =>(64, 1, 1152, 8, 1),然后使用维度为 (1, 10, 1152, 16, 8)的权重w与其进行矩阵乘法,得到x_hat ,其维度为(64, 10, 1152, 16, 1),去除最后一维,维度变成 (64, 10, 1152, 16)。
- 设置初始权重b,其维度为(64, 10, 1152, 1),使用动态路由算法将归一化后的b与x_hat多次相乘并累加,得到维度为(64, 10, 1, 16)的向量,去除倒数第二个维度,最后变为(64, 10, 16)的输出向量。- 输出结果:(64, 10, 16) => (64, 10)
- 64代表batch_size,10代表10个图片分类标签,16代表这10个向量所具有的空间、相对位置等相关信息(CNN则没有),通过计算这10个向量的长度,即可得到分类概率。
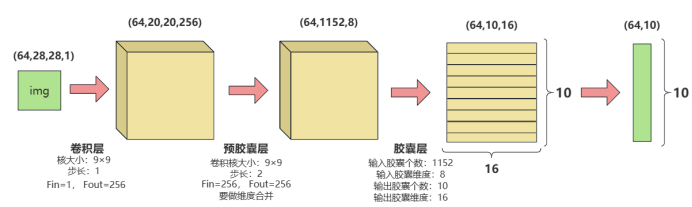
模型训练与评估:
可以看到,设置了4个epoch,准确率即达到了98.7%, 高于CNN和BP。
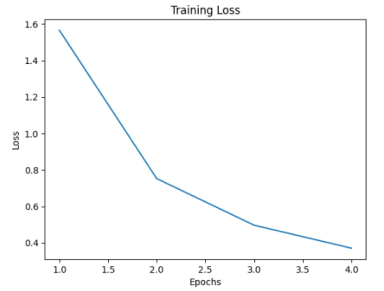
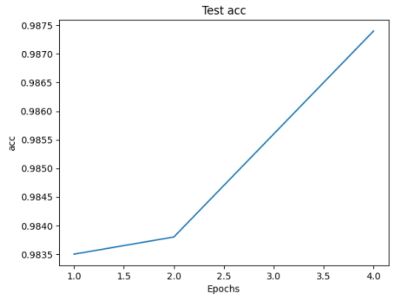
分析胶囊参数对分类准确率的影响
更改胶囊参数原则:
在卷积核参数不变的情况下,主要第二层预胶囊层中的输出胶囊维度,然后自己手算第二层预胶囊层的输出个数;之后第三层胶囊层的输入胶囊个数和维度同第二层的胶囊输出维度,第三层胶囊层个数为10固定不变(因为有10个类别),胶囊层维度可以更改。
被对照实验:
输入胶囊个数=1152、输入胶囊维度=8、输出胶囊个数=10、输出胶囊维度=16
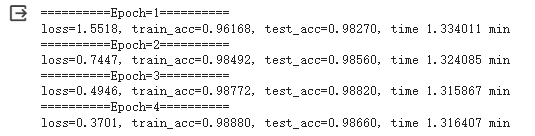
参照问题1,准确率为98.70%,运行时间为4.931 minutes
对照实验1:
输入胶囊个数=512、输入胶囊维度=16、输出胶囊个数=10、输出胶囊维度=16
对照实验2:
输入胶囊个数=512、输入胶囊维度=16、输出胶囊个数=10、输出胶囊维度=32
对照实验3:
输入胶囊个数=512、输入胶囊维度=16、输出胶囊个数=10、输出胶囊维度=8
总结以上结果如下表(epoch=4):
(表格中的“输入输出”指的是第三层胶囊层的输入输出胶囊)
由此分析可知:
- 输入胶囊个数和维度:
在第一行和第二行中,更改第三层的输入胶囊个数和维度,一方面增加了输入胶囊的维度,使得每个胶囊能够表示更多的特征信息,从而提高了分类准确率;另一方面胶囊个数减少,从而减少了运行时间。- 输出胶囊个数和维度:
观察第二、三行、四行,可以看到随着输出胶囊维度减小,分类准确率得到提高,且模型运行时间相应减少。据此判断胶囊维度小,浓缩了对判断分类最为有利的特征信息,减少了冗余无用的干扰信息,因此使得准确率得到提高。


🧡🧡实验总结🧡🧡
理论理解方面:
胶囊网络与CNN卷积网络的主要区别:
- CNN擅长提取图像中的局部特征,其中,池化层可以降低采样数,将一个邻域的重要特征提取出来以代表区域特征,但是,也正因为此,池化层的计算过程中会损失空间特征,即特征组合的相对信息位置。例如对于一张人脸图像,CNN很容易提取出眼睛、嘴巴、鼻子这些局部的重要的特征,但是眼睛、嘴巴、鼻子之间的相对位置关系却无法获得。
- 基于以上CNN存在的问题,而提出了胶囊网络的概念,胶囊网络中的胶囊单元(包含许多神经元)能够捕捉图像中的层次结构和空间关系,并且设计了动态路由算法来实现胶囊之间的信息传递和姿态估计。
代码实操方面:
- 首先是运行时间问题,前两次CNN和BP实验中,用CPU跑,分别设计epoch=5和epoch=15,运行时间在3-4min左右,而本次实验,我首先用的CPU跑,但是跑了半个小时仍然没有完成一个epoch,于是感叹它的复杂性。好在Google colab自带免费的GPU,才解决了我的燃眉之急。本实验中,一开始设置为epoch=5时,超过了Google colab自带的GPU算力,运行不下去,只好统一设计为epoch=4。
- 其次是复杂的矩阵运算。二维矩阵与二维矩阵相乘我还会,但是在重构胶囊信息时,要进行五维矩阵与五维矩阵的乘法,例如维度(64, 10, 1152, 16, 8)的矩阵与维度(64, 1, 1152, 8, 1)进行矩阵乘法,就比较懵了。通过网上学习,了解到:只要看最后两维度相乘,前面的维度通过“维度广播”一般取最大值即可,所以相乘之后的矩阵的维度为(64, 10, 1152, 16, 1)。















 5901
5901

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









