







🌔在多任务中,总损失常常是各分任务损失的线性加权,此时各分任务损失的权重设定就显得尤为重要。
比如在JDE算法中就使用了多任务损失的自适应设定:
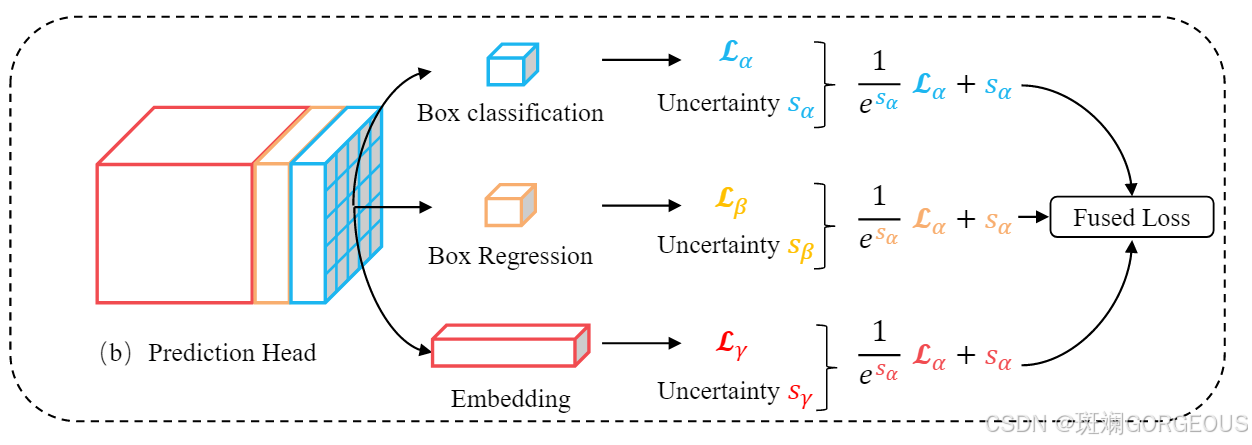
这里使用的权重自适应方法便来自以下这篇文章发掘的不确定度与权重的关系:
Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics
本文正是基于此,用步步衔接的数学推导,讲解多任务损失函数权重设定原理。
总的来说用不确定度估计多任务损失权重的核心是:
各任务的权重与其对应的噪声成反相关
0️⃣ 多任务独立性
⭐️对于模型输出
f
W
(
x
)
\mathbf{f^W(x)}
fW(x)以及对应的真值
y
\mathbf{y}
y,多任务(假设是相互独立的)的概率估计可以表示为以下这种形式:
p
(
y
1
,
…
,
y
K
∣
f
W
(
x
)
)
=
p
(
y
1
∣
f
W
(
x
)
)
…
p
(
y
K
∣
f
W
(
x
)
)
p(\mathbf{y_1,\dots,y_K|f^W(x)})=p(\mathbf{y_1|f^W(x)})\dots p(\mathbf{y_K|f^W(x)})
p(y1,…,yK∣fW(x))=p(y1∣fW(x))…p(yK∣fW(x))
假设使用
−
log
-\log
−log来计算损失,则有:
L
t
o
t
a
l
=
−
log
[
p
(
y
1
,
…
,
y
K
∣
f
W
(
x
)
)
]
=
(
−
log
[
p
(
y
1
∣
f
W
(
x
)
)
]
)
+
⋯
+
(
−
log
[
p
(
y
K
∣
f
W
(
x
)
)
]
)
=
L
1
+
⋯
+
L
K
L_{total}\\=-\log[p(\mathbf{y_1,\dots,y_K|f^W(x)})]\\=(-\log[p(\mathbf{y_1|f^W(x)})])+\dots+ (-\log[p(\mathbf{y_K|f^W(x)})])\\=L_1+\dots+L_K
Ltotal=−log[p(y1,…,yK∣fW(x))]=(−log[p(y1∣fW(x))])+⋯+(−log[p(yK∣fW(x))])=L1+⋯+LK
因而,基于此就可以使用概率估计来融合各分任务的损失表达。
1️⃣ 连续类损失(回归)
⭐️以回归问题为例,讲解对连续类损失的处理方式。
假设回归问题的概率满足Gaussian分布,依此估计其概率,则有:
p
(
y
∣
f
W
(
x
)
,
σ
)
=
1
2
π
σ
e
−
(
y
−
f
W
(
x
)
)
2
2
σ
2
p(\mathbf{y|f^W(x),\sigma})=\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(y-f^W(x))^2}{2\sigma^2}}
p(y∣fW(x),σ)=2πσ1e−2σ2(y−fW(x))2
写成损失的形式:
−
log
(
y
∣
f
W
(
x
)
,
σ
)
=
(
y
−
f
W
(
x
)
)
2
2
σ
2
−
log
(
1
2
π
σ
)
≈
∥
y
−
f
W
(
x
)
∥
2
2
σ
2
+
log
(
σ
)
-\log(\mathbf{y|f^W(x),\sigma})={\frac{(y-f^W(x))^2}{2\sigma^2}}-\log(\frac{1}{\sqrt{2\pi}\sigma})\approx {\frac{\parallel y-f^W(x)\parallel_2}{2\sigma^2}}+\log({\sigma})
−log(y∣fW(x),σ)=2σ2(y−fW(x))2−log(2πσ1)≈2σ2∥y−fW(x)∥2+log(σ)
2️⃣ 离散类损失(分类)
⭐️以分类问题为例,讲解对离散类损失的处理方式。
使用Softmax对分类输出进行处理,依此估计其概率,其中
σ
\sigma
σ是一个尺度因子:
p
(
y
=
c
∣
f
W
(
x
)
,
σ
)
=
S
o
f
t
m
a
x
(
y
,
1
σ
2
f
W
(
x
)
)
=
e
1
σ
2
f
c
W
(
x
)
∑
c
′
e
1
σ
2
f
c
′
W
(
x
)
p(\mathbf{y}=c|\mathbf{f^W(x),\sigma})=Softmax(\mathbf{y},\frac{1}{\sigma^2}\mathbf{f^W(x)})=\displaystyle \frac{e^{\frac{1}{\sigma^2}f^W_c(\mathbf{x})}}{\sum_{c'}e^{\frac{1}{\sigma^2}f^W_{c'}(\mathbf{x})}}
p(y=c∣fW(x),σ)=Softmax(y,σ21fW(x))=∑c′eσ21fc′W(x)eσ21fcW(x)
写成损失的形式:
−
log
(
p
(
y
=
c
∣
f
W
(
x
)
,
σ
)
)
=
−
1
σ
2
f
c
W
(
x
)
+
log
(
∑
c
′
e
1
σ
2
f
c
′
W
(
x
)
)
-\log(p(\mathbf{y}=c|\mathbf{f^W(x),\sigma}))=-\frac{1}{\sigma^2}f^W_c(\mathbf{x})+\log({\sum_{c'}e^{\frac{1}{\sigma^2}f^W_{c'}(\mathbf{x})}})
−log(p(y=c∣fW(x),σ))=−σ21fcW(x)+log(∑c′eσ21fc′W(x))
3️⃣ 多任务损失组合
⭐️假设有两个任务:回归任务1(连续),分类任务2(离散),则有:
L
(
W
,
σ
1
,
σ
2
)
=
−
log
(
p
(
y
1
,
y
2
=
c
∣
f
W
(
x
)
)
)
=
−
log
[
(
1
2
π
σ
1
e
−
(
y
1
−
f
W
(
x
)
)
2
2
σ
1
2
)
⋅
(
e
1
σ
2
2
f
c
W
(
x
)
∑
c
′
e
1
σ
2
2
f
c
′
W
(
x
)
)
]
=
∥
y
1
−
f
W
(
x
)
∥
2
2
σ
1
2
+
log
(
σ
1
)
−
1
σ
2
2
f
c
W
(
x
)
+
log
(
∑
c
′
e
1
σ
2
2
f
c
′
W
(
x
)
)
=
∥
y
1
−
f
W
(
x
)
∥
2
2
σ
1
2
+
log
(
σ
1
)
+
[
−
1
σ
2
2
f
c
W
(
x
)
+
1
σ
2
2
log
(
∑
c
′
e
f
c
′
W
(
x
)
)
]
−
1
σ
2
2
log
(
∑
c
′
e
f
c
′
W
(
x
)
)
+
log
(
∑
c
′
e
1
σ
2
2
f
c
′
W
(
x
)
)
=
1
2
σ
1
2
L
1
(
W
)
+
1
σ
2
2
L
2
(
W
)
+
log
(
σ
1
)
+
log
[
∑
c
′
e
1
σ
2
2
f
c
′
W
(
x
)
(
∑
c
′
e
f
c
′
W
(
x
)
)
1
σ
2
2
]
≈
1
2
σ
1
2
L
1
(
W
)
+
1
σ
2
2
L
2
(
W
)
+
log
(
σ
1
)
+
log
(
σ
2
)
L(\mathbf{W},\sigma_1,\sigma_2)\\=-\log(p(\mathbf{y_1,y_2}={c}|\mathbf{f^W(x)}))\\=-\log[(\frac{1}{\sqrt{2\pi}\sigma_1}e^{-\frac{(y_1-f^W(x))^2}{2\sigma_1^2}})\cdot(\displaystyle \frac{e^{\frac{1}{\sigma_2^2}f^W_c(\mathbf{x})}}{\sum_{c'}e^{\frac{1}{\sigma_2^2}f^W_{c'}(\mathbf{x})}})]\\={\frac{\parallel y_1-f^W(x)\parallel_2}{2\sigma_1^2}}+\log({\sigma_1})-\frac{1}{\sigma_2^2}f^W_c(\mathbf{x})+\log({\sum_{c'}e^{\frac{1}{\sigma_2^2}f^W_{c'}(\mathbf{x})}}) \\ ={\frac{\parallel y_1-f^W(x)\parallel_2}{2\sigma_1^2}}+\log({\sigma_1})+[-\frac{1}{\sigma_2^2}f^W_c(\mathbf{x})+\frac{1}{\sigma_2^2}\log(\sum_{c'}e^{f^W_{c'}(x)})]-\frac{1}{\sigma_2^2}\log(\sum_{c'}e^{f^W_{c'}(x)})+\log({\sum_{c'}e^{\frac{1}{\sigma_2^2}f^W_{c'}(\mathbf{x})}}) \\ =\frac{1}{2\sigma_1^2}L_1(\mathbf{W})+\frac{1}{\sigma_2^2}L_2(\mathbf{W})+\log(\sigma_1)+\log[\frac{\sum_{c'}e^{\frac{1}{\sigma_2^2}f^W_{c'}(\mathbf{x})}}{(\sum_{c'}e^{f^W_{c'}(\mathbf{x})})^\frac{1}{\sigma_2^2}}]\\\approx \frac{1}{2\sigma_1^2}L_1(\mathbf{W})+\frac{1}{\sigma_2^2}L_2(\mathbf{W})+\log(\sigma_1)+\log(\sigma_2)
L(W,σ1,σ2)=−log(p(y1,y2=c∣fW(x)))=−log[(2πσ11e−2σ12(y1−fW(x))2)⋅(∑c′eσ221fc′W(x)eσ221fcW(x))]=2σ12∥y1−fW(x)∥2+log(σ1)−σ221fcW(x)+log(c′∑eσ221fc′W(x))=2σ12∥y1−fW(x)∥2+log(σ1)+[−σ221fcW(x)+σ221log(c′∑efc′W(x))]−σ221log(c′∑efc′W(x))+log(c′∑eσ221fc′W(x))=2σ121L1(W)+σ221L2(W)+log(σ1)+log[(∑c′efc′W(x))σ221∑c′eσ221fc′W(x)]≈2σ121L1(W)+σ221L2(W)+log(σ1)+log(σ2)
其中,
{
L
1
(
W
)
=
∥
y
1
−
f
W
(
x
)
∥
2
L
2
(
W
)
=
−
log
[
S
o
f
t
m
a
x
(
y
2
,
f
W
(
x
)
)
]
=
−
log
(
e
f
c
W
(
x
)
∑
c
′
e
f
c
′
W
(
x
)
)
1
σ
2
2
∑
c
′
e
1
σ
2
2
f
c
′
W
(
x
)
≈
(
∑
c
′
e
f
c
′
W
(
x
)
)
1
σ
2
2
\begin{cases}L_1(\mathbf{W})=\parallel y_1-f^W(x)\parallel_2\\L_2(\mathbf{W})=-\log[Softmax(y_2,f^W(x))]=-\log(\displaystyle \frac{e^{f^W_c(\mathbf{x})}}{\sum_{c'}e^{f^W_{c'}(\mathbf{x})}})\\\frac{1}{\sigma_2^2}\sum_{c'}e^{\frac{1}{\sigma^2_2}f^W_{c'}(x)}\approx(\sum_{c'}e^{f^W_{c'}(\mathbf{x})})^\frac{1}{\sigma_2^2}\end{cases}
⎩
⎨
⎧L1(W)=∥y1−fW(x)∥2L2(W)=−log[Softmax(y2,fW(x))]=−log(∑c′efc′W(x)efcW(x))σ221∑c′eσ221fc′W(x)≈(∑c′efc′W(x))σ221
4️⃣ 实际操作中的近似处理
⭐️最后,在实际操作中,通过预测
s
:
=
log
(
σ
2
)
s:=\log(\sigma^2)
s:=log(σ2)来代替预测
σ
2
\sigma^2
σ2,因为这样在数值上更加稳定,而且没有除0等问题,则最后多任务损失可以近似写成:
L
(
W
,
s
1
,
s
2
)
=
1
e
s
1
L
1
(
W
)
+
1
e
s
2
L
2
(
W
)
+
s
1
+
s
2
L(\mathbf{W},s_1,s_2)=\frac{1}{e^{s_1}}L_1(\mathbf{W})+\frac{1}{e^{s_2}}L_2(\mathbf{W})+s_1+s_2
L(W,s1,s2)=es11L1(W)+es21L2(W)+s1+s2


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









