







🚀模型推理速度至关重要,一般在论文中,我们会看到的指标有计算量FLOPs和参数量Params,但是请大家注意在模型实际落地应用时,还必须关注访存量QPS。
🌔01
学术界与工业界中的模型速度
大部分时候,对于GPU,算力瓶颈在于访存带宽。而同种计算量,访存数据量差异巨大。
① {\color{#E16B8C}{①}} ①在学术界中,模型速度主要以计算量FLOPs和参数量Params来表示。
② {\color{#E16B8C}{②}} ②在工业界中,模型速度考虑的是GPU显存占满情况下的访存量QPS(queries per second)。
因而学术界中,使用相同的batch_size比较不同模型有时候也是不公平的,而应该让各自的模型使用占满显存的batch_size进行比较。
💡举个例子:
EfficientNet-b3,batchsize=16,测试QPS=268;
ResNet50,batchsize=16,测试QPS=416。
416/268=1.55
EfficientNet-b3,占满P40显存,batchsize=600,测试QPS=296;
ResNet50,占满P40显存,batchsize=1700,测试QPS=511。
511/296=1.73
⭐️总之,在估计模型速度时,参数量(Params)是绝对正确的,但计算量(FLOPs)和访存量(QPS)都只侧重一个方面,要联合起来看才完整。
🌔02
注意力模块与模型速度
运用了注意力机制的模型为什么在实际跑的慢?
以 x = x ∗ σ ( x ) x=x*\sigma(x) x=x∗σ(x)注意力为例。虽然其可以筛选出重要的信息,减少后续传播的负担,但是在执行注意力操作时,需要把 x x x的tensor复制一份计算 σ ( x ) \sigma(x) σ(x),这使得显存占用增加。因而在考虑显存占满限制条件下的工业界,使用注意力模块反而会降低速度。
🌔03
深度可分离卷积与模型速度
Depthwise(DW)卷积与Pointwise(PW)卷积,合起来被称作深度可分离卷积
3.1 普通卷积/DW卷积/PW卷积
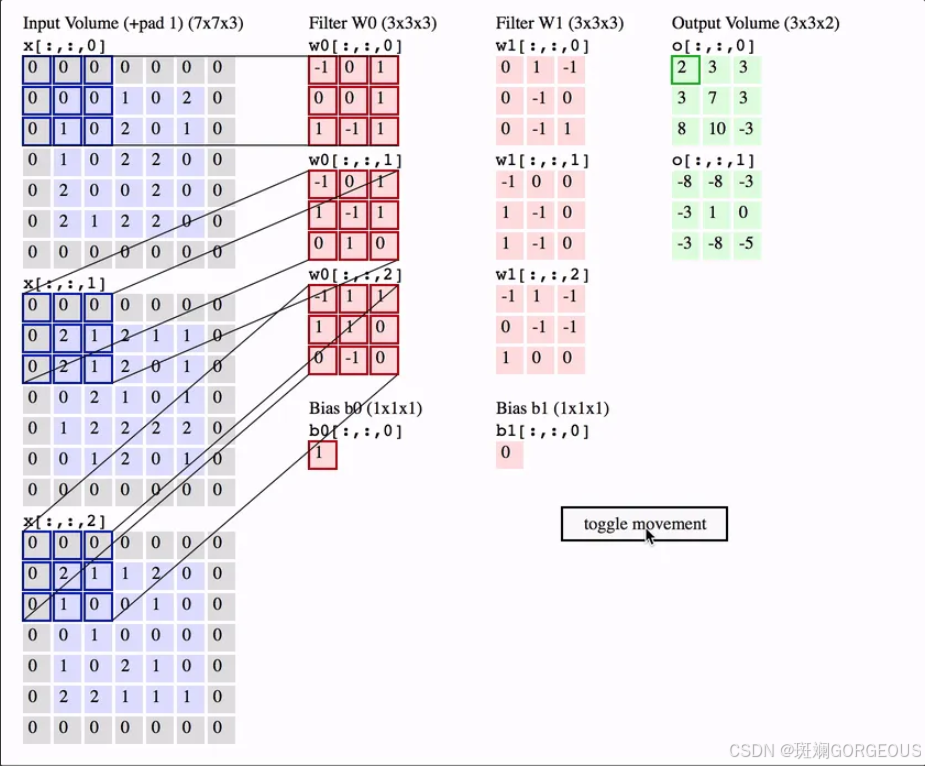
① {\color{#E16B8C}{①}} ①对于普通卷积。对于 ( o , k , k , i ) (o,k,k,i) (o,k,k,i)的卷积(尺度为 k × k × i k\times k\times i k×k×i)而言,首先是有 o o o个卷积核,每个卷积核负责输出的一个通道。每个卷积核通道与输入通道一一对应。对多个输入通道执行常规2D卷积,卷积核的通道数与输入的通道数一致,我们会混合所有通道(对应位置相加)来产生最后的一个输出,以输出通道0为例:
o
[
:
,
:
,
0
]
=
∑
j
i
x
[
:
,
:
,
j
]
w
0
[
:
,
:
,
j
]
o[:,:,0]=\sum_j^ix[:,:,j]w0[:,:,j]
o[:,:,0]=j∑ix[:,:,j]w0[:,:,j]
②
{\color{#E16B8C}{②}}
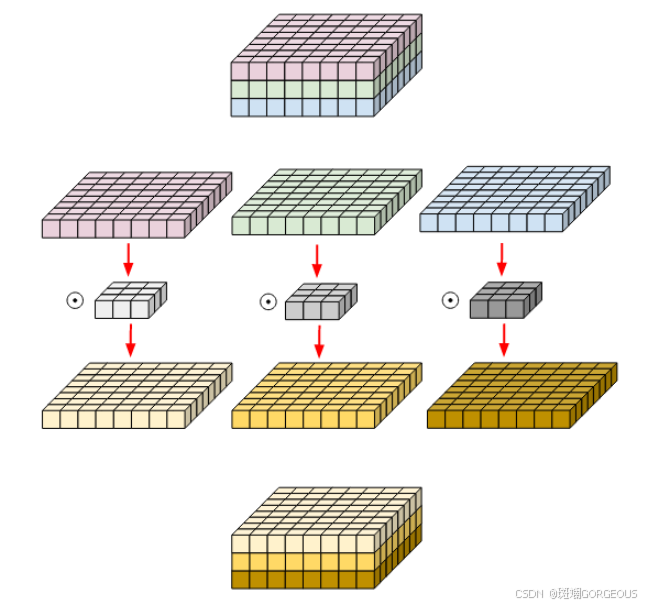
②对于Depthwise卷积。它的输入输出特征图的通道数是相同的(即保持通道数不变)。采用
k
×
k
×
i
k\times k\times i
k×k×i的卷积核。先将输入特征图和卷积核都按照通道分层,然后逐层卷积,各层的结果直接concat起来(普通卷积是相加作为一层的结果)。
③
{\color{#E16B8C}{③}}
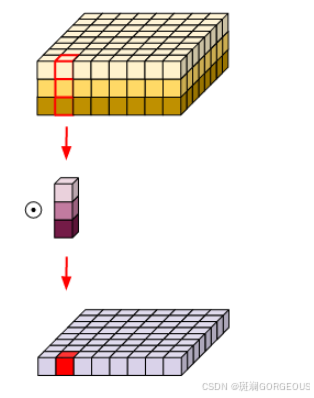
③对于Pointwise卷积。它能保持特征图的HW不变,只改变通道数。采用
1
×
1
×
i
1\times 1\times i
1×1×i的卷积核,做普通卷积。
3.2 实例说明
① {\color{#E16B8C}{①}} ①假设有输入特征大小为 128 × 128 × 3 128\times128\times3 128×128×3,要求输出通道数为16。设卷积核尺寸为3。
普通卷积:
参数量: 3 × 3 × 3 × 16 = 432 3\times3\times3\times16=432 3×3×3×16=432
计算量(只考虑乘法): ( 3 × 3 × 3 × 16 ) × 128 × 128 ≈ 7 e 6 (3\times3\times3\times16)\times128\times128\approx7e6 (3×3×3×16)×128×128≈7e6
深度可分离卷积:
参数量: ( 3 × 3 × 3 × 1 ) + ( 1 × 1 × 3 × 16 ) = 75 (3\times3\times3\times1)+(1\times1\times3\times16)=75 (3×3×3×1)+(1×1×3×16)=75
计算量(只考虑乘法): [ ( 3 × 3 × 3 × 1 ) + ( 1 × 1 × 3 × 16 ) ] × 128 × 128 ≈ 1.2 e 6 [(3\times3\times3\times1)+(1\times1\times3\times16)]\times128\times128\approx1.2e6 [(3×3×3×1)+(1×1×3×16)]×128×128≈1.2e6
可见,深度可分离卷积的参数量和计算量比普通卷积会小很多,因而网络可以做的更深,从而拥有更高的准确率。但推理速度呢?
② {\color{#E16B8C}{②}} ②我们限制普通卷积和可分离卷积的参数量和计算量(只考虑乘法)一致,再来推导一下。
这里为了方便计算:访存量 ≈ \approx ≈输入特征图大小+卷积参数量
普通卷积: 假设有输入特征大小为 128 × 128 × 3 128\times128\times3 128×128×3,要求输出通道数为16。设卷积核尺寸为3。
参数量: 3 × 3 × 3 × 16 = 432 3\times3\times3\times16=432 3×3×3×16=432
计算量(只考虑乘法): ( 3 × 3 × 3 × 16 ) × 128 × 128 ≈ 7 e 6 (3\times3\times3\times16)\times128\times128\approx7e6 (3×3×3×16)×128×128≈7e6
访存量: ( 128 × 128 × 3 ) + ( 3 × 3 × 3 × 16 ) ≈ 5 e 4 (128\times128\times3)+(3\times3\times3\times16)\approx5e4 (128×128×3)+(3×3×3×16)≈5e4
深度可分离卷积: 假设有输入特征大小为 128 × 128 × 36 128\times128\times36 128×128×36,要求输出通道数为3。设卷积核尺寸为3。
参数量: ( 3 × 3 × 36 × 1 ) + ( 1 × 1 × 36 × 3 ) = 432 (3\times3\times36\times1)+(1\times1\times36\times3)=432 (3×3×36×1)+(1×1×36×3)=432
计算量(只考虑乘法): [ ( 3 × 3 × 36 × 1 ) + ( 1 × 1 × 36 × 3 ) ] × 128 × 128 ≈ 7 e 6 [(3\times3\times36\times1)+(1\times1\times36\times3)]\times128\times128\approx7e6 [(3×3×36×1)+(1×1×36×3)]×128×128≈7e6
访存量: ( 128 × 128 × 36 ) + [ ( 3 × 3 × 36 × 1 ) + ( 1 × 1 × 36 × 3 ) ] ≈ 6 e 5 (128\times128\times36)+[(3\times3\times36\times1)+(1\times1\times36\times3)]\approx6e5 (128×128×36)+[(3×3×36×1)+(1×1×36×3)]≈6e5
可见,在普通卷积和深度可分离卷积参数量和计算量一致情况下,深度可分离卷积比普通卷积的访存量大得多,这成为了限制其推理速度的瓶颈。
🔔究其原因,猜测是深度可分离卷积使用了DW卷积这一具有“element-wise”性质的操作,与普通卷积“matrix multiplication”性质相比,其数据复用率不高。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









