







搜索也是很常考的题目,有些搜索要求一些高级的数据结构来加速搜索过程,比如Trie Tree,并查集Union Find等等。我们先来看看Trie Tree,Trie Tree其实就是一种树结构,它的好处就是用来查找前缀,每个子节点存放一个字母,然后每个子节点有一个标记用于标记这个子节点是否是一个单词的结尾。
并查集是用来解决集合查询合并的数据结构,一般用于检查2个点是否在同一个集合中,很常用于连通图的判断。它有2个操作,一个是find,也就是查找2个节点是不是有关联的。另一个操作就是union,把两个节点关联起来。find和union的操作可以是O(1)的时间复杂度的。可以用一个father数组来表示他们的关系,如下所示:
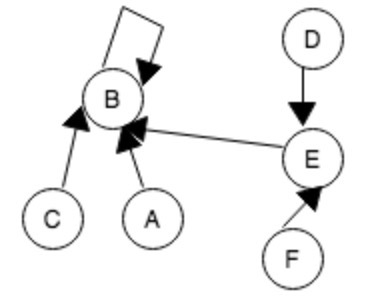
这种用并查集数组表现出来就是如下所示:
father数组:
| A | B | C | D | E | F |
| B | B | B | E | B | E |
并查集的模板代码如下:
class UnionFind {
HashMap<Integer, Integer> father = new HashMap<Integer, Integer>();
UnionFind(int n) {
for (int i = 0; i < n; i++) {
father.put(i, i);
}
}
int fast_find(int x){
int parent = father.get(x);
while (parent != father.get(parent)) {
parent = father.get(parent);
}
int next;
while (x != father.get(x)) {
next = father.get(x);
father.put(x, parent);
x = next;
}
return parent;
}
int find(int x) {
int parent = father.get(x);
while (parent != father.get(parent)) {
parent = father.get(parent);
}
return parent;
}
void union(int x, int y) {
int fa_x = find(x);
int fa_y = find(y);
if (fa_x != fa_y) {
father.put(fa_x, fa_y);
}
}
}
实现Trie树,以下是递归的方法:
/**
* Your Trie object will be instantiated and called as such:
* Trie trie = new Trie();
* trie.insert("lintcode");
* trie.search("lint"); will return false
* trie.startsWith("lint"); will return true
*/
class TrieNode {
// Initialize your data structure here.
public TrieNode[] son;
public boolean leaf;
public TrieNode() {
son = new TrieNode[26];
}
public void insert(String word, int level) {
if (level == word.length()) {
this.leaf = true;
return;
}
int pos = word.charAt(level) - 'a';
if (son[pos] == null) {
son[pos] = new TrieNode();
}
son[pos].insert(word, level + 1);
}
public TrieNode find(String word, int level) {
if (level == word.length()) {
return this;
}
int pos = word.charAt(level) - 'a';
if (son[pos] == null) {
return null;
}
return son[pos].find(word, level + 1);
}
}
public class Trie {
private TrieNode root;
public Trie() {
root = new TrieNode();
}
// Inserts a word into the trie.
public void insert(String word) {
root.insert(word, 0);
}
// Returns if the word is in the trie.
public boolean search(String word) {
TrieNode node = root.find(word, 0);
return (node != null && node.leaf == true);
}
// Returns if there is any word in the trie
// that starts with the given prefix.
public boolean startsWith(String prefix) {
TrieNode node = root.find(prefix, 0);
return (node != null);
}
}以下是迭代的方法:
/**
* Your Trie object will be instantiated and called as such:
* Trie trie = new Trie();
* trie.insert("lintcode");
* trie.search("lint"); will return false
* trie.startsWith("lint"); will return true
*/
class TrieNode {
// Initialize your data structure here.
public TrieNode[] son;
public boolean leaf;
public TrieNode() {
son = new TrieNode[26];
}
}
public class Trie {
private TrieNode root;
public Trie() {
root = new TrieNode();
}
// Inserts a word into the trie.
public void insert(String word) {
TrieNode node = root;
for (int i = 0; i < word.length(); i++) {
char c = word.charAt(i);
if (node.son[c - 'a'] == null) {
node.son[c - 'a'] = new TrieNode();
}
node = node.son[c - 'a'];
}
node.leaf = true;
}
// Returns if the word is in the trie.
public boolean search(String word) {
TrieNode node = root;
for (int i = 0; i < word.length(); i++) {
char c = word.charAt(i);
if (node.son[c - 'a'] == null) {
return false;
}
node = node.son[c - 'a'];
}
return (node.leaf == true);
}
// Returns if there is any word in the trie
// that starts with the given prefix.
public boolean startsWith(String prefix) {
TrieNode node = root;
for (int i = 0; i < prefix.length(); i++) {
char c = prefix.charAt(i);
if (node.son[c - 'a'] == null) {
return false;
}
node = node.son[c - 'a'];
}
return true;
}
}要求设计一个数据结构支持2种操作:Add(String s)和Search(String s),Add会把单词加进去,Search会查找那个单词是否存在。如果仅仅是这样的话,其实用一个HashSet就能实现了。但问题是,题目的要求比较特殊,.可以用来代表任意字母,所以,search(".ad")要能匹配任何类似于aad/bad/cad/.../yad/zad的单词。这样的话,就要利用到Trie Tree了。Insert的时候还是照旧,只不过search的时候就需要DFS了,因为当遇到的字符为.时,26个字母都需要遍历一遍。
class TrieNode {
public TrieNode[] son;
public boolean leaf;
public TrieNode() {
son = new TrieNode[26];
}
}
public class WordDictionary {
private TrieNode root;
public WordDictionary() {
root = new TrieNode();
}
// Adds a word into the data structure.
public void addWord(String word) {
TrieNode node = root;
for (int i = 0; i < word.length(); i++) {
char c = word.charAt(i);
if (node.son[c - 'a'] == null) {
node.son[c - 'a'] = new TrieNode();
}
node = node.son[c - 'a'];
}
node.leaf = true;
}
public boolean find(String word, TrieNode root, int index) {
if (index == word.length()) {
return root.leaf;
}
char c = word.charAt(index);
if (c == '.') {
for (int i = 0; i < 26; i++) {
if (root.son[i] != null) {
if (find(word, root.son[i], index + 1) == true) {
return true;
}
}
}
return false;
} else if (root.son[c - 'a'] != null) {
return find(word, root.son[c - 'a'], index + 1);
} else {
return false;
}
}
// Returns if the word is in the data structure. A word could
// contain the dot character '.' to represent any one letter.
public boolean search(String word) {
return find(word, root, 0);
}
}
// Your WordDictionary object will be instantiated and called as such:
// WordDictionary wordDictionary = new WordDictionary();
// wordDictionary.addWord("word");
// wordDictionary.search("pattern");
给出一个包含多个字符串的String数组,要求凑成一个square,这个square的第N行所形成的单词跟第N列所形成的单词是一样的(N从0到矩阵末尾)。要求出能形成多少个这样的square。暴力解法自然是暴力穷举,然后对每一个combination运用valid word squares(请参见leetcode 422)里面的方法来验证是否符合。但是这样肯定就超时了。首先这道题肯定是要用DFS搜索来解决的,因为你需要挑选几个字符串来凑出矩阵。但是有没有什么规律呢?其实是有规律的。lc大神给出了它找到的规律:https://discuss.leetcode.com/topic/63516/explained-my-java-solution-using-trie-126ms-16-16
当找到第一个单词后,第二个单词的第一个字母必须以第一个单词的第二个字母开头,第三个单词的前2个字母必须分别来自第一个和第二个单词的第三个字母,以此类推。这种前缀树,就可以利用到Trie树。只不过在建立Trie树的时候,每个节点都存入所有以它为前缀的单词。这样在搜索的时候就可以加快时间,直接取出Trie树的节点来获取潜在的下一步搜索状态。
class TrieNode {
public TrieNode[] son;
public ArrayList<String> prefixWords;
public TrieNode() {
son = new TrieNode[26];
prefixWords = new ArrayList<String>();
}
}
class Trie {
public TrieNode root;
public Trie(String[] words) {
root = new TrieNode();
for (String word: words) {
TrieNode node = root;
for (int i = 0; i < word.length(); i++) {
char c = word.charAt(i);
if (node.son[c - 'a'] == null) {
node.son[c - 'a'] = new TrieNode();
}
node.son[c - 'a'].prefixWords.add(word);
node = node.son[c - 'a'];
}
}
}
public ArrayList<String> findWordsByPrefix(String prefix) {
ArrayList<String> res = new ArrayList<String>();
TrieNode node = root;
int i;
for (i = 0; i < prefix.length(); i++) {
char c = prefix.charAt(i);
if (node.son[c - 'a'] != null) {
node = node.son[c - 'a'];
} else {
break;
}
}
if (i == prefix.length()) {
res.addAll(node.prefixWords);
}
return res;
}
}
public class Solution {
/**
* @param words a set of words without duplicates
* @return all word squares
*/
public List<List<String>> wordSquares(String[] words) {
List<List<String>> res = new ArrayList<List<String>>();
if (words == null || words.length == 0) {
return res;
}
List<String> square = new ArrayList<String>();
Trie trie = new Trie(words);
for (String word: words) {
square.add(word);
dfs(res, square, trie, words[0].length());
square.remove(square.size() - 1);
}
return res;
}
public void dfs(List<List<String>> res, List<String> square, Trie trie, int len) {
if (square.size() == len) {
res.add(new ArrayList<String>(square));
return;
}
int index = square.size();
StringBuilder sb = new StringBuilder();
for (String s: square) {
sb.append(s.charAt(index));
}
ArrayList<String> prefixWords = trie.findWordsByPrefix(sb.toString());
for (String word: prefixWords) {
square.add(word);
dfs(res, square, trie, len);
square.remove(square.size() - 1);
}
}
}
这题基本就是实现Union Find,没啥好说的。
跟上题稍有变化,对于某一个节点,要求出包含这个节点的connected component里面总共有多少个节点。所以基于基本的并查集,我们还需要加一个HashMap用于记录那个集合里面有多少个节点存在。size HashMap就用于记录对应节点所在的集合的节点数,只不过这个节点数只存在于大boss节点上。所以需要先找到大boss节点然后再取出节点数量。
public class ConnectingGraph2 {
HashMap<Integer, Integer> father = new HashMap<Integer, Integer>();
HashMap<Integer, Integer> size = new HashMap<Integer, Integer>();
public ConnectingGraph2(int n) {
// initialize your data structure here.
for (int i = 1; i <= n; i++) {
father.put(i, i);
size.put(i, 1);
}
}
public int find(int x) {
int parent = x;
while (parent != father.get(parent)) {
parent = father.get(parent);
}
return parent;
}
public void connect(int a, int b) {
int father_a = find(a);
int father_b = find(b);
if (father_a != father_b) {
father.put(father_a, father_b);
size.put(father_b, size.get(father_a) + size.get(father_b));
}
}
public int query(int a) {
return size.get(find(a));
}
}跟上提又有点类似,只不过要求出总共有多少个connected component。代码中要改的地方,就在于添加一个count,每次把两个点union到一起的时候,count就减一。
public class ConnectingGraph3 {
private HashMap<Integer, Integer> father = new HashMap<Integer, Integer>();
private int count;
public ConnectingGraph3(int n) {
for (int i = 1; i <= n; i++) {
father.put(i, i);
}
count = n;
}
public int find(int x) {
int parent = x;
while (parent != father.get(parent)) {
parent = father.get(parent);
}
return parent;
}
public void connect(int a, int b) {
int fa_a = find(a);
int fa_b = find(b);
if (fa_a != fa_b) {
father.put(fa_a, fa_b);
count--;
}
}
public int query() {
return count;
}
}给定一些节点和一些边,判断他们所组成的是不是树。树和图的区别就是树没有环,而图有环。树的边的数量是节点数量减去一。根据这两个条件就能判断是不是树了。然后可以利用并查集来解决,因为给出了一些边。然后可以用并查集的union操作来模拟建树的过程。如果union的过程中发现两个节点的father是同一个,就返回false:
public class Solution {
/**
* @param n an integer
* @param edges a list of undirected edges
* @return true if it's a valid tree, or false
*/
class UnionFind {
HashMap<Integer, Integer> father = new HashMap<Integer, Integer>();
UnionFind(int n) {
for (int i = 0; i < n; i++) {
father.put(i, i);
}
}
int fast_find(int x){
int parent = father.get(x);
while (parent != father.get(parent)) {
parent = father.get(parent);
}
int next;
while (x != father.get(x)) {
next = father.get(x);
father.put(x, parent);
x = next;
}
return parent;
}
int find(int x) {
int parent = father.get(x);
while (parent != father.get(parent)) {
parent = father.get(parent);
}
return parent;
}
void union(int x, int y) {
int fa_x = find(x);
int fa_y = find(y);
if (fa_x != fa_y) {
father.put(fa_x, fa_y);
}
}
}
public boolean validTree(int n, int[][] edges) {
if (edges.length != n - 1) {
return false;
}
UnionFind uf = new UnionFind(n);
for (int i = 0; i < edges.length; i++) {
if (uf.fast_find(edges[i][0]) == uf.fast_find(edges[i][1])) {
return false;
}
uf.union(edges[i][0], edges[i][1]);
}
return true;
}
}求无向图的所有的连通块。这道题有2种解法,一种是BFS(http://blog.csdn.net/luoshengkim/article/details/51712773). 还有一种方法就是并查集。其实这道题用BFS会简单一点,并查集反而显得比较啰嗦。并查集的思路就是先把所有的点都找到存到一个HashSet里面,然后再利用这个HashSet来建立并查集。逐个的遍历每个节点,把有关联的节点union起来。然后把并查集里面的所有连通块都打印出来即可。
432. Find the Weak Connected Component in the Directed Graph
求有向图里面的弱连通块。这道题是没法用BFS来解决的,因为通过一个节点搜索并不能找到所有跟它关联的节点。其实解法跟上题用并查集的解法一模一样。先用双重循环把所有的节点都加入到HashSet里面,再用双重循环把它们的边加到并查集里。然后再利用fast find的方法,把所有的在一个连通图里的节点都指向同一个父节点。然后再遍历并查集,把所有的属于同一个连通块的节点都拿出来,排好序,返回。
/**
* Definition for Directed graph.
* class DirectedGraphNode {
* int label;
* ArrayList<DirectedGraphNode> neighbors;
* DirectedGraphNode(int x) { label = x; neighbors = new ArrayList<DirectedGraphNode>(); }
* };
*/
public class Solution {
/**
* @param nodes a array of Directed graph node
* @return a connected set of a directed graph
*/
class UnionFind {
HashMap<Integer, Integer> father = new HashMap<Integer, Integer>();
UnionFind(HashSet<Integer> set) {
for (Integer tmp : set) {
father.put(tmp, tmp);
}
}
int find(int a) {
int parent = father.get(a);
while (parent != father.get(parent)) {
parent = father.get(parent);
}
return parent;
}
void union(int a, int b) {
int father_a = find(a);
int father_b = find(b);
if (father_a != father_b) {
father.put(father_a, father_b);
}
}
}
public List<List<Integer>> connectedSet2(ArrayList<DirectedGraphNode> nodes) {
HashSet<Integer> set = new HashSet<Integer>();
for (DirectedGraphNode node : nodes) {
set.add(node.label);
for (DirectedGraphNode neighbor : node.neighbors) {
set.add(neighbor.label);
}
}
UnionFind uf = new UnionFind(set);
for (DirectedGraphNode node : nodes) {
for (DirectedGraphNode neighbor : node.neighbors) {
int parent_a = uf.find(node.label);
int parent_b = uf.find(neighbor.label);
if (parent_a != parent_b) {
uf.union(node.label, neighbor.label);
}
}
}
for (Integer key : uf.father.keySet()) {
int parent = uf.father.get(key);
while (parent != uf.father.get(parent)) {
parent = uf.father.get(parent);
}
uf.father.put(key, parent);
}
HashMap<Integer, List<Integer> > map = new HashMap();
for (Integer tmp : uf.father.keySet()) {
int key = uf.father.get(tmp);
if (map.containsKey(key)) {
map.get(key).add(tmp);
} else {
List<Integer> list = new ArrayList<Integer>();
list.add(tmp);
map.put(key, list);
}
}
List<List<Integer>> res = new ArrayList();
for (List<Integer> list : map.values()) {
Collections.sort(list);
res.add(list);
}
return res;
}
}给一个矩阵,1代表陆地,0代表海洋,求问矩阵中有多少个岛屿。其实最简单的方法就是用DFS,没遇到一个1,就用DFS搜索,把所有跟他相连的岛屿全部变为海洋。每次用DFS的时候就记录一下岛屿数目。这样就能得到结果了。不过问题是会影响到原数组的状态,也就是说会改变原数组的值。
public void dfs(boolean[][] grid, int i, int j) {
if (i < 0 || i >= grid.length || j < 0 || j >= grid[0].length || grid[i][j] == false) {
return;
}
if (grid[i][j] == true) {
grid[i][j] = false;
dfs(grid, i, j + 1);
dfs(grid, i, j - 1);
dfs(grid, i + 1, j);
dfs(grid, i - 1, j);
}
}
public int numIslands(boolean[][] grid) {
int count = 0;
for (int i = 0; i < grid.length; i++) {
for (int j = 0; j < grid[0].length; j++) {
if (grid[i][j] == true) {
dfs(grid, i, j);
count++;
}
}
}
return count;
}class UnionFind {
public HashMap<Integer, Integer> father = new HashMap<Integer, Integer>();
public int count;
public UnionFind(int c, int n) {
count = c;
for (int i = 0; i < n; i++) {
father.put(i, i);
}
}
public int find(int a) {
int parent = father.get(a);
while (parent != father.get(parent)) {
parent = father.get(parent);
}
return parent;
}
public void union(int a, int b) {
int fa = find(a);
int fb = find(b);
if (fa != fb) {
father.put(fa, fb);
count--;
}
}
}
public class Solution {
/**
* @param grid a boolean 2D matrix
* @return an integer
*/
public boolean valid(boolean[][] grid, int i, int j) {
if (i < 0 || i >= grid.length || j < 0 || j >= grid[0].length) {
return false;
}
return (grid[i][j] == true);
}
public int numIslands(boolean[][] grid) {
// corner case
if (grid == null || grid.length == 0 || grid[0].length == 0) {
return 0;
}
// count is the number of 1
int count = 0;
for (int i = 0; i < grid.length; i++) {
for (int j = 0; j < grid[0].length; j++) {
if (grid[i][j] == true) {
count++;
}
}
}
// update count to number of islands
int n = grid.length, m = grid[0].length;
UnionFind uf = new UnionFind(count, n * m);
for (int i = 0; i < grid.length; i++) {
for (int j = 0; j < grid[0].length; j++) {
if (grid[i][j] == true) {
int boss = i * m + j;
if (valid(grid, i + 1, j)) {
int v = (i + 1) * m + j;
uf.union(boss, v);
}
if (valid(grid, i - 1, j)) {
int v = (i - 1) * m + j;
uf.union(boss, v);
}
if (valid(grid, i, j + 1)) {
int v = i * m + j + 1;
uf.union(boss, v);
}
if (valid(grid, i, j - 1)) {
int v = i * m + j - 1;
uf.union(boss, v);
}
}
}
}
return uf.count;
}
}一个矩阵一开始全部都是0,然后给定一个数组,可以一连串的把0变成1,问每次这样的操作后海洋里有多少岛屿。假如数组长度为K,如果是brute force的方法,那就是每次来一个变化后,都用DFS搜索一下矩阵里的岛屿数目,这样的话时间复杂度就是O(k*m*n)。其实可以用并查集来做,首先得把二维的数组转换为一维的数组。每次新来一个操作的时候,都先把count加一。然后再基于这个新来的元素的位置,只对它上下左右四个方向的邻居进行union操作,如果能够连接起来,那就count减一。
/**
* Definition for a point.
* class Point {
* int x;
* int y;
* Point() { x = 0; y = 0; }
* Point(int a, int b) { x = a; y = b; }
* }
*/
class UnionFind {
public Map<Integer, Integer> father = new HashMap<Integer, Integer>();
public int count;
public UnionFind(int c, int n) {
count = c;
for (int i = 0; i < n; i++) {
father.put(i, i);
}
}
public int find(int a) {
int parent = father.get(a);
while (parent != father.get(parent)) {
parent = father.get(parent);
}
return parent;
}
public void union(int a, int b) {
int fa = find(a);
int fb = find(b);
if (fa != fb) {
father.put(fa, fb);
count--;
}
}
}
public class Solution {
/**
* @param n an integer
* @param m an integer
* @param operators an array of point
* @return an integer array
*/
public boolean valid(boolean[] grid, int n, int m, int x, int y) {
if (x < 0 || x >= n || y < 0 || y >= m) {
return false;
}
return (grid[x * m + y] == true);
}
public List<Integer> numIslands2(int n, int m, Point[] operators) {
List<Integer> res = new ArrayList<Integer>();
if (operators == null || operators.length == 0) {
return res;
}
boolean[] grid = new boolean[n * m];
UnionFind uf = new UnionFind(0, n * m);
for (Point p: operators) {
int x = p.x, y = p.y;
int boss = x * m + y;
// avoid duplicate union
if (grid[boss] == true) {
res.add(uf.count);
continue;
}
grid[boss] = true;
uf.count++;
if (valid(grid, n, m, x + 1, y)) {
int v = (x + 1) * m + y;
uf.union(boss, v);
}
if (valid(grid, n, m, x - 1, y)) {
int v = (x - 1) * m + y;
uf.union(boss, v);
}
if (valid(grid, n, m, x, y + 1)) {
int v = x * m + y + 1;
uf.union(boss, v);
}
if (valid(grid, n, m, x, y - 1)) {
int v = x * m + y - 1;
uf.union(boss, v);
}
res.add(uf.count);
}
return res;
}
}给定一个只由O和X两种字符组成的矩阵,如果O组成的区域的外围全部被X包围了,那么区域内的O全部就会被同化成X。求出被同化后的矩阵。这道题的思想其实很简单,从边缘出发,如果边缘的点是O,那么从这个边缘的O出发往里面BFS搜索,所有能到达的O点都不会被同化。BFS详细思路可参考:https://discuss.leetcode.com/topic/15511/simple-bfs-solution-easy-to-understand 还有一种是用并查集来做:https://discuss.leetcode.com/topic/1944/solve-it-using-union-find/2 我的代码如下:
class Point {
public int row;
public int col;
public Point(int r, int c) {
row = r;
col = c;
}
}
public class Solution {
/**
* @param board a 2D board containing 'X' and 'O'
* @return void
*/
public boolean valid(char[][] board, int r, int c) {
if (r >= 0 && r < board.length && c >= 0 && c < board[0].length) {
return true;
}
return false;
}
public void surroundedRegions(char[][] board) {
Queue<Point> queue = new LinkedList<Point>();
if (board == null || board.length == 0 || board[0].length == 0) {
return;
}
// Put all edges into queue
for (int i = 0; i < board[0].length; i++) {
if (board[0][i] == 'O') {
board[0][i] = 'A';
queue.add(new Point(0, i));
}
if (board[board.length - 1][i] == 'O') {
board[board.length - 1][i] = 'A';
queue.add(new Point(board.length - 1, i));
}
}
for (int i = 1; i < board.length - 1; i++) {
if (board[i][0] == 'O') {
board[i][0] = 'A';
queue.add(new Point(i, 0));
}
if (board[i][board[0].length - 1] == 'O') {
board[i][board[0].length - 1] = 'A';
queue.add(new Point(i, board[0].length - 1));
}
}
while (!queue.isEmpty()) {
Point head = queue.poll();
int row = head.row, col = head.col;
if (valid(board, row + 1, col) && board[row + 1][col] == 'O') {
board[row + 1][col] = 'A';
queue.add(new Point(row + 1, col));
}
if (valid(board, row - 1, col) && board[row - 1][col] == 'O') {
board[row - 1][col] = 'A';
queue.add(new Point(row - 1, col));
}
if (valid(board, row, col + 1) && board[row][col + 1] == 'O') {
board[row][col + 1] = 'A';
queue.add(new Point(row, col + 1));
}
if (valid(board, row, col - 1) && board[row][col - 1] == 'O') {
board[row][col - 1] = 'A';
queue.add(new Point(row, col - 1));
}
}
for (int i = 0; i < board.length; i++) {
for (int j = 0; j < board[0].length; j++) {
if (board[i][j] == 'O') {
board[i][j] = 'X';
} else if (board[i][j] == 'A') {
board[i][j] = 'O';
}
}
}
}
}















 423
423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









