







 转载请注明出处:半同步/半异步: memcached使用半同步/半异步网络模型处理客户端的连接和通信。 半同步/半异步模型的基础设施:主线程创建多个子线程(这些子线程也称为worker线程),每一个线程都维持自己的事件循环,即每个线程都有自己的epoll,并且都会调用epoll_wait函数进入事件监听状态。每一个worker线程(子线程)和
转载请注明出处:半同步/半异步: memcached使用半同步/半异步网络模型处理客户端的连接和通信。 半同步/半异步模型的基础设施:主线程创建多个子线程(这些子线程也称为worker线程),每一个线程都维持自己的事件循环,即每个线程都有自己的epoll,并且都会调用epoll_wait函数进入事件监听状态。每一个worker线程(子线程)和
转载请注明出处:http://blog.csdn.net/luotuo44/article/details/42705475
accept/dispatch:
memcached使用"主线程统一accept/dispatch子线程"网络模型处理客户端的连接和通信,也就是《UNIX网络编程 卷1 第三版》第30章里面的第8个模型。
"主线程统一accept/dispatch子线程"的基础设施:主线程创建多个子线程(这些子线程也称为worker线程),每一个线程都维持自己的事件循环,即每个线程都有自己的epoll,并且都会调用epoll_wait函数进入事件监听状态。每一个worker线程(子线程)和主线程之间都用一条管道相互通信。每一个子线程都监听自己对应那条管道的读端。当主线程想和某一个worker线程进行通信,直接往对应的那条管道写入数据即可。
"主线程统一accept/dispatch子线程"模型的工作流程:主线程负责监听进程对外的TCP监听端口。当客户端申请连接connect到进程的时候,主线程负责接收accept客户端的连接请求。然后主线程选择其中一个worker线程,把客户端fd通过对应的管道传给worker线程。worker线程得到客户端的fd后负责和这个客户端进行一切的通信。
"主线程统一accept/dispatch子线程"模型的工作示意图如下图所示:
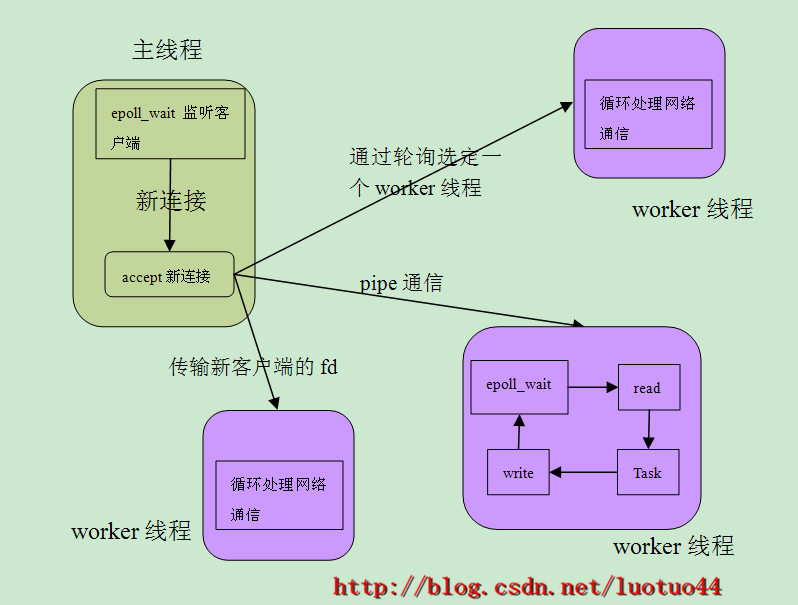
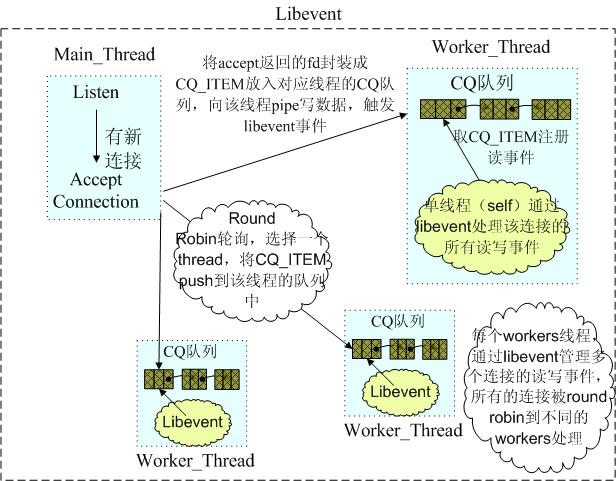
memcached里面的"主线程统一accept/dispatch子线程"和上面所说的差不多,区别在于:1. memcached使用libevent作为进行事件监听;2.memcached往管道里面写的内容不是fd,而是一个简单的字符。每一个worker线程都维护一个CQ队列,主线程把fd和一些信息写入一个CQ_ITEM里面,然后主线程往worker线程的CQ队列里面push这个CQ_ITEM。接着主线程使用管道通知worker线程:“我已经发了一个新客户给你,你去处理吧”。
memcached的"主线程统一accept/dispatch子线程"如下面这幅经典的图所示:
memcached的具体实现:
上图看到每一个worker线程都有一个CQ队列,主线程accept到新客户端后,就把新客户端的信息封装成一个CQ_ITEM,然后push到选定线程的CQ队列中。
CQ队列:
现在我们来看一下CQ队列长什么样的。
typedef struct conn_queue_item CQ_ITEM;
struct conn_queue_item {
int sfd;
enum conn_states init_state;
int event_flags;
int read_buffer_size;
enum network_transport transport;
CQ_ITEM *next;
};
/* A connection queue. */
typedef struct conn_queue CQ;
struct conn_queue {
CQ_ITEM *head;//指向队列的第一个节点
CQ_ITEM *tail;//指向队列的最后一个节点
pthread_mutex_t lock; //一个队列就对应一个锁
};
可以看到结构体conn_queue(即CQ队列结构体)有一个pthread_mutex_t类型变量lock,这说明主线程往某个worker线程的CQ队列里面push一个CQ_ITEM的时候必然要加锁的。下面是初始化CQ队列,以及push、pop一个CQ_ITEM的代码。
static void cq_init(CQ *cq) {
pthread_mutex_init(&cq->lock, NULL);
cq->head = NULL;
cq->tail = NULL;
}
static CQ_ITEM *cq_pop(CQ *cq) {
CQ_ITEM *item;
pthread_mutex_lock(&cq->lock);
item = cq->head;
if (NULL != item) {
cq->head = item->next;
if (NULL == cq->head)
cq->tail = NULL;
}
pthread_mutex_unlock(&cq->lock);
return item;
}
/*
* Adds an item to a connection queue.
*/
static void cq_push(CQ *cq, CQ_ITEM *item) {
item->next = NULL;
pthread_mutex_lock(&cq->lock);
if (NULL == cq->tail)
cq->head = item;
else
cq->tail->next = item;
cq->tail = item;
pthread_mutex_unlock(&cq->lock);
}
由上面代码得到的CQ队列如下图所示:

为worker线程构建CQ队列:
主线程又是怎么访问各个worker线程的CQ队列呢?在C语言里面的答案当然是使用全局变量啦。memcached专门定义了结构体,如下:
typedef struct {
pthread_t thread_id; //线程id
struct event_base *base; //线程所使用的event_base
struct event notify_event;//用于监听管道读事件的event
int notify_receive_fd; //管道的读端fd
int notify_send_fd; //管道的写端fd
struct conn_queue *new_conn_queue; /* queue of new connections to handle */
...
} LIBEVENT_THREAD;看到LIBEVENT_THREAD结构体的这些成员,完全可以顾名思义。memcached定义了LIBEVENT_THREAD类型的一个全局变量指针threads。当确定了memcached有多少个
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 56
56











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









