







 本文介绍了深度学习在目标检测领域的应用,包括RCNN系列(RCNN, fast RCNN, faster RCNN, RFCN)和yolo, SSD等方法。深入探讨了每种方法的原理和优缺点,并概述了使用Tensorflow目标检测API的实际操作。重点讨论了RCNN系列的步骤,如ROI pooling和多任务学习,旨在提高效率和准确性。"
86718482,8257004,Google SRE的8大运维原则详解,"['运维', '后端', 'SRE']
本文介绍了深度学习在目标检测领域的应用,包括RCNN系列(RCNN, fast RCNN, faster RCNN, RFCN)和yolo, SSD等方法。深入探讨了每种方法的原理和优缺点,并概述了使用Tensorflow目标检测API的实际操作。重点讨论了RCNN系列的步骤,如ROI pooling和多任务学习,旨在提高效率和准确性。"
86718482,8257004,Google SRE的8大运维原则详解,"['运维', '后端', 'SRE']
近些年深度学习在图像领域大放光彩,这篇文章先对目标检测领域深度学习的发展做一个总结,再结合一个例子对tensorflow model zoo中的目标检测API使用做一个说明。
本文内容如下(会分几次发出来):
目标检测的任务
深度学习在目标检测中的应用
- RCNN
- fast RCNN
- faster RCNN
- RFCN
- yolo
- yolo V2
- SSD
- tensorflow目标检测API的使用
(一)目标检测的任务
为了说明什么是目标检测任务,我举两个例子来说明。
第一个VOC数据集,VOC2007数据集是一个训练目标检测的数据集,其图片中一共有二十个种类的物体,包括 ‘aeroplane’, ‘bicycle’, ‘bird’等一共20个种类的物体,我们的任务就是在图中把这些物体给找到,框出这些物体,并说明框住的物体是这二十个类别里的哪一类,就像下面这样:

对照上面的图片,可以看出目标检测主要是在做两件事,一是确定图片中有没有你要找的东西,二是这东西在哪。
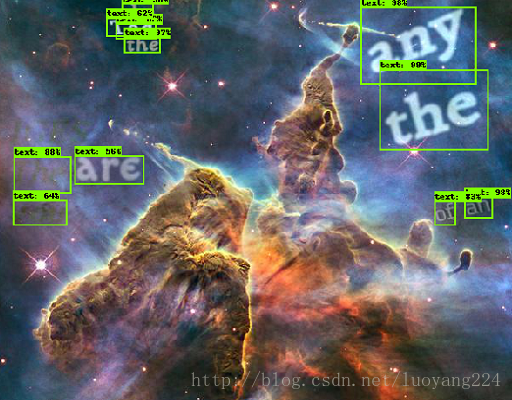
下面还有另外一个例子,数据集在这http://www.robots.ox.ac.uk/~vgg/data/scenetext,是一份场景文字数据集,这个数据集一共有80万的图片,每张图片中都嵌入了文字,任务是找到图片中的文字,把文字框出来,如下:
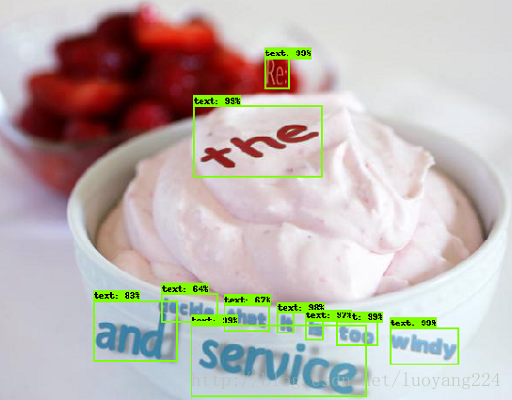
对于这样的目标识别任务,训练数据集的输入是一张图片,加上图片中每个物体框的左上角坐标以及右下角坐标。
(二)深度学习在目标检测中的应用
深度学习在目标检测中的应用主要分为两个路子的方法:
- RCNN,fast RCNN,fasterRCNN,RFCN这四种都属于两步走的方法,先找到图片中有可能是物体的框子,然后再确定框子里是什么,并且精修框子的位置
- yolo,yolo V2,SSD都属于一步到位,通过一个神经网络一次性给出框子的坐标和框子里的东西是什么
相对来说faster RCNN和RFCN的精度是比较高的,但因为分两步走,所以检测的耗时偏长,yoloV2和SSD的精度较faster RCNN和RFCN略微偏低,但可以速度快,可以满足实时性要求。
关于几种方法的对比,可以参考谷歌最近出的一篇论文,里面详细比较了faster RCNN,RFCN和SSD的精度和性能,链接:https://arxiv.org/abs/1611.10012
下面我们一一说明每种方法的步骤和原理,这部分会假设读者已经了解像VGG,ResNet这样的卷积神经网络,不然就会云里雾里了。此外这是一份总结,会给出每个算法的框架和其中一些不易理解的点,但不会详细描述具体的网络细节,关于网络细节在网上已经有很多很好的博客可以参考。
先从把深度学习带入目标检测的开山之作RCNN系列开始。
RCNN,fast RCNN,faster RCNN这三种方法是一脉相承的,从名字就可以看出,速度越来越快,同时准确度也越来越高。
下面是一张RCNN的整体架构图:

VOC数据集中的图片是大小不一的,所以在RCNN中首先会把图片缩放到固定尺寸(227x227),接着通过selective search的方法找到图片中有可能是物体的2K个候选框(ROI),再把这些候选框依次送入CNN进行特征提取输出固定长度的向量,把这些向量输入SVM分类器,注意这里有20个SVM的二分类器,用来判断这个ROI是某一类还是背景,并且会对这个ROI的bbox进行回归,以精修位置(下面细说),最后通过非极大抑制去除重复框住物体的框,留下最准确的框。
RCNN的步骤十分清晰,每一步要做什么也很明白。
对selective search感兴趣的话可以查看相关论文,这里不做解释,因为这个方法在faster RCNN中就已经不用了。这里只要知道它输入是一张图片,输出是一堆这张图片中有可能是物体的候选框。
CNN提取特征部分是把每个ROI作为输入,经过一系列卷积+pooling后接一个全连接层把不同大小的ROI计算成一个固定长度的向量。
对每个ROI使用SVM进行分类时,这里SVM的训练数据和前面CNN的训练数据是不一样的,因为训练CNN需要大量数据,所以对候选框的选择设定了一个比较宽泛的范围,比如把和真实框(GT:ground truth)IOU大于0.3的都设定为正样本,而在训练SVM分类器时,由于传统算法对数据中的噪音比较敏感,所以把和GT的IOU大于0.5的作为正样本,设定了一个更严格的阈值。
至于为什么用SVM而不用softmax,作者认为这样准确率更高,但在后续的算法中都不再使用SVM了。
对于边界回归(bbox-rg),可以看下面这张图,图中P框(蓝色)为经过selective search输出的一个预测框,G为真实框(红色), G^ 为经过回归后更接近真实框的最终预测输出框(黑色)。
边界回归就是要把P框回归到 G^ 框。要做到这样的变换,只需要两步:平移和缩放,操作如下:
记这三个框为: P:(Px,Py,Pw,Ph) , G:(Gx,Gy,Gw,Gh) , G^:(G^x,G^y,G^w,G^h) ,这里的下标x,y表示目标框中点的坐标,w,h表示目标框的宽度和高度,对于G需要根据数据集
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4460
4460

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









