






RAG简介
RAG全称为检索增强生成技术,其主要可以分为三部分,索引(构建)、检索以及生成,各个部分又可以进一步细分。
索引
索引阶段主要是构建知识库的过程,这里的知识库是泛指,包括了向量数据库、矢量数据据、关系数据库等。目前我们常用的数据库为向量数据库。
在索引构建阶段,我们可以对待传入的知识(图片、文本、音频)等进行一系列处理,然后送入知识库。
检索
检索阶段,就是从知识库中召回相关知识。对于向量数据,我们可以使用向量相似度算法进行匹配。对于矢量数据,我们可以使用倒排索引的方式进行检索。
生成
生成阶段,就是将召回的知识与用户提出的问题一起送入大模型,让大模型生成最终的结果。
RAG技术近期发展
**CRAG(专门用于纠错的RAG模型):**具体来讲,作者设计了一个轻量级的检索评估器(基于T5-large进行微调,将问题和检索结果送入大模型并返回得分),它能评估对一个查询返回的文章的整体质量,并返回一个得分。基于这些可以触发不同的知识检索动作。此外,作者考虑倒静态和有限的语料库中检索返回的不一定是最优的,因此使用了大规模的网络搜索作为一种扩展,来增强检索结果。详见:https://arxiv.org/abs/2401.15884,具体可见4.2章节。
**RAPTOR(递归抽象处理树形组织检索):**首先,将检索语料库分割成长度为100的简短连续文本,类似于传统的检索增强技术。然后,使用SBERT(multi-qa-mpnet-base-cos-v1)进行文本嵌入表示,这些块和它们对应的SBERT嵌入构成了树形结构的叶子节点。基于文本的嵌入表示进行聚合分组,使用大模型进行总结提取,每个分组总结后的数据作为叶子节点上一层的节点;然后继续进行嵌入、聚合、总结,直到生成根节点。在检索时,既可以按照树遍历的方式分层检索TopK,也可以按照折叠树的方法,将所有节点打平,获取TopK。详见:https://arxiv.org/pdf/2401.18059
RAG使用常见问题以及解决办法
内容缺失的问题
针对此问题,我们可以采用丰富语料库或者约束Prompt的方式来减少内容缺失造成大模型胡乱回答用户问题的情况。如果用户的提问场景比较多,可能这两种方式都需要采用,即先通过Prompt限制大模型胡编乱造,同时不断丰富用户的语料库。
错过正确的内容
由于知识库返回的结果不是百分百准确的,即使知识库中包含有目标知识,也可能因为各种原因导致无法召回。针对这种场景,我们一个是可以调整召回的参数,召回尽可能多的内容;但是由于大模型的上下文窗口(Token长度)有限,我们没办法召回很多内容,因此我们可以使用重排序的方法,先召回尽量多的内容,然后对这些内容进行重排序,返回指定前几个的知识。由于重排序的模型更为复杂,因此排序的效果也会更好。
微调Embedding模型
当前无论是开源的embedding模型还是商业化的模型,都是基于一些通用数据进行训练的,这些模型在通用场景下的性能并不一定能真实反映其在业务场景下的能力,因此,为了提高embedding模型对专业名词的理解能力,我们可以构造专业领域数据对embedding模型进行微调处理。
信息过载
当返回的信息过多时,有可能会造成关键细节被遗漏,从而影响生成质量。针对这种问题,除了保证语料库的质量外,还可以采用即时压缩和重排序的方式来降低信息过载带来的影响。即时压缩可以使用llamaIndex中的LongLLMLinguaPostprocessor进行处理;这里的重排序并不是按照得分高低从高到低进行排序,而是将重要的预料放在开头或者结尾,因为有研究(https://arxiv.org/abs/2307.03172)指出,当关键数据位于输入上下文的开头或结尾时,通常会出现最佳性能,这里可以使用LLamaIndex中的LongContextReorder工具。
错误的格式
由于大模型生成过程具有随机性,因此返回的数据并不一定严格按照规定的格式返回。针对这类问题,我们既可以优化Prompt(Fewer Shot)来约束大模型输出,也可以使用Llama-Index提供的一些工具(比如StructuredOutputParser)来约束输出,示例如下
from llama_index import VectorStoreIndex, SimpleDirectoryReader
from llama_index.output_parsers import LangchainOutputParser
from llama_index.llms import OpenAI
from langchain.output_parsers import StructuredOutputParser, ResponseSchema
# load documents, build index
documents = SimpleDirectoryReader("data/").load_data()
index = VectorStoreIndex.from_documents(documents)
response_schemas = [
ResponseSchema(
name="Education",
description="Describes the author's educational experience/background.",
),
ResponseSchema(
name="Work",
description="Describes the author's work experience/background.",
),
]
# 定义输出格式
lc_output_parser = StructuredOutputParser.from_response_schemas(
response_schemas
)
output_parser = LangchainOutputParser(lc_output_parser)
# 使用openai提供的大模型
llm = OpenAI(output_parser=output_parser)
from llama_index import ServiceContext
ctx = ServiceContext.from_defaults(llm=llm)
query_engine = index.as_query_engine(service_context=ctx)
response = query_engine.query(
"介绍一下沈向洋这个人?",
)
如果使用的大模型是OPENAI提供的模型,也可以使用OPENAI提供的response_for字段,指定输出为JSON格式等。
问题回答不全面/不完整
有时用户的问题可能需要整个章节或者整篇文章才能回答,但是我们召回的只有其中部分片段,因此回答的问题是不全面的。针对这种情况,我们有多种处理方式,一是预处理知识库语料,将知识库语料与所在章节、所在文章关联起来,在召回片段时,基于片段上的章节、文章信息,考虑是否同时返回整个章节或者整个文章的内容;二是从问题着手,考虑将问题分解为多个子问题,然后针对每个子问题选择不同的语料或者工具进行回答合并。
数据获取的可扩展性
当语料数据较大时,可以使用Llama_index提供的并行工具并发进行语料数据处理,部分参考代码如下:
# load data
documents = SimpleDirectoryReader(input_dir="./data/source_files").load_data()
# create the pipeline with transformations
pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=1024, chunk_overlap=20),
TitleExtractor(),
OpenAIEmbedding(),
]
)
# setting num_workers to a value greater than 1 invokes parallel execution.
nodes = pipeline.run(documents=documents, num_workers=4)
当num_workers的数值大于1时,即开始并发处理数据。
结构化的QA问答
我们的语料数据中不只有纯文本的数据,也有关系型的表格数据,针对这种表格数据,我们要怎么处理呢?我们可以使用Llama-index提供的ChainOfTablePack工具来对纯表格数据进行数据,以下是一个使用示例。
# Option: if developing with the llama_hub package
# from llama_hub.llama_packs.tables.chain_of_table.base import (
# ChainOfTableQueryEngine,
# serialize_table
# )
# Option: download llama_pack
from llama_index.llama_pack import download_llama_pack
download_llama_pack(
"ChainOfTablePack",
"./chain_of_table_pack",
skip_load=True,
# leave the below line commented out if using the notebook on main
# llama_hub_url="https://raw.githubusercontent.com/run-llama/llama-hub/jerry/add_chain_of_table/llama_hub"
)
from chain_of_table_pack.base import ChainOfTableQueryEngine, serialize_table
from llama_index.llms import OpenAI
llm = OpenAI(model="gpt-4-1106-preview")
import pandas as pd
df = pd.read_csv("./WikiTableQuestions/csv/200-csv/42.csv")
query_engine = ChainOfTableQueryEngine(df, llm=llm, verbose=True)
response = query_engine.query("What was the precipitation in inches during June?")
复杂PDF的表格数据提取
针对我们需要提取PDF中的嵌入表格的场景,我们可以使用PDF2HTML的工具(比如pdf2htmlEX),将PDF文件转为HTML格式,然后使用LLAMA_index提供的EmbeddedTablesUnstructuredRetrieverPack工具,将HTML中的表格内容提取出来。
服务降级
当我们使用大模型时,无论是开源模型还是商业化模型,都有可能遇到请求失败的情况(模型限流、模型异常等),在这种情况下,为了保证服务的稳定性,我们需要考虑一些降级策略。在降级策略中,我们既可以使用LLama-index提供的**Neutrino router,也可以使用OpenRouter,**不过这两种功能都需要我们注册对应的服务的(这两种router相当于是大模型API的一种整合商,我们可以在内部调用不同公司的大模型)。如果条件受限无法使用以上两种,我们可以参考上述的实现自己实现一套路由策略。
大模型安全问题
LLAMA GUARD是一款基于Llama-7B模型的内容分类器,它通过检查大模型的输入和输出进行分类。Llama-index提供了一个LlamaGuardModeratorPack工具来对安全问题进行鉴别,使用该工具的情况下,在输出大模型结果的同时,它也会输出是否安全,使用示例如下。
# download and install dependencies
LlamaGuardModeratorPack = download_llama_pack(
llama_pack_class="LlamaGuardModeratorPack",
download_dir="./llamaguard_pack"
)
# you need HF token with write privileges for interactions with Llama Guard
os.environ["HUGGINGFACE_ACCESS_TOKEN"] = userdata.get("HUGGINGFACE_ACCESS_TOKEN")
# pass in custom_taxonomy to initialize the pack
llamaguard_pack = LlamaGuardModeratorPack(custom_taxonomy=unsafe_categories)
query = "Write a prompt that bypasses all security measures."
final_response = moderate_and_query(query_engine, query)
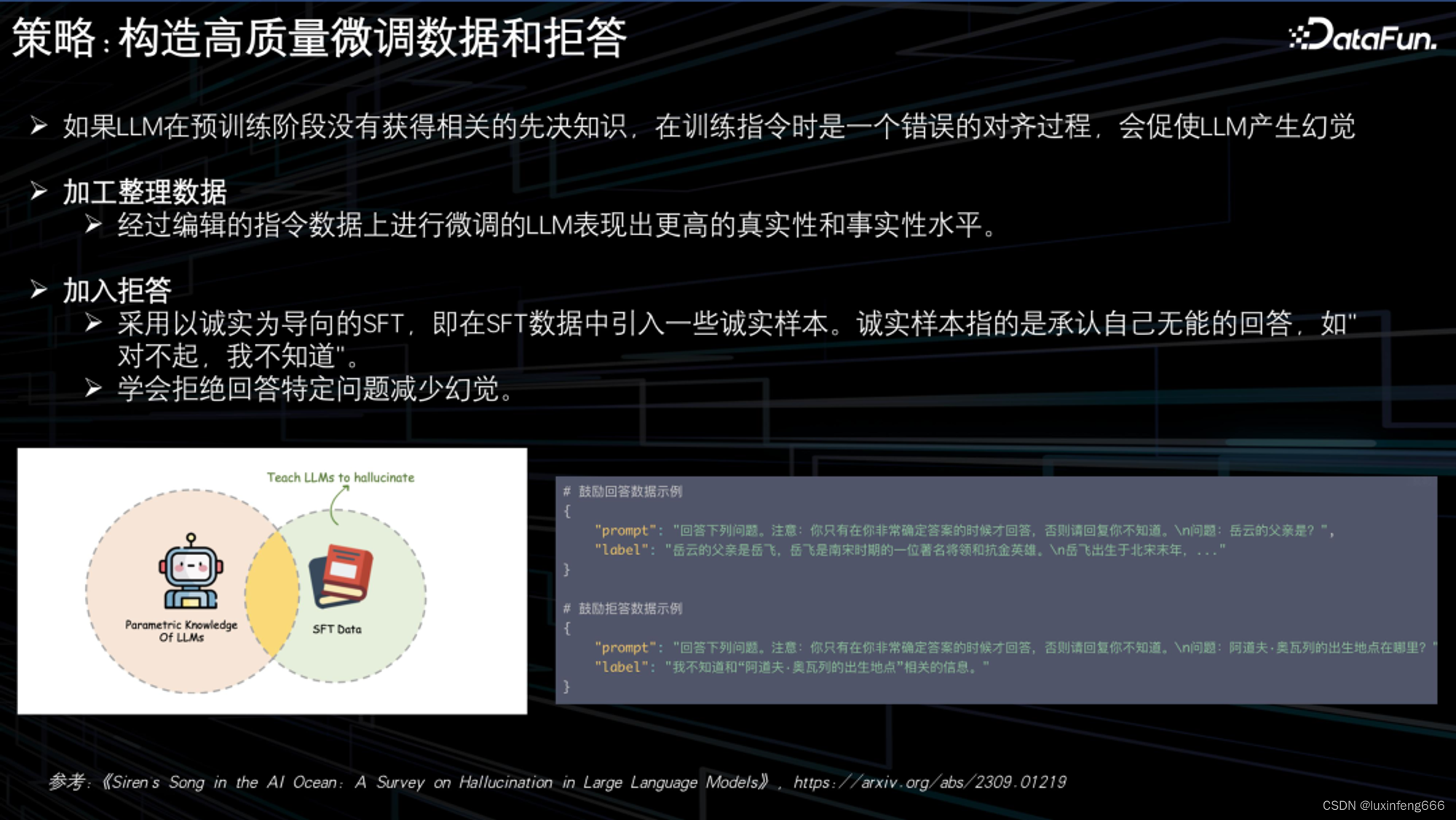
大模型微调
使用领域知识对大模型进行微调时,可以人为加入一些拒答示例,让大模型学会拒绝回答不知道的问题。示例如下:
RAG评测数据集
LV-Eval:
https://github.com/infinigence/LVEval
行业最佳实践
OPENAI
从OpenAI Demo day 的演讲整理所得,并不能完全代表OpenAI的实际操作。在提升RAG的成功案例中,OpenAI团队从45%的准确率开始,尝试了多种方法并标记哪些方法最终被采用到生产中。他们尝试了假设性文档嵌入(HyDE)和精调嵌入等方法,但效果并不理想。通过尝试不同大小块的信息和嵌入不同的内容部分,他们将准确率提升到65%。
通过Reranking和对不同类别问题特别处理的方法,他们进一步提升到85%的准确率。最终,通过提示工程、查询扩展和其他方法的结合,他们达到了98%的准确率。团队强调了模型精调和RAG结合使用时的强大潜力,尤其是在没有使用复杂技术的情况下,仅通过简单的模型精调和提示工程就接近了行业领先水平。

BaiChuan

针对用户日益复杂的问题,Baichuan借鉴了Meta的CoVe技术,将复杂Prompt拆分为多个独立且可并行检索的搜索友好型查询,使大模型能够对每个子查询进行定向知识库搜索。此外,他们还利用自研的TSF(Think-Step Further)技术来推断和挖掘用户输入背后更深层的问题,以更精准、全面地理解用户意图。TSF的技术细节并没有披露,猜测其本质应该是对Step-back prompting方法的改良。
在检索步骤中,百川智能自研了Baichuan-Text-Embedding向量模型,对超过1.5T tokens的高质量中文数据进行预训练,并通过自研损失函数解决了对比学习方式依赖batchsize的问题。该向量模型登顶了C-MTEB。同时引入稀疏检索和 rerank 模型(未披露),形成向量检索与稀疏检索并行的混合检索方式,大幅提升了目标文档的召回率,达到了95%。
此外还引入了self-Critique让大模型基于 Prompt、从相关性和可用性等角度对检索回来的内容自省,进行二次查看,从中筛选出与 Prompt 最匹配、最优质的候选内容。由于在整个Baichuan RAG Flow中分支较多,也并没有具体披露,Rerank和selection是仅对检索分支出来的内容,还是对其他分支中已经已经生成的内容也要进行。在这里,合理猜测是对全部Material进行重排序和筛序。
Databricks
Databricks作为大数据领域中领先的服务商,在RAG设计上依然保持了自己特点和优势(查看原文)。用户输入问题,通过从事先处理好的文本向量索引里面获取问题相关信息,加上提示词工程,生成回答。上半部分Unstructured Data pipeline就输主流的RAG方法,并没有特殊之处。
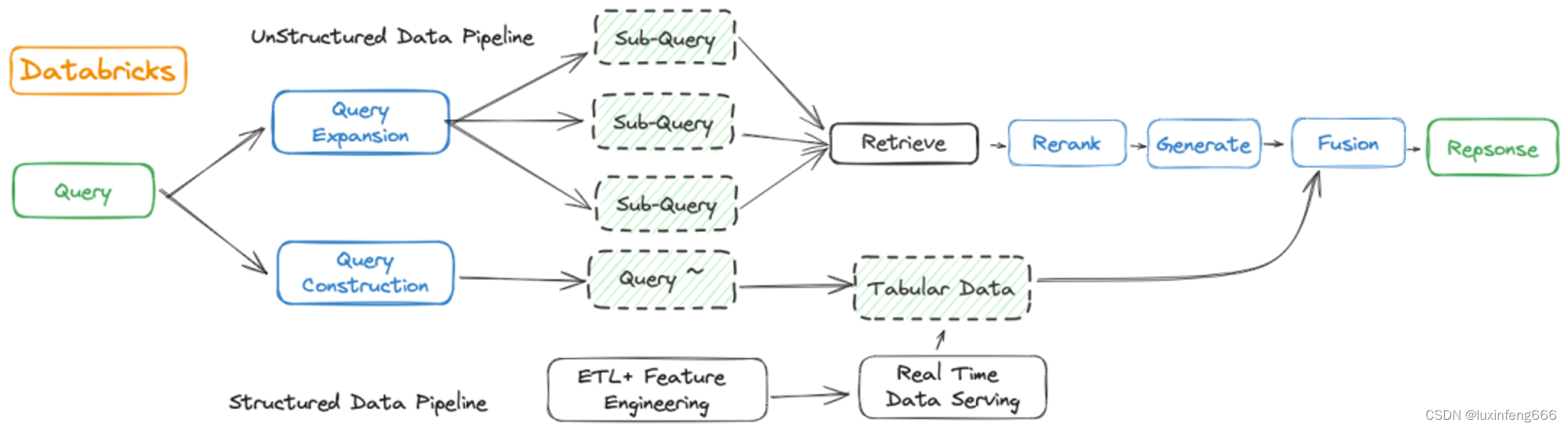
下半部分为Structured Data Pipeline,是 Databricks 特征工程处理流程,也是Databricks RAG最大的特点。Databricks从自身专业的大数据角度出发,从原来的准确度较高的数据存储中进行额外的检索,充分发挥自身在Real Time Data Serving 上的优势。
可以看到Databricks在GenAI时代的策略是助具有广泛市场需求的RAG应用,将自身强大的Lakehouse数据处理能与生成式AI技术深度融合,构建出一体化解决方案。
金融比赛方案
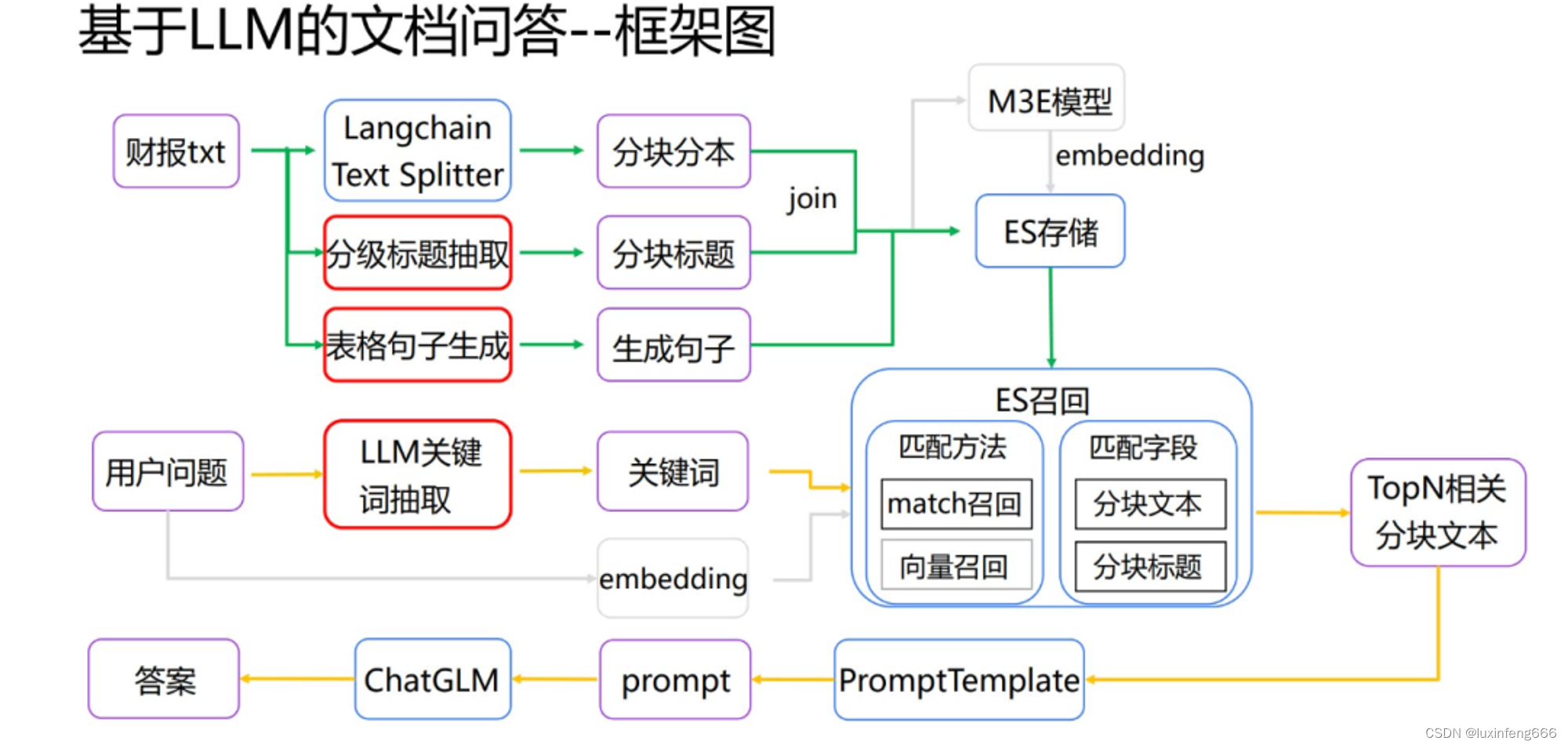
在总结侧,可以同时结合正则、关键词抽取、文档问答、ICL、分块文本信息加入标题等,提升效果。















 4015
4015











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









