







About the authors
在person re-id方面,国内做得最好的应该是中山大学的郑伟诗老师,还有一位华人,英国马里兰大学的Shaogang Gong老师,两个人之间也合作了几篇文章,看郑伟诗老师的bio,原来郑老师曾在2008年做过Shaogang Gong和Tao Xiang的博后。大家如果做person re-id,这两个人应该是肯定要跟的。
Summary
这是一篇video-based person re-id,这方面工作比较少,后面related work会总结一下这方面已有的工作。
提出的方法名字叫top-push distance learning model (TDL),top-push的思路是对ref [15]的扩展(从一维到高维),方法基本上可以概括为:进一步增大类间差异,缩小类内差异,方法很简单,效果却出奇的好,比之前的最高精度高了不止一倍,后面实验会提到。
Motivation
起因有几方面,其中作者最强调的应该是下面他们观察到的现象:

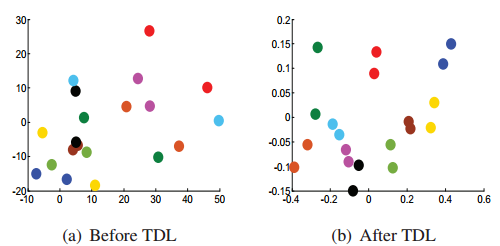
横轴代表图片/视频,纵轴是一个距离度量值,这个值表示intra-class distance,也即类内距离,也即同个人的图片/视频之间的差异,红色表示图片,蓝色表示视频。这里作者只显示PRID 2011和iLIDS-VID两个数据库下的20张图片/个视频,可以明显观察到:视频的类内差异要比图片大,也即一个人在两个camera下的视频更难被识别成同一个人,所以呀,我们要约束类内差异,增大类间差异,这个思路是很容易想的,下图是经过作者提出的方法(TDL)处理前后的对比,可以看到,增大类间差异、缩小类内差异的目的确实达到了。
还有其它一些起因,罗列如下:
- 之前video based person re-id的工作并没有有效利用video的信息,这里作者融合了表观特征(LBP and color histograms)和时空信息(HOG3D)
Related work
基本上很多single-shot的方法(就是基于单张图像的方法,以后有空再解释)都可以拓展成multi-shot,然后应用到video-based person re-id,除了这部分related work外,video-based的方法有三个:
[10] S. Karanam, Y. Li, and R. Radke. Sparse re-id: Block sparsity for person re-identification. In CVPR Workshop, 2015.
[30] D. Simonnet, M. Lewandowski, S. A. Velastin, J. Orwell,and E. Turkbeyler. Re-identification of pedestrians in crowds using dynamic time warping. In ECCV, 2012.
[31] T. Wang, S. Gong, X. Zhu, and S. Wang. Person reidentification by video ranking. In ECCV. 2014.
ref [10]没有读过,作者的描述是(不太懂):
Srikrishna et al. [10] introduced a block sparse model to handle the video-based person re-id problem by the recovery problem on embedding space.
不过最后这三个工作的缺点却是点明了:
However, these works assume all image sequences are synchronized, but it becomes unapplicable due to different actions taken by different people.
对齐本身就是一件很难又费时的事情,实际应用当然比较受限。
还有一些和作者提出的方法相似或者思路相似的做法,比如LMNN,如下图所示:

图也很好理解,LMNN的目标是:缩小附近正样本间的差异,惩罚附近所有的负样本;而TDL的目标是:缩小正样本间的差异,惩罚离得最近的负样本;所以TDL比LMNN有更强的约束。
RDC是作者早先的一个工作,和RDC以及LDA的差异如下:
While RDC is limited by the scaleof relative comparison, the proposed TDL can largely reduce the number of relative comparisons in the context oftop-push modeling. In addition, compared to LDA [5], ourmodel replaces the maximum of inter-class distance by theminimization of hinge loss of top-push comparison, so thatour model has imposed much more powerful constraint onthe inter-class modeling.
Approach
前面啰嗦这么多,方法反倒是很简单,下面一个式子就解决了:
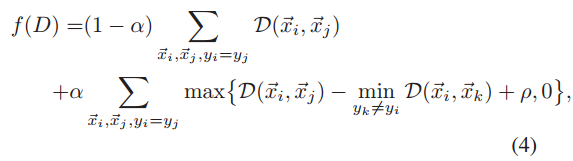
,
yi
是第
i
个sample的label,
第一项表示类内差异,也即减小所有正样本对的距离,第二项是扩大类间差异,这里很像triplet loss,不同在于第二项里的
min
这项,它选取离
xi→
最近的负样本。
优化算法没有看,也不是了解的重点,大家有兴趣的可以自己去看看。
Experiments
实验效果非常显著(和两个数据库上最好的结果对比)
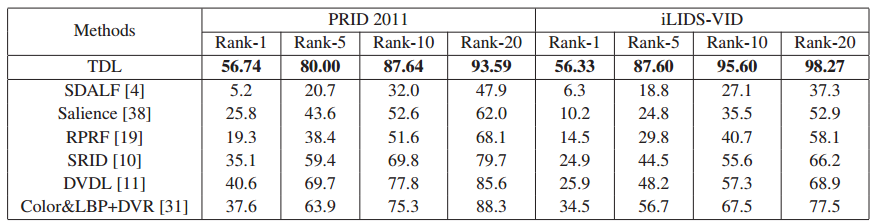
这里少了ECCV2014的一个对比,[2014,ECCV] Person Re-Identification by Video Ranking(之后还有一个期刊版本,效果更好),不过即使和这个对比,精度还是要高出一倍左右。
和related work的结果对比
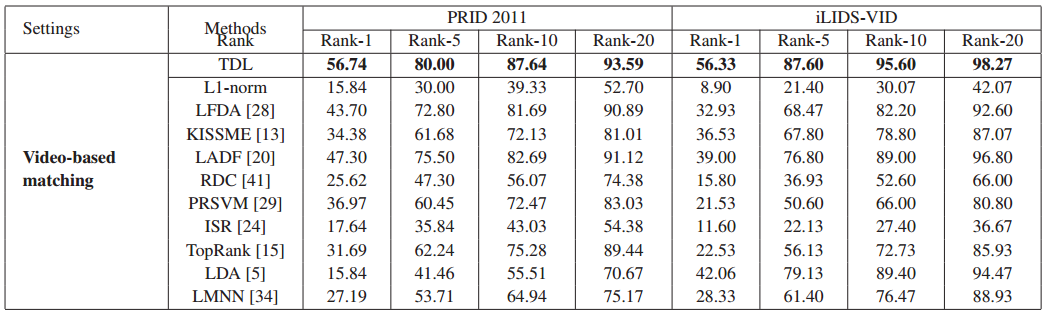
实验效果还是非常好。















 668
668

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









