






ollama 是一个快速部署和运行大语言模型的开源工具,https://ollama.com/。通过它可以在终端与大语言模型交互,而且安装非常的简单,支持非常多的模型,并且可以随意切换模型, 支持模型地址:https://ollama.com/library
如果你想使用LLM模型但是又不想暴露你的私人数据到公网,不放试一试这个方法。
以下是在 WSL 中安装它的过程
执行安装命令
curl -fsSL https://ollama.com/install.sh | sh
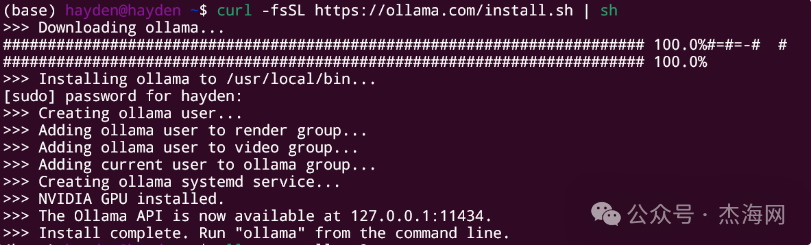
这样就安装好了。
使用
使用 命令 ollama -h 看看有哪些参数
(base) hayden@hayden ~$ ollama -h``Large language model runner`` ``Usage:` `ollama [flags]` `ollama [command]`` ``Available Commands:` `serve Start ollama` `create Create a model from a Modelfile` `show Show information for a model` `run Run a model` `pull Pull a model from a registry` `push Push a model to a registry` `list List models` `cp Copy a model` `rm Remove a model` `help Help about any command`` ``Flags:` `-h, --help help for ollama` `-v, --version Show version information`` ``Use "ollama [command] --help" for more information about a command.
在命令帮助信息中可以看到可以使用 serve 启动它,
接着我们来启动它:
(base) hayden@hayden ~$ ollama serve 127 ↵``Couldn't find '/home/hayden/.ollama/id_ed25519'. Generating new private key.
然后打开另一个窗口, 接着 从 https://ollama.com/library 中选一个模型 拉到本地跑,以 llama2 为例
(base) hayden@hayden ~$ ollama run llama2``pulling manifest``pulling 8934d96d3f08... 100% ▕██████████████████████████████████████████████▏ 3.8 GB``pulling 8c17c2ebb0ea... 100% ▕██████████████████████████████████████████████▏ 7.0 KB``pulling 7c23fb36d801... 100% ▕██████████████████████████████████████████████▏ 4.8 KB``pulling 2e0493f67d0c... 100% ▕██████████████████████████████████████████████▏ 59 B``pulling fa304d675061... 100% ▕██████████████████████████████████████████████▏ 91 B``pulling 42ba7f8a01dd... 100% ▕██████████████████████████████████████████████▏ 557 B``verifying sha256 digest``writing manifest``removing any unused layers``success``>>> Send a message (/? for help)
这样 llama2 模型就跑起来了,现在就可以在本地与 llama2 交互了。
这里我问了一句 what is you name 模型对问题做出了回答。我们也可以在写代码的时候让它帮助我们写一段代码。
>>> what is you name``I'm just an AI, I don't have a personal name. My purpose is to assist and provide helpful responses to``users like you, so please feel free to call me by any name you like!`` ``>>> Send a message (/? for help)
接着可以用 list 命令看看本地安装了哪些模型
(base) hayden@hayden ~$ ollama list``NAME ID SIZE MODIFIED``llama2:latest 78e26419b446 3.8 GB About a minute ag
我这里显示只安装了一个 llama2 模型,模型的大小是3.8GB。
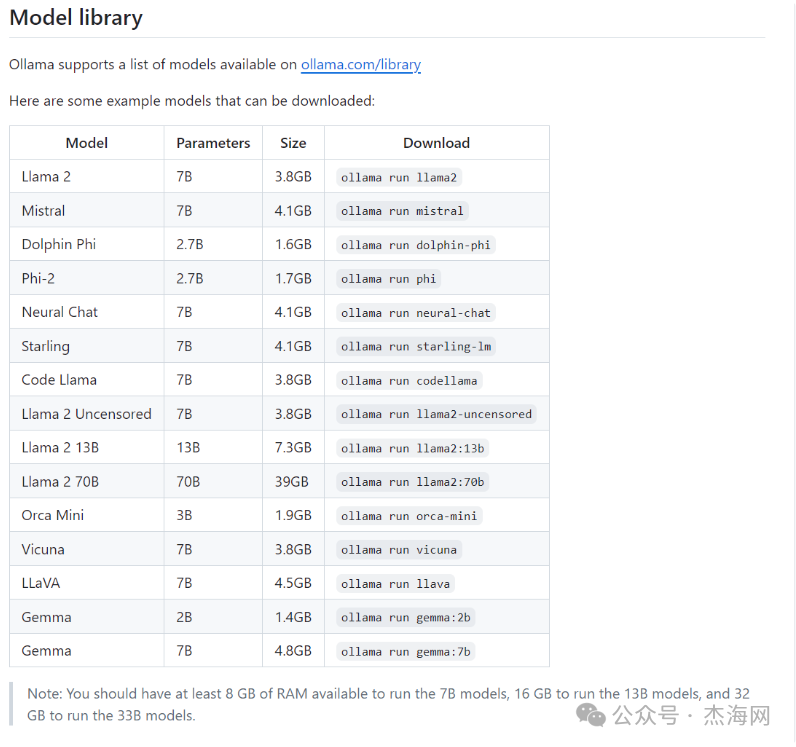
需要注意 github 上面有介绍运行不同大小参数的模型对内存的要求不一样:
Note: You should have at least 8 GB of RAM available to run the 7B models, 16 GB to run the 13B models, and 32 GB to run the 33B models.
在选择模型的时候需要考虑一下你本地运行的机器的内存是否满足运行这个模型的要求,运行 7B 的模型需要至少 8 GB的内存, 运行 13B 的模型至少需要 16 GB的内存,运行 33B 的模型至少需要 32 GB 的内存。
最后如果不想继续使用某个模型,可以使用 rm 删掉以节省磁盘空间
(base) hayden@hayden ~$ ollama rm llama2















 1629
1629

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









