









总述
本文的出发点在于:之前的dropout存在训练与测试时模型不一致的问题。
基于这个出发点,本文提出了R-Dropout的方式来解决这个问题。
实验证明,R-Dropout在多个数据集上均有效(都略有提升)
对Dropout的思考
首先我们要理解,为什么之前的dropout存在训练与测试时不一致的问题。在训练的时候,dropout会随机mask模型的一些节点,然后利用剩余的网络去拟合数据(防止过拟合)。在不同batch的数据训练的过程中,由于mask是随机变动的,因此不同的数据可能会经过不同的网络处理。因此整个训练过程可以看成是多个不同的网络的集成学习。而在测试的时候,由于不会随机mask掉节点,因此可以看做是完整的模型在测试集上做预测,因此这里就存在不一致性。
因为训练的时候,学习的是一个子模型,而测试的时候,使用的是完整的模型来做预测。
作者的思路非常清奇,可能直观的方法是直接想办法减小子模型与完整模型的差距,而本文的想法没有那么直观,而是说:如果所有子模型的输入都差不多的话,那么完整模型的输出与子模型的输出应该也相差不大。, 因此本文的优化目标是对于同一组输入,经过相同架构,但是以不同mask dropout后的模型,得到的输出应该要保持一致。
R-Dropout 介绍
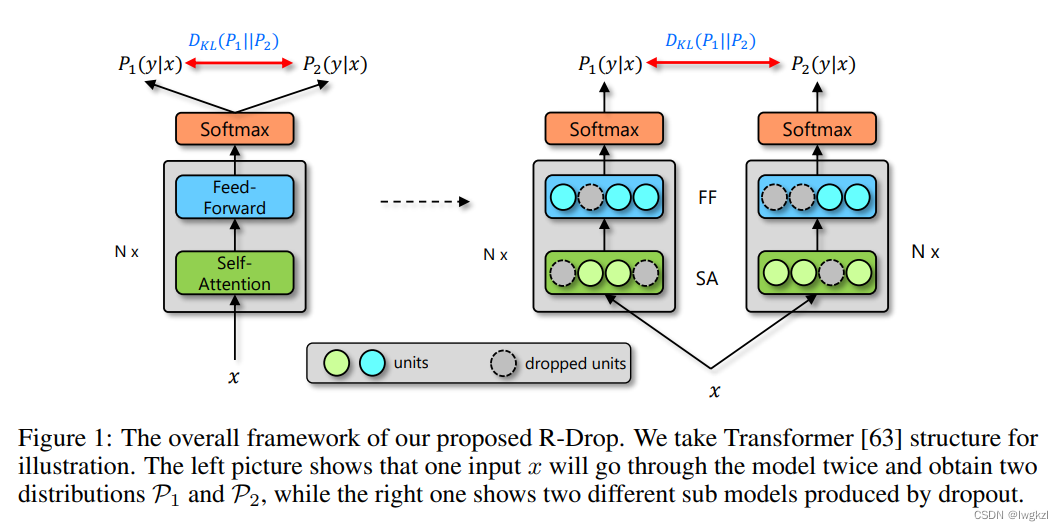
其主要思路如上一节所示,这张图也可以直观的展示他的思路,如右图所示,对于同一个输入X,经过两个相同的Transformer encoder结构,不过这两个结构会以不同的mask进行dropout然后得到两个输出P1(y|x)以及P2(y|x),R-dropout要求这两个输出要尽可能一致。因此以这两个输出的KL散度作为模型的损失函数之一来进行优化。
实验与结论
标准的实验证明R-Dropout在18个数据集上都有一点提升(1%–2%)。
其中消融实验比较有意思,会验证几个想法。
想法1:
每一次进行R-dropout的时候,可以不只是两个模块产生的输出求KL散度,可以同时使用多个模块来对照。
结论: 作者实验了同时做三个不同dropout的模块,效果比两个模块要稍微好一丢丢,但是没有太多意义。
想法2:这两个模块,dropout的概率可以不一样,因此可以尝试以不同的概率进行mask。得到如下的矩阵。
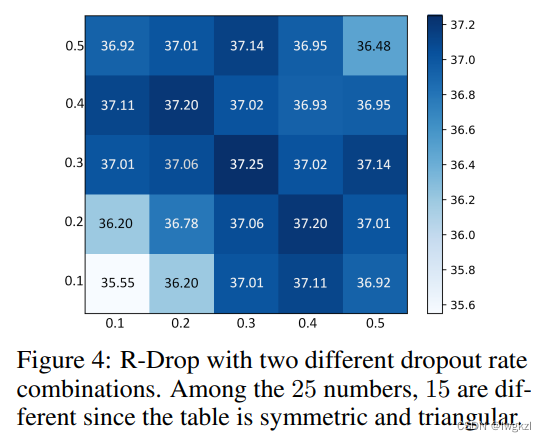 结论: 两个模块的dropout概率在0.3-0.5之间时,结果都相差不多。
结论: 两个模块的dropout概率在0.3-0.5之间时,结果都相差不多。
代码
import torch.nn.functional as F
# define your task model, which outputs the classifier logits
model = TaskModel()
def compute_kl_loss(self, p, q, pad_mask=None):
p_loss = F.kl_div(F.log_softmax(p, dim=-1), F.softmax(q, dim=-1), reduction='none')
q_loss = F.kl_div(F.log_softmax(q, dim=-1), F.softmax(p, dim=-1), reduction='none')
# pad_mask is for seq-level tasks
if pad_mask is not None:
p_loss.masked_fill_(pad_mask, 0.)
q_loss.masked_fill_(pad_mask, 0.)
# You can choose whether to use function "sum" and "mean" depending on your task
p_loss = p_loss.sum()
q_loss = q_loss.sum()
loss = (p_loss + q_loss) / 2
return loss
# keep dropout and forward twice
logits = model(x)
logits2 = model(x)
# cross entropy loss for classifier
ce_loss = 0.5 * (cross_entropy_loss(logits, label) + cross_entropy_loss(logits2, label))
kl_loss = compute_kl_loss(logits, logits2)
# carefully choose hyper-parameters
loss = ce_loss + α * kl_loss
实际上在使用的时候,可以把X给copy一份,然后统一输入到model中,故无需把X两次经过model。即:
double_x = torch.stack([x,x],0).view(-1,x.size(-1)
tot_logits = model(double_x).view(2, x.size(0), -1)
logits = tot_logits[0]
logits2 = tot_logits[1]
# .....














 1716
1716











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









