










随机森林作为一种集成学习方法,在处理复杂数据分析任务中特别是遥感数据分析中表现出色。通过构建大量的决策树并引入随机性,随机森林在降低模型方差和过拟合风险方面具有显著优势。在训练过程中,使用Bootstrap抽样生成不同的训练集,并在节点分裂时随机选择特征子集,这使得模型具备了处理高维和非线性数据的能力。随机森林对噪声和异常值具有鲁棒性,其预测结果通过对多棵树的集成投票或平均获得,减少了单个异常对结果的影响。此外,随机森林提供了变量重要性评估功能,帮助研究者识别对预测最重要的特征,从而优化模型性能。尽管包含大量决策树,随机森林的训练和预测过程依然相对高效,尤其在处理大规模数据集时表现出色。由于适用于分类、回归和处理混合数据,随机森林在数据科学和遥感分析中成为不可或缺的工具。因此,遥感随机森林建模与空间预测的应用能够有效提升遥感数据分析的精度和可靠性,是许多研究者关注的热点。
在R语言中,随机森林的实现与应用非常方便,R语言提供了多种包用于构建和优化随机森林模型。R语言的随机森林实现不仅支持分类和回归任务,还支持处理多类别问题、处理缺失数据,以及评估变量重要性等功能。这些包通常具有高度优化的计算性能,能够处理大规模数据集,同时提供灵活的参数调整接口,方便用户根据具体需求进行模型调优。此外,R语言在数据可视化方面的优势使得用户能够直观地展示模型的结果和变量的重要性,进一步提高了分析的可解释性和应用价值。因此,R语言中的随机森林工具因其易用性、灵活性和强大的功能,成为遥感数据分析中不可或缺的工具。
第一章、理论基础与数据准备
1.1 遥感数据在生态学中的应用
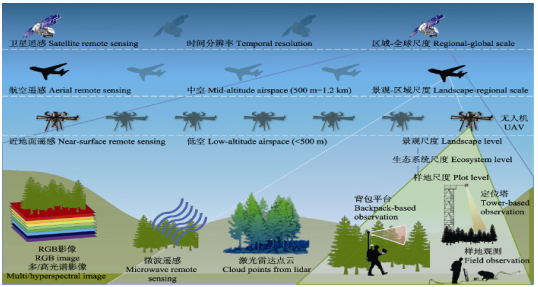
1.2 常见的机器学习算法及其遥感中的应用
机器学习基础 机器学习是一门研究如何通过数据来自动改进模型和算法性能的学科。
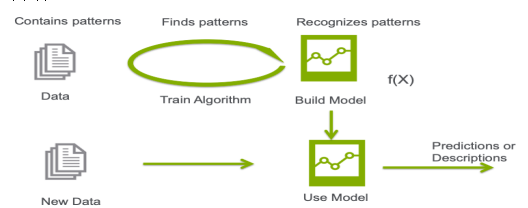
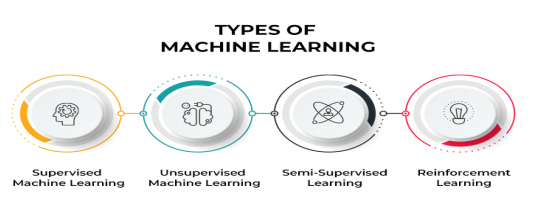
常见的机器学习算法:极限梯度提升机(XGBoost)、随机森林(Random Forest,RF)、梯度提升决策树(GBDT)等
机器学习算法在生态学中的应用分析
1.3 R语言环境设置与基础
(1)安装R及集成开发环境(IDE);
(2)R语言基础语法与数据结构,包括:程序包安装、加载、更新,数据读取与输出,ggplot2常规画图等。
1.4 遥感数据处理与特征提取
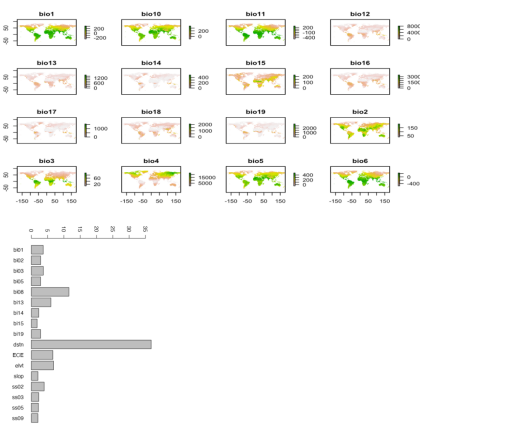
(1)栅格数据预处理
栅格数据信息查看、统计和可视化
栅格数据掩膜提取、镶嵌、重采样等
(2)植被特征指数解释与提取:归一化植被指数、水体指数等数十种植被指数
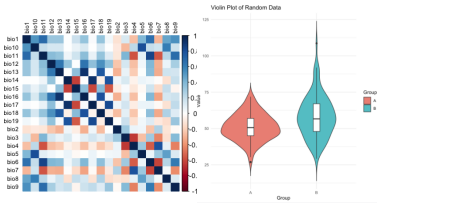
(3)变量筛选与最佳组合的选择:
主成分分析(Principal Component Analysis,PCA)与Boruta 算法
第二章、随机森林建模与预测
2.1预测模型的建立
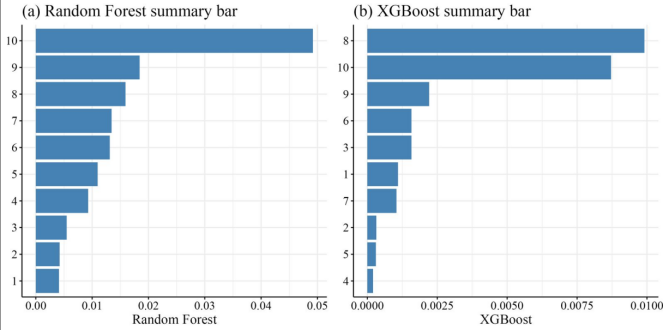
随机森林(RF)、极限梯度提升机(XGBoost)和支持向量机(SVM)等机器学习算法,分别建立预测模型,并参数调优。
2.2 最优模型空间预测
通过R2、RMSE、MAE等指标评价模型效率,选择最优模型进行空间预测。
2.3 预测变量重要性分析
分析解释变量对模型预测结果的影响,通过特征重要性分析等方法识别并量化解释变量与因变量。
2.4 预测结果空间分布制图
第三章、案例与项目
3.1 实际案例分析
(1)机器学习案例分析:以随机森林为例,分析高水平论文结构与写作思路、复现相关图表
(2)整合、分析机器学习在遥感、生态领域的经典论文。

















 2053
2053

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









