









《VOC-ReID: Vehicle Re-identification based on Vehicle-Orientation-Camera》
这是AI City Challenge 2020 Track2(Vehicle ReID)第二名的解决方案!!!
Xiangyu Zhu,Zhenbo Luo,Pei Fu,Xiang Ji
Ruiyan Technology
Abstract
vehicle ReID是一项具有挑战性的任务,其主要原因是类内方差高,类间方差小。在这项工作中,我们重点研究了由相似背景和形状引起的失效案例。它们对相似性产生了偏见,使得细粒度信息更容易被忽略。为了减少偏差,我们提出了一种VOC-ReID方法,将车辆-方向-相机作为一个整体,将背景/形状相似性转化为相机/方向的重识别(reforming background/shape similarity as camera/orientation re-identification)。首先,分别对车辆模型、方向模型和相机再识别模型进行训练。然后以方向和相机相似性作为惩罚,得到最终的相似性。此外,我们提出了一个基于strong baseline即bag-of-tricks(BoT-BS)的高性能baseline。
1. Introduction
vehicle ReID旨在通过多个摄像头匹配车辆外观。随着摄像头在城市道路上的广泛部署,这项任务在智能城市中得到越来越多的应用,并且也引起了计算机视觉界的越来越多的兴趣[1,2,3]。
vehicle ReID受益于person ReID[4,5,6],网络架构[7,8,9],训练loss[10,11],数据扩充[12,13]的进展。但是,vehicle ReID仍然面临许多挑战,包括车辆模型,视角,遮挡,运动模糊的类内变化[14]。
根据我们的观察,vehicle ReID任务受到相似的车辆形状和背景的影响。相机拍摄的图像具有相同的背景,而方向是汽车形状的关键组成部分。因此,考虑方向和摄像头以及车辆ID是合理的。基于此想法,我们提出了一种名为VOC-ReID的机制来解决背景和车辆形状引起的偏差问题。主要贡献有三方面:
- 我们认为背景的相似性可以解释为相机的重识别,形状的相似性可以解释为方向的重识别。
- 为了减少背景和形状的偏差,我们提出了VOC-ReID方法,该方法将vehicle-orientation-camera作为一个整体。据我们所知,我们是第一个在vehicle ReID任务中将车辆、方向和相机信息联合起来的。
- 在不使用任何额外数据和标注的情况下,我们的方法在NVIDIA AI City Challenge 2020的vehicle ReID赛道中排名第二。它在VeRi776数据集上的性能也超过了最先进的方法[2]。
2. Related Works
3. Proposed Approach
在3.1节中,介绍了基准架构(使用BoT-BS),这是3.2节中的基本单元。 然后,在3.2节中介绍了triplet re-identification系统,缩写为VOC-ReID。在第3.3节中,我们介绍了训练和后处理技巧。
3.1. Training Network
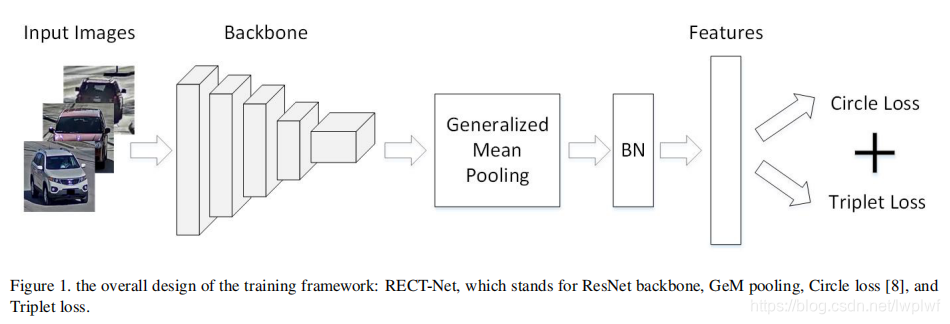
Baseline架构如图1所示。在下面的章节中,我们使用缩写RECT-Net来表示它,它代表ResNet[7,8,9],GeM pooling[23],Circle loss[11]和Triplet loss[10]的组合。本节还介绍了数据增强,包括弱监督检测weakly supervised detection[12、13],随机擦除 random erasing[24],颜色抖动color jittering和其他方法。
ResNet backbone.
我们使用具有IBN[9]结构的ResNet[7]作为特征提取器,它表现出了抵抗视角和光照变化的潜力。
GeM: Generalized-mean Pooling.
Loss: Circle Loss and Triplet Loss.
Data Augmentation: Weakly Supervised Detection.
为了提高模型的精度,避免过拟合,数据增广被广泛应用。在我们的方法中,一个重要的数据扩充工作是弱监督检测扩充。受[12,13]的启发,我们训练了一个初始的vehicle ReID模型来获得每个图像的heatmap response,并设置一个阈值来获得比它大的边界框。与有监督的检测方法相比,该方法对车辆的裁剪更加紧密,聚焦于Re-ID模型的注意区域( attentional areas)。在弱监督检测之后,我们得到了训练集和测试集的裁剪副本。训练集中裁剪图与原始图像一起使用。所以在应用弱监督数据扩充后,我们的数据集增加了一倍。我们的训练阶段还采用了其他常用的数据增强方法,如随机擦除[24]和颜色抖动等。
3.2. VOC-ReID
Vehicle ReID.
Orientation ReID.
Camera ReID.
VOC Fusion.
3.3. Training and Testing Tricks
Cosine learning rate decay.
Image to track.
在测试阶段,传统的解决方案是计算query图像和gallery图像之间的距离。由于一条track中的图像是同一辆车,一条track覆盖了多个相似的图像,但可能视角不同,因此我们可以将每个gallery图像的特征替换为track的平均特征,这可以看作是从 image-to-image到image-to-track的一种改进。
Re-rank.
当获得融合距离矩阵时,我们采用re-ranking方法[28]来更新最终结果,这将显著改善mAP。
4. Experiments
4.1. Implementation Details
所有的输入图像被resize到320x320,然后在训练中采用一系列的数据增强方法,包括随机水平翻转、随机裁剪、颜色抖动和随机擦除(random horizontal flip,random crop,color jitter和random erase)。我们还尝试了其他数据增强方法,如 random patch、augmix[29]、随机旋转/缩放random rotate/scale和随机模糊random blur,但事实证明所有这些方法都无法很好地完成此任务。为了满足pair-wise loss的要求,数据由m-per-class采样器使用参数P和K进行采样,参数为mini-batch中的id数和每个id的图片数。在我们的实验中,它们被设定为P=4,K=16。在训练过程中,ResNet50-IBN-a被用作vehicle和orientation/camera ReID的backbone。所有模型都在一个GTX-2080-Ti GPU上训练,共12个epochs,第一个epochs中的特征层被冻结,作为一种warm-up策略。采用Cosine annealing scheduler将初始学习率从3.5e-4降低到7.7e-7。
4.2. Dataset
CityFlow中共有666个ID和56277个图像。333个ID的36935张图像用于训练,其余的用于测试。AI City Challenge 2020中的一项新规则禁止使用额外数据,例如VeRi776[2]和VehicleID[30]。为了克服缺乏数据的不足,官方委员会提供了一个名为VehicleX[17]的合成vehicle ReID数据集。它包含由Unity引擎生成的1362个ID和192150个图像,具有丰富的方向和光照变化。我们仅使用CityFlow的训练集和整个合成数据集VehicleX。
4.3. Ablation Study
在本节中,我们将CityFlow的训练集分为两部分,前95个ID被用作验证集,其余的用于训练。
Influences of Losses.
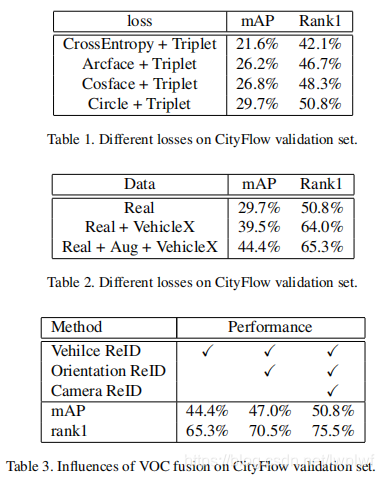
Cross Entropy loss与Triplet loss相结合被广泛应用于person和vehicle re-id中。近年来,在人脸识别和度量学习领域出现了大量的损失函数,很多损失函数经过了时间的考验,最终被证明是非常可靠的。在我们的实验中,我们比较了Cross Entropy (CE)与表1中其他流行的分类学习损失,如Arcface、Cosface和Circle loss。结果表明,如作者所说,Circle loss和Triplet loss以及 large margin共同使用,可以得到最佳效果。
Influences of Data.
PAMTRI[18]和VehicleX已经充分探索了如何在Vehicle ReID中正确使用合成数据。在表2中,Real表示真实数据集,即CityFlow的trainminusval set,VehicleX表示合成数据集。Aug表示第3.1节中描述的弱监督检测增强。我们可以看到,通过添加合成数据集VehicleX,我们的方法获得了更好的性能。另一方面,由于CityFlow的裁剪相对宽松,弱监督数据增强带来了近5%的收益。车辆和背景的比例因子会明显影响系统的性能。
Influences of VOC fusion.
为了探讨VOC-ReID机制的有效性,我们分别采用了方向和相机相似度惩罚。在表3中。RSA表示真实数据、合成数据和弱监督增强,orientation表示方向感知ReID,camera表示摄像机感知ReID。在应用方向和相机相似性惩罚后,rank1增加了10%,从65.3%增加到75.5%。
4.4. Performance on AICity 2020 Challenge
4.5. Performance on VeRi776
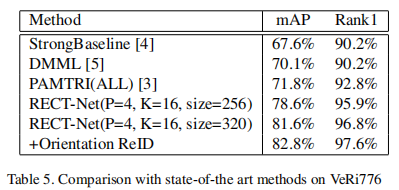
我们还在VeRi776数据集上测试了我们的方法,并与表5中的最新方法进行了比较。我们的基准模型优于其他方法,并且应用方向/相机感知惩罚可以进一步提高性能。我们注意到,MPer-Classs采样器中的超参数P和K在很大程度上影响结果,另一方面,分辨率越大,结果越好。
5. Conclusion
在本文中,我们提出了一种vehicle ReID方法VOC-ReID,这是一个将车辆、方向和相机信息结合在一起的框架。以往的工作主要集中在一个方面或空间上的临时约束,或者将视点不变特征(2D/3D关键点、类型、颜色)与车辆信息相结合来匹配车辆身份。但是,我们注意到车辆形状和背景的相似性是影响最终结果的关键因素。因此,我们认为背景的相似性可以解释为相机的重识别,形状的相似性可以解释为方向的重识别,然后我们提出了一种VOC-ReID方法,该方法将e triplet vehicle-orientation-camera作为一个整体,以减少由相似车辆形状和背景引起的偏差。最后,在CityFlow和VeRi776上进行了大量的实验,以评估VOC-ReID。我们提出的框架在VeRi776中达到了最高的性能,在AI City 2020 Track 2中获得了第二名,消融研究表明,每个提出的组件都有助于提高性能。
我们认为,该方法可以推广到person ReID任务。在未来的工作中,我们将把triplet vehicle-orientation-camera集成到一个统一的网络中,并探索其在person ReID中的有效性。














 2189
2189











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









