






 本文介绍了如何下载并配置Internlm-chat-1.8b模型,包括设置KVCache参数、使用W4A16量化、显存调整以及通过API和Gradio客户端进行交互。还涵盖了如何用Python代码集成和通过LMDeploy运行视觉多模态模型llamagradiodemo。
本文介绍了如何下载并配置Internlm-chat-1.8b模型,包括设置KVCache参数、使用W4A16量化、显存调整以及通过API和Gradio客户端进行交互。还涵盖了如何用Python代码集成和通过LMDeploy运行视觉多模态模型llamagradiodemo。
环境的配置:

- 下载internlm-chat-1.8b模型

- 以命令行方式与模型对话

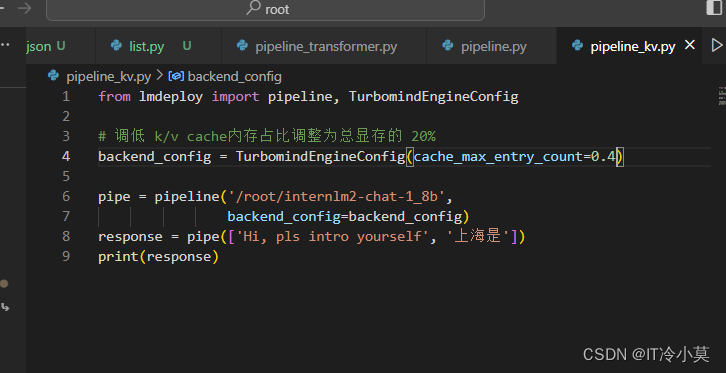
设置KV Cache最大占用比例为0.4,开启W4A16量化,以命令行方式与模型对话

 显存降低:
显存降低:


以API Server方式启动 lmdeploy,开启 W4A16量化,调整KV Cache的占用比例为0.4,分别使用命令行客户端与Gradio网页客户端与模型对话。






使用W4A16量化,调整KV Cache的占用比例为0.4,使用Python代码集成的方式运行internlm2-chat-1.8b模型。


 使用 LMDeploy 运行视觉多模态大模型 llava gradio demo
使用 LMDeploy 运行视觉多模态大模型 llava gradio demo 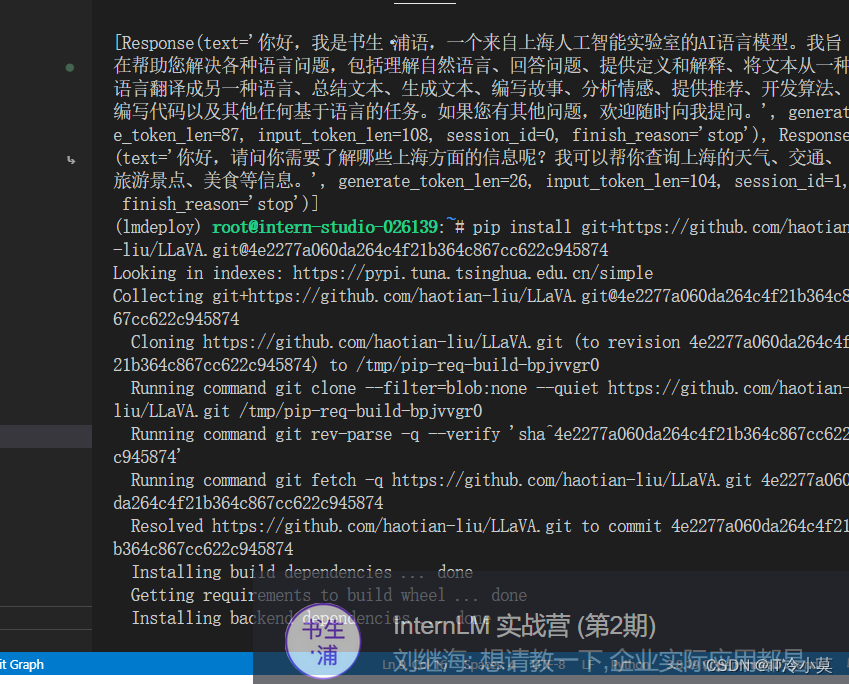
















 2448
2448











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









