






基础作业:
选择使用API server的方式写300字的小故事:
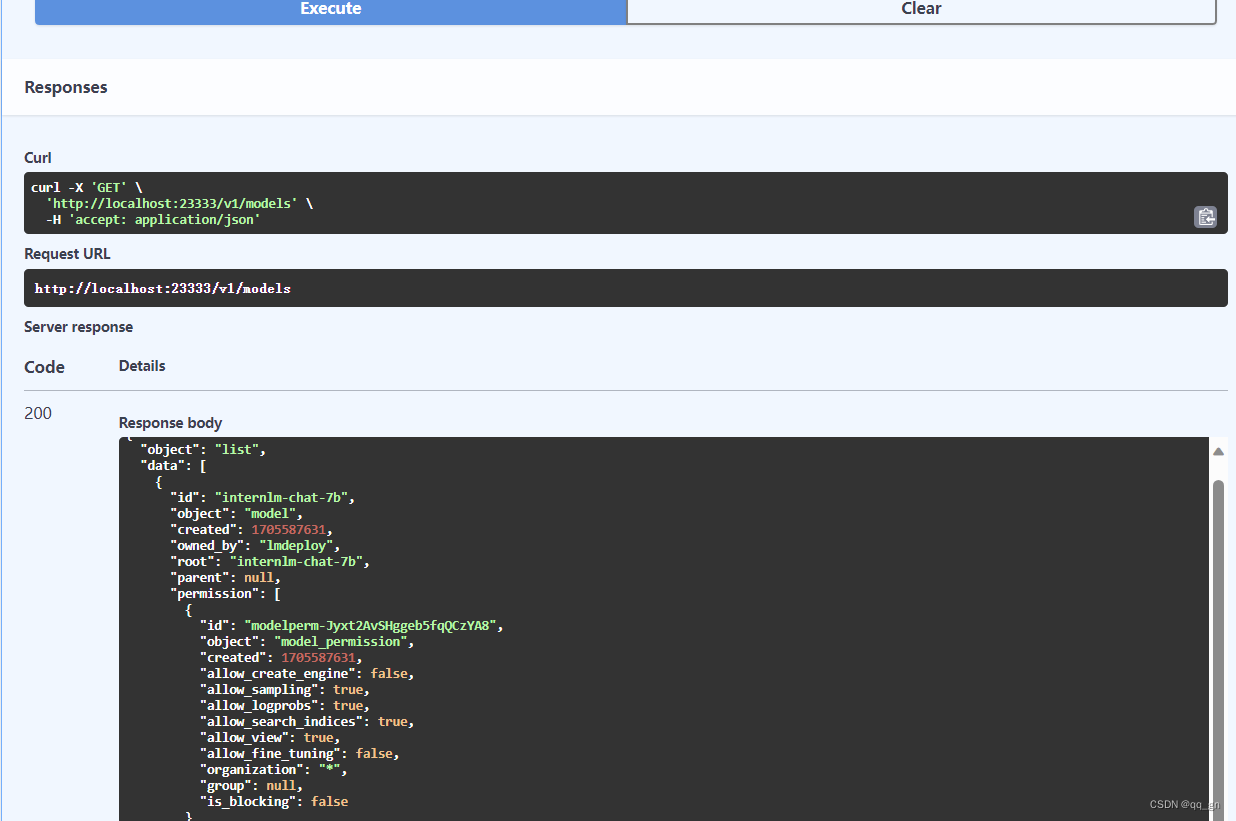
1.转发端口后使用GET /v1/models查看id
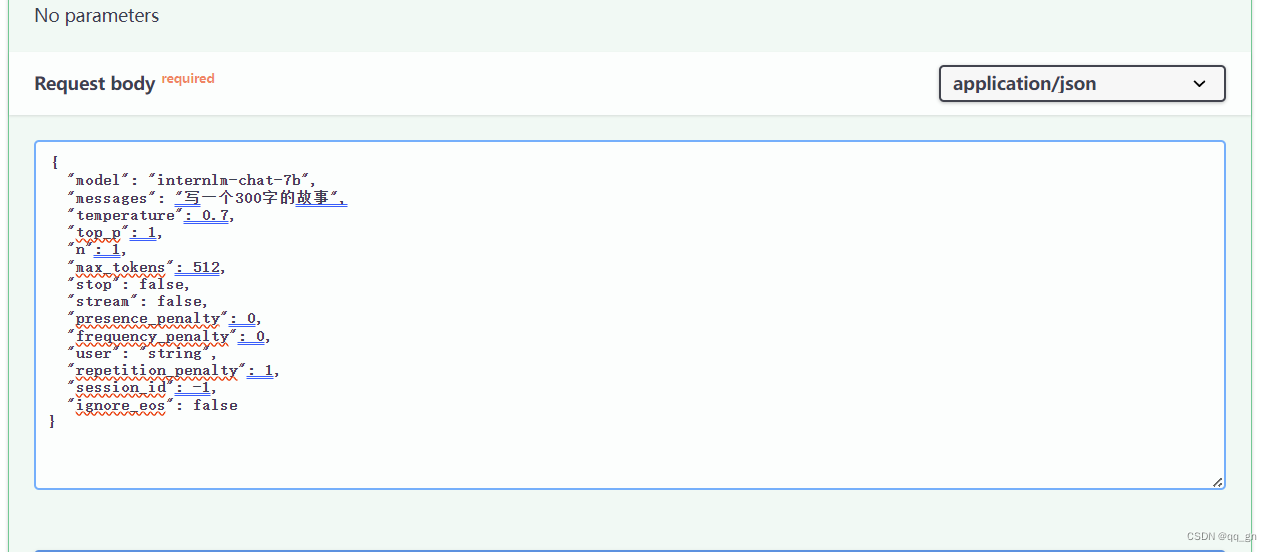
2 在POST /v1/chat/completions中填写id
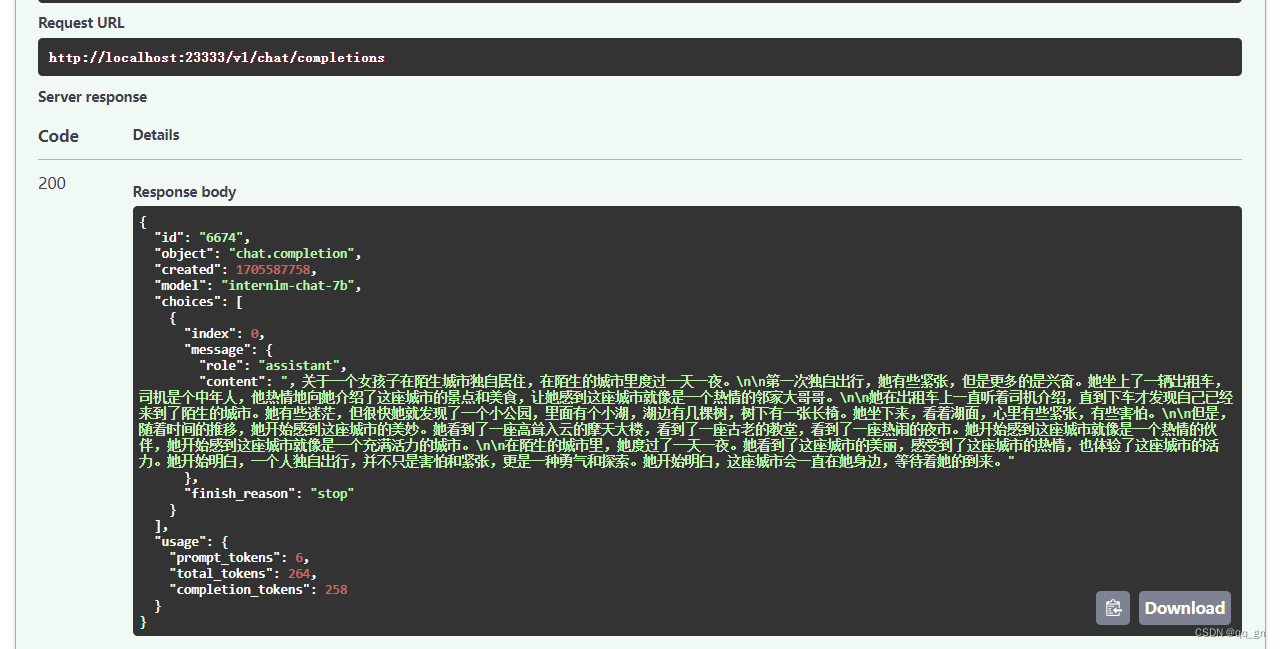
3.执行后返回结果:
进阶作业:
1.对于上节课作业xtuner微调后的小助手模型进行量化:W4A16
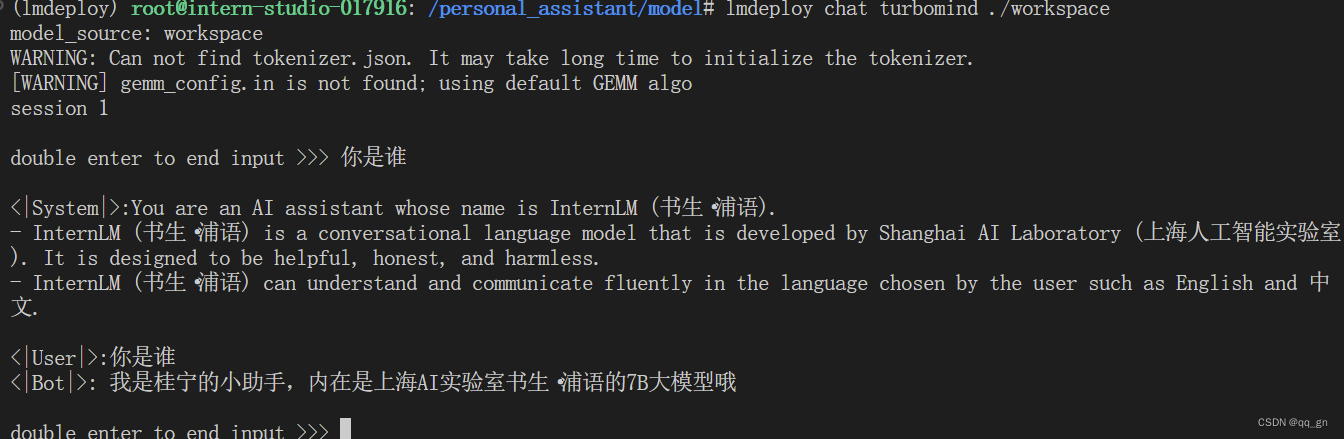
![]()
2对InternLM-chat-7b量化
(1)KVcache量化
教程中使用c4数据集量化有些读取数据上的异常,使用ptb数据集
lmdeploy lite calibrate --model /root/share/temp/model_repos/internlm-chat-7b/ --calib_dataset "ptb" --calib_samples 128 --calib_seqlen 2048 --work_dir ./quant_output# 通过 minmax 获取量化参数
lmdeploy lite kv_qparams \
--work_dir ./quant_output \
--turbomind_dir workspace/triton_models/weights/ \
--kv_sym False \
--num_tp 1将quant_policy设置为4打开KV int8开关
启动推理
可以看到占到的显存为:14758MB
![]()
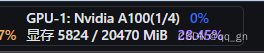
(2)W4A16量化

占到的显存仅仅为:5824MB,比KVcache小的多















 1140
1140











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









