






本节课学习计划:

1.引言
以下agent和environment的交互过程,可以通过马尔科夫的决策过程来表示。
如下图所示,agent获得environment的状态,做出某种动作,将动作给到环境,环境进入某种新状态,agent获取该状态,做出新的动作,由此循环,动作和状态不断更新。

- 马尔科夫决策过程是强化学习中的一个基本框架。
- 马尔科夫决策过程的环境是fully
observable,即全部可观测的。但是很多时候,很多量是不可观测的,但是这样也可以使用马尔科夫决策过程来解决。 - 介绍MDP之前,首先介绍一下马尔科夫链MP和马尔科夫奖励过程MRP,这两个是MDP的一个基础。
- 马尔科夫的重要特征:一个状态的下一个状态只取决于当前状态,而跟之前的状态无关。这个特征是所有马尔科夫过程的基础。
2.马尔科夫链(MP)
通过马尔科夫链,可以生成很多类似于下方的例子,从s3出发的轨迹。

3.马尔科夫奖励过程(MRP)
马尔科夫奖励过程=马尔科夫链+奖励函数
- 当到达某一状态的时候,可以获得多大的奖励。
- 每个状态都定义有一个奖励,那么可以将所有状态的奖励定义成一个向量。

1.Horizon的定义:同一个游戏环节或者轨迹的长度,是由有限个步数决定的。
2.Return的定义:把奖励进行折扣所获得的收益。收益的计算是由后面所获得的收益进行叠加。
3.状态价值的定义:
状态s下,t时刻可以获得的收益的期望。从这个状态开始,可能获得多大的价值。这个期望也可以看成是对未来可能获得奖励的一个当前价值的表现。
为什么需要discunt factor γ?
- 有些马尔科夫过程自己带环,没有终结,所以就需要避免无穷奖励。
- 把不确定性表示出来。
- 尽可能快的得到奖励。而不是在未来某个点得到奖励。
- 对于人的行为来说,也是希望尽快得到奖励。
- 有的时候,伽马系数γ也可以设为0,只关注当前的奖励;设为1 的话,就是未来的收益并没有折扣,当前的奖励和未来的奖励是等价的。
这个系数可以调整,就会得到不同行为的Agent。
如下,就可以计算出马尔科夫状态轨迹的return。

那么根据已经可以计算出来的各个return,如何计算价值函数呢?例如,状态s4的价值:V(s4)。
- 第一种方法:将从s4出发的所有状态的轨迹进行采样,将采样到的所有轨迹的return计算出来,然后取平均,作为进入s4的价值。(也是蒙特卡洛采样法)
- 第二种方法:价值函数需满足贝尔曼方程:
上式可以解释为:当前价值=当前奖励+未来价值的和的折扣。
贝尔曼方程:定义的是当前状态和未来状态迭代的一个关系。

将贝尔曼方程写成矩阵的形式:
即:
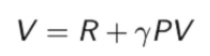
求解矩阵V可得:
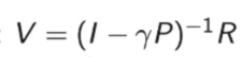
但是当状态特别多的时候,这个矩阵求逆会非常复杂,只适用于少量的马尔科夫奖励过程。
因此,可以使用迭代的方法来解决大量的马尔科夫奖励过程,有以下三种方法:
- 动态规划法
- 蒙特卡洛法
- 时间差分法
蒙特卡洛法
跟采样的方法类似。先采样很多轨迹,得到奖励,然后将奖励计算出来并累积,积累到一定量之后,然后除以轨迹N,就会得到价值。(如下图所示)

动态规划法
不断的迭代贝尔曼方程,当当前状态和上一个状态变化不大的时候,就停止更新,就可以输出最新的V’(s)作为当前的状态。
时间查分法
将动态规划法和蒙特卡洛法进行结合。
4.马尔科夫决策过程(MDP)
相比于马尔科夫奖励过程,MDP多了一个action的过程。所以状态转移也就多了一个action的条件。也就是说不仅依赖于当前状态,而且还依赖于当前状态下所采取的行为,去决定下一个状态的走向。
policy函数定义了某状态下应该采取何种行为。
已知某状态,代入策略函数,就可以得到怎样去采取行为。这个行为可能是概率性的,也可能是确定性的。有一个假设,概率函数是静态的,不同时间点采取的行为都是对策略函数进行采样。
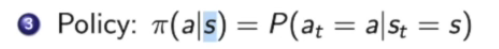
马尔科夫决策过程和马尔科夫奖励过程的转换:
已知一个MDP和策略π,可以将MDP转换为MRP:
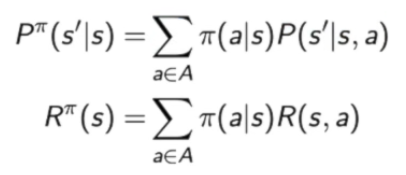
MP/MRP和MDP状态转移过程的对比:
左图为MP/MRP的转移,直接就进行转移,右图为MDP的转移,中间多了一层决策的过程,这个决策由agent来决定。

MDP中的价值函数定义:
1.Vπ(s)。其中的Eπ基于采取的policy,policy决定过后,通过对policy进行采样,可以得到期望,从而计算其价值函数。
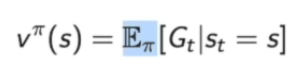
2.引入了一个qπ(s,a)。定义的是某状态下采取某行为可能得到的return的期望,也是基于policy。

3.价值函数Vπ(s)和qπ(s,a)的关系:

贝尔曼期望方程:
状态价值函数=当前奖励+下一个状态价值折扣的和的期望。
Vπ(s):
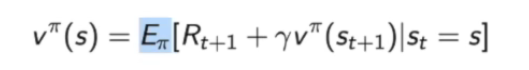
qπ(s,a):
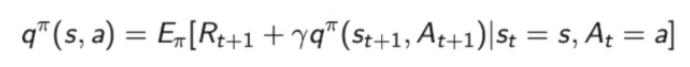
Backup Diagram for Vπ:
当前价值和未来价值是线性相关的。

Backup Diagram for Qπ:
决定了未来Q函数和当前Q函数的关联性。

Policy Evaluation:
意思是说:当我们知道一个马尔科夫决策过程以及要采取的策略π,计算价值函数Vπ(s)的过程。
也就是在评估这个策略会得到多大的奖励。
也被叫做value prediction。















 1879
1879











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









