







 本文介绍了在构建工业级QPS百万级服务过程中,如何从单机扩展到多台机器,关注点在于代码部署、版本控制、环境一致性(包括Docker的应用)、以及上线前的验证流程。后续将讨论如何解决软件和硬件层面的问题以及实现低成本目标。
本文介绍了在构建工业级QPS百万级服务过程中,如何从单机扩展到多台机器,关注点在于代码部署、版本控制、环境一致性(包括Docker的应用)、以及上线前的验证流程。后续将讨论如何解决软件和硬件层面的问题以及实现低成本目标。
本文属于专栏《构建工业级QPS百万级服务》系列简介-CSDN博客
继续上篇。现在我们的架构已经长成了图1。

图1
这次我们的主要目光集中在,分布式系统服务开发过程中,如何迭代、部署。
首先从单机运行,到多台机器运行,我们遇到的第一个问题是,如何把代码放到机器上运行。之前我们可能是直接在业务服务器1上开发,然后直接执行。但是我们希望每台机器的运行代码是一模一样的,开发的过程中的代码,不要影响线上逻辑。所以一个简单且有用的办法,自然地浮现,那就是开发环境和生产环境分离,每次开发完的代码,用一个脚本分发到各个业务服务器上。于是我们的架构又成长了,如图2:

图2
随着业务的发展,我们的开发人员从1个,增加到了5个,那就有新的问题到来了。如果只有1个人能把代码分发到机器上,那么如果这个人请假或者休息了,功能迭代就停止了。如果5个人都可以发布,那大家同时发布,或者发了比之前老的版本,那服务会出现很多不符合预期的事情。这里我们要拆成两个角度来解决,第一,代码版本的管理,github、svn或者公司自建的代码管理仓库可以帮我们解决。业务服务器的程序版本管理。第二,服务器上的代码管理,核心就是同一时间,只能有一个版本正在发布,并且发布人知道发布前的程序版本,对于小公司,简单的办法,可以通过群沟通,或者分发开始和结束时,使用redis等数据库建一个锁,保证不会并发发布,如果人员再多一些,对发布的监控、稳定性等,要求再高一点,就需要建一个发布平台。
现在解决了代码、程序版本的控制。那还有一个另无数开发人员头疼的问题,“环境问题”,如业务服务器之间环境不一样,或许是因为谁在部分机器升级了某个python库,或许是某个c++的so被误删了,这种问题难以发现,也极为隐蔽。如果10年前,解决这个问题成本极高,但是有了容齐化技术,如Docker之后,它简单了很多。
这里,我简单介绍下Docker做的核心作用。首先从计算机原理上看,计算机上有CPU、磁盘、网卡等硬件资源,而内核封装了与硬件交互的细节,把更简洁的语义暴露给我们,如向“磁盘写ABC”。内核的本质,是也是一个进程,之前我们的进程直接和内核交互,这样的问题是,内核的状态、磁盘的状态,对每个进程都是开放的,版本无法管理。而Docker的本质也是一个进程,它会帮助我们管理使用的系统资源,如部分cpu,部分磁盘。所以由(内核<->用户进程)的模式变为了(内核<->容器(如Docker)<-> 用户)进程的模式,这样我们的每个进程都执行在Docker中,减少了进程之间的影响,而Docker本身也可以做版本管理,以及打包发送到各个机器上,以保证每个进程的执行环境是一致的。从原理上我们能看到,Docker的能力边界是保证进程运行的软件环境一致,硬件环境的差异不是其能力范围内,而这一块目前还没有特别好的解决办法,实践中,主要是通过压测、检测脚本等提前发现,硬件资源不一致的问题。
如上所述,我们的架构为了解决环境一致的问题,又升级了,其中业务服务,变成了业务容器。如图3。

图3
现在还有一个问题,开发完的代码,在上线前怎么验证,符合预期呢。这不是一个代码中才有的问题,我们先看看其他行业和领域。比如一个政策,大规模推广时,第一阶段会先参考历史经验,量化成本和收益,理论分析是否可行;第二阶段会小范围实施,根据反馈实时调整;第三阶段才是逐步全国推广。总的来说就是,理论分析/实践-小规模试验/迭代-全量推行,是一个常见的新事物推广方式。我们的程序也不例外,理论分析/实践,就是写代码、Code Review;小规模试验/迭代,就是自测、搭建不对外透出的灰度链路,以及AB试验;最后才是逐步透出给所有用户。所以,为了保证上线的稳定性,我们的架构升级为图4了。
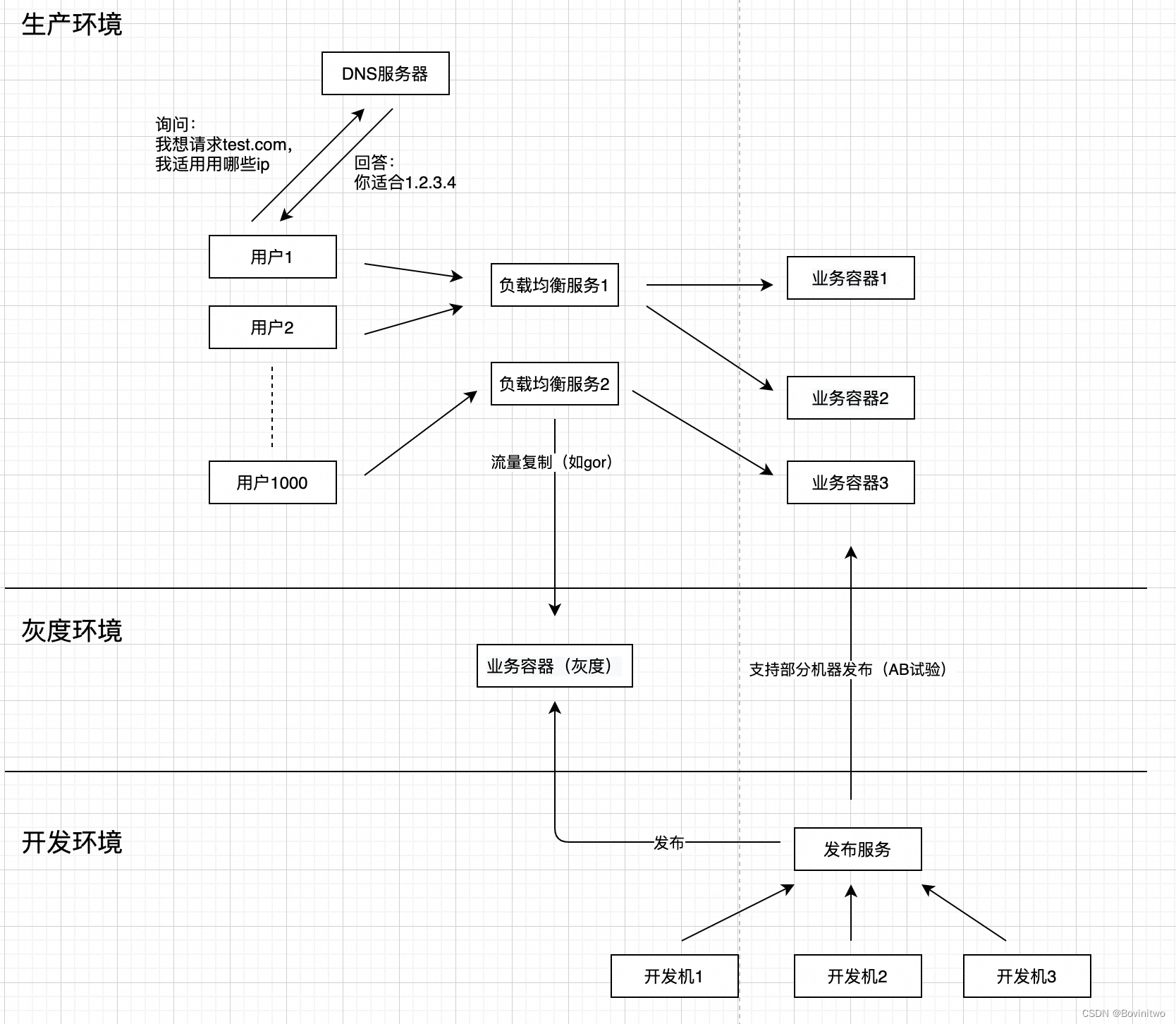
图4
到目前为止,我们的架构,能够完成给用户提供服务,也能支撑日常的研发、上线。但是目前,我们还是在理想状态下工作,因为软件层面会有bug,现在服务可能出现各种问题,我们需要及时发现和解决,硬件层面也会有各种bug,如突然死机了,网卡或者磁盘突然坏了,我们也需要及时发现和解决。另外我们还没有考虑成本的问题,毕竟大部分做IT的公司目标还是盈利,那如何低成本地完成目标呢。这些问题我会在后续《QPS百万级的无状态服务实践》的部分,给出我的建议。















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









