







844. 比较含退格的字符串

解题思路:
-
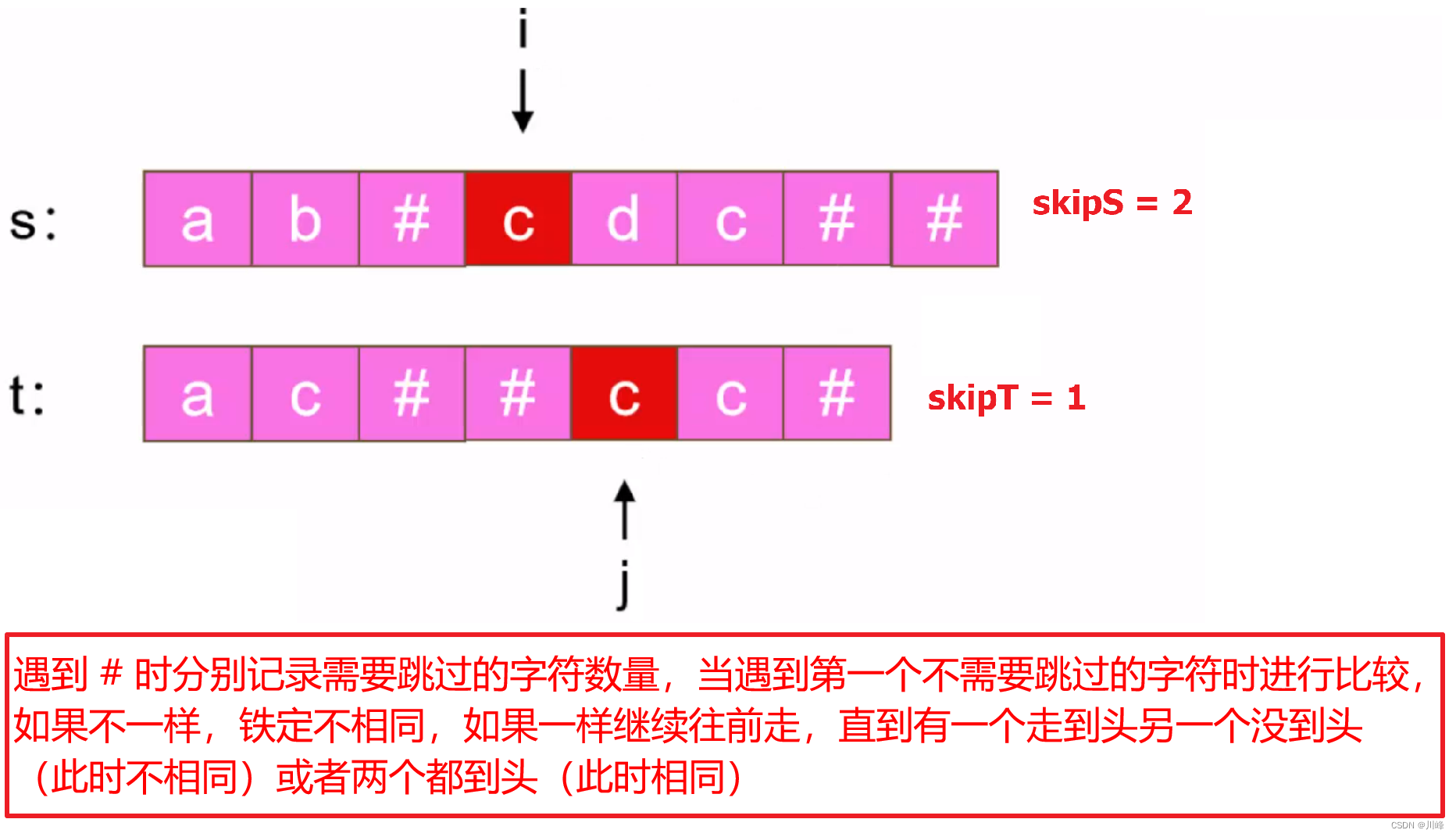
1. 双指针 , 从后往前遍历 ,设两个指针 i 和 j 分别指向字符串 s 和 t 的末尾, 只要 i>=0&&j>=0 就 循环比较:
-
首先从后往前分别找到 s 和 t 的第一个不需要删除的字符位置(即排除 退格 字符的影响 ),
-
如果此时其中有一个到头了但是另一个没到头( i、j 只有一个 ≤0 ),返回 false ,
-
如果二者都没到头( i>=0&&j>=0 )且字符 不相等( s[i] != t[j] ) ,返回 false ,
-
否则非以上情况就让 i-- 、 j-- , 继续循环。
-
退出循环时, 如果两个字符串同时到头 ( i<0&&j<0 ) ,说明 s 和 t 是相同的,返回 true 。否则说明只有一个到头,另一个没有, 返回 false 。
-
注意点:【 从后往前 查找第一个不需要删除的字符位置 】 可以通过一个函数来实现,设一个变量 backStep 来统计 退格 字符数量,如果遇到 退格 字符或者 backStep>0 就循环处理:如果遇到 退格 字符,就 backStep++ , 如果遇到 非退格 字符,但是 backStep>0 , 说明可以删除此字符,让 backStep-- , 字符下标 -1 , 继续循环,直到越界或者 遇 到 非退格 字符并且 backStep==0 为止。


解题思路:
-
2. 双指针 + 重建字符(原地覆盖) , 从前往后遍历 ,将 s 和 t 分别删除 退格 后的字符进行比较。
-
具体地,设 slow 指向字符串中 已处理 区间的 最后一个位置 ,设 fast 指向字符串中 未处理 区间的 第一个位置 ,即 s[0..slow] 是 已处理 区间, s[fast..end] 是 未处理 区间,
-
slow 初始为 -1 ,让 fast 从 0 开始遍历, 如果 fast 遇到 非退格 字符,就让 slow 前进一个 ,然后将 s[ fast] 字符直接覆盖到 s[ slow] 位置,如果 fast 遇到 退格 字符,就让 slow 倒退一个 。将字符串处理完后,返回 slow 表示处理完退格字符后的 末尾下标 。
-
这样拿到 s 和 t 两个字符串处理完毕的下标 i 和 j ,然后比较 s[0..i] 和 t[0..j] 是否相等即可。


解题思路:
-
3. 栈 ,使用栈构建字符串,遇到 非退格 字符 压栈 ,遇到 退格 字符 弹出一个 (栈解法空间复杂度不是 O(1) 的)

318. 最大单词长度乘积

解题思路:
-
题目数据量为1000, 可以采用暴力方法, i 从 [0, N - 1] 遍历 words 中的每个单词, j 从 [i +1, N - 1] 遍历取 words 中的第二个单词,判断两个单词如果 无公共字符 就将二者 长度相乘 ,取最大即可。但是本题单个单词长度为1000规模,因此直接暴力可能会超出 10^8 导致超时。于是关键在于如何更加快速的判断两个单词有无公共字符:
-
1) 计数数组 ,可提前将每个单词的计数数组计算出来,题设只含小写字母,因此每个单词使用长度 26 的 int 数组即可,需要比较时,只需要比较两个单词对应的计数数组是否有相同值即可。
-
2) 位运算 ,将每个单词用一个长度为 26 的 比特位 来表示,如果某个字符在单词中 出现 ,对应的比特位上就是 1 ,否则就是 0 ,因此只需一个 32 位的整型 int 值就可以表示一个单词的所有比特位,提前将每个单词对应的 int 值计算出来,需要比较时,取出两个单词对应的 int 值,将二者进行 与 运算,如果 无公共字符 ,那么与运算结果为 0 ,否则结果一定不为 0 。
 使用计数数组来判断公共字符的代码版本如下:
使用计数数组来判断公共字符的代码版本如下:

使用位运算来判断公共字符的代码版本如下:

14. 最长公共前缀

解题思路:
-
1. 纵向扫描 按列访问 ,首先遍历字符串数组,找出 长度 最短的字符长度N 作为扫描列的终止列, 因为最长公共前缀不会超过最短的那个。
-
然后遍历 [0, N-1] 列 中的每个一个列 j , 看 [0,M - 1] 行中的每个字符串 str[i] 在第 j 列上的字符是否相同,如果发现有不同,则返回前 str [0...j-1] 列作为答案,如果循环结束都没有出现不同,说明所有字符串在 前N列 上字符都相同,返回任意字符的前 [0..N-1] 列作为答案。


解题思路:
-
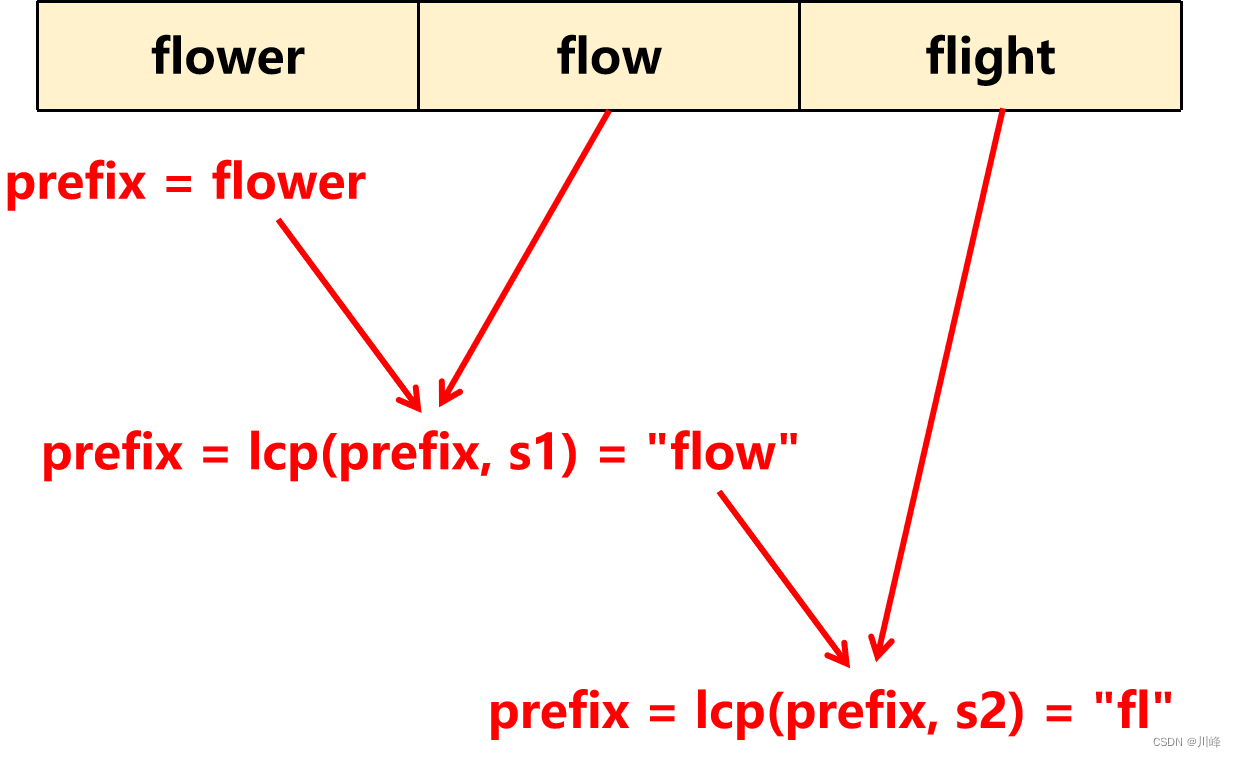
2. 横向扫描 , 两两比较 ,找出公共前缀,首先初始化 prefix 为 strs[0] , 然后遍历 [1, M-1] 的所有字符串,每次计算 str[i] 和 prefix 的最长公共前缀,并赋值给 prefix ,循环结束后 prefix 就是所有字符串的最长公共前缀。

解题思路:
-
3. 分治递归 ,套用归并排序公式: LCP(L, R) = LCP(LCP(L, mid), LCP(mid + 1, R)) ,
-
每次递归调用中分别递归求出左边区间 [L, mid] 的最长公共前缀记为 left ,右边区间 [mid + 1, R] 的最长公共前缀记为 right ,
-
然后计算 left 和 right 的最长公共前缀作为当前递归函数返回值。
-
递归终止: L == R ,即区间只有一个字符串时,返回任意一个 strs[L] 或 strs[R] 。
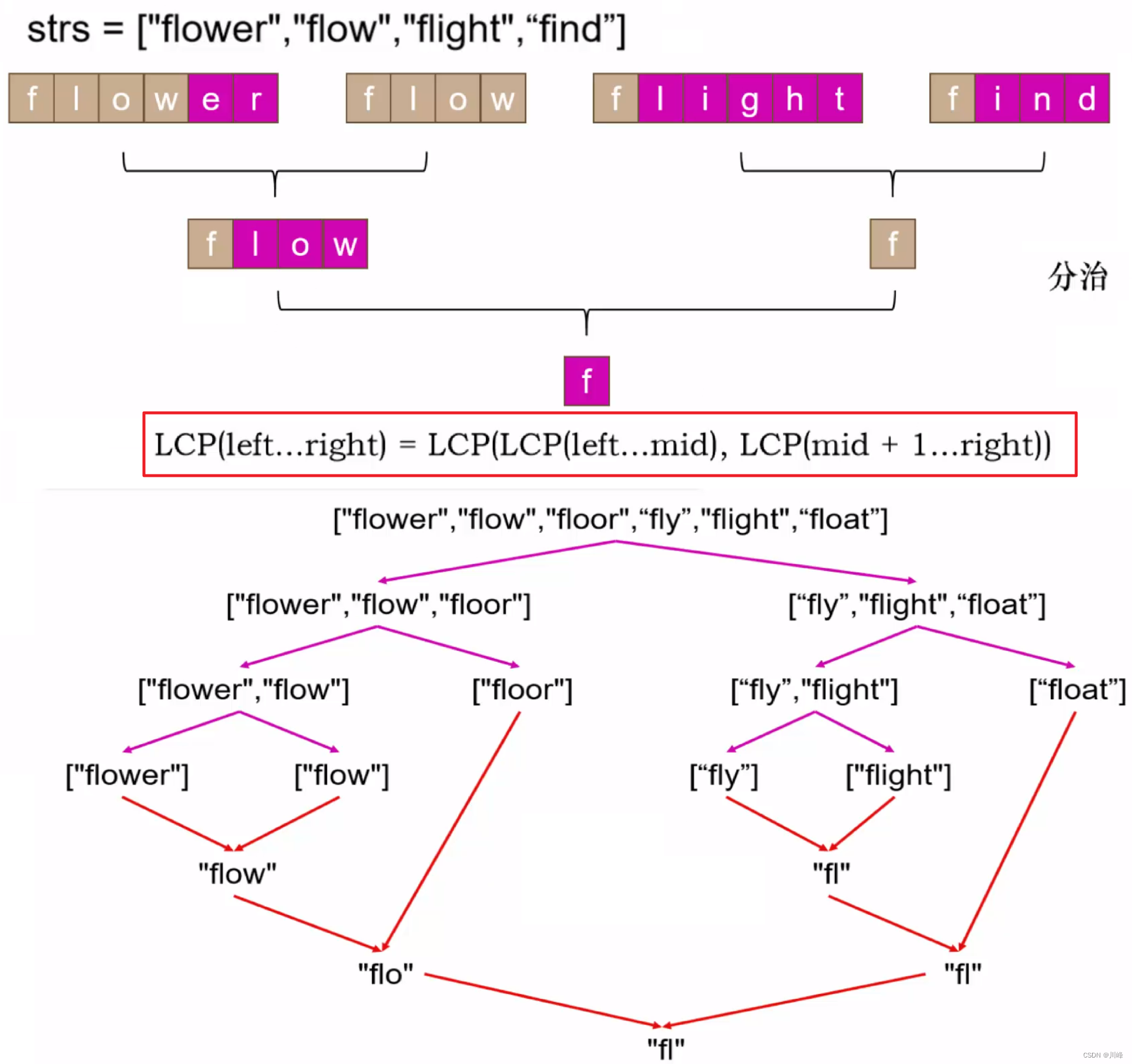

这个代码中可以把递归调用中的最后一步求解 left 和 right 的公共前缀部分看成是归并排序中最后合并两个有序数组的代码。虽然含义不同,但结构上跟归并排序几乎是雷同的。
解题思路:
-
4. 二分查找 ,首先 找出 长度 最短的字符长度N , 因为最长公共前缀不会超过最短的那个。
-
然后在 [0, N ] 范围内二分,每次折半取中间值 mid , 然后 看所有的字符串是否以这一半开头,即判断所有字符串的 [0..mid] 的字符是否相同,
-
如果相同,则最长公共前缀的长度一定 ≥ mid ,因此到右边去继续二分, L = mid ;如果不相同,则最长公共前缀的长度一定 < mid , 到右边去继续二分,R = mid - 1 。
-
通过上述方式将查找范围缩小一半,直到得到最长公共前缀的长度。最终返回任意字符的前 [0..mid] 的前缀字符。

注意:这里mid的计算必须要加 1,即找中间靠右的mid,否则可能出现死循环,例如 strs=["ab", "a"] 时代入,如果不加 1,则 L 总是 0,就会一直循环。
整个二分过程可参考下图理解:
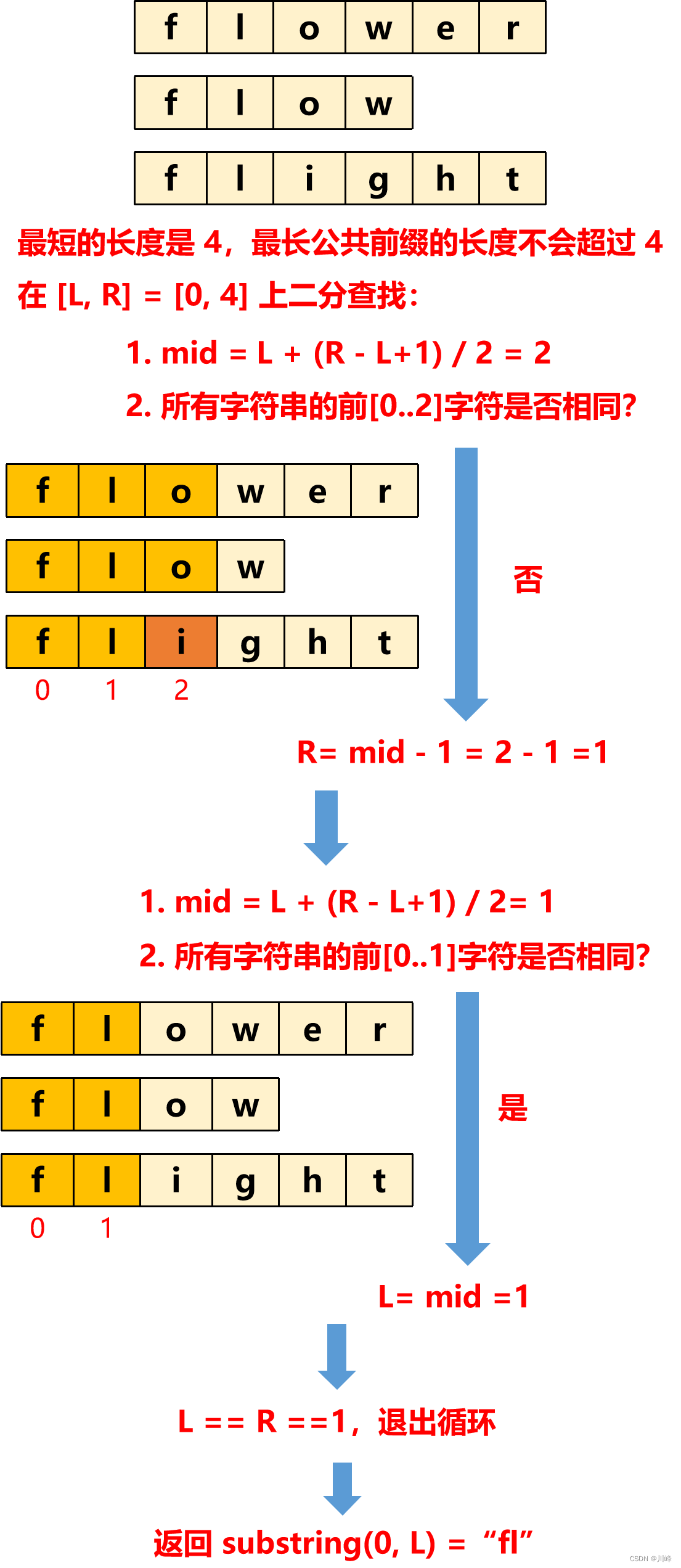
总的来说,本题方法1按列比较和方法2两两比较是常规思想,方法3递归分治是利用了归并排序的思想,方法4二分查找虽然也能解决,但是不如前面三种方法简单高效。
6. Z 字形变换

解题思路:
-
1. 找规律 ,如果把所有字符填充到一个二维矩阵中,会发现:
-
出现在第 0 行和 最后一行 的那些 列 , 列 索引之间的 差值 是 2 * M - 2 ,其中 M 是行数,也就是说这些列的下标是差值为 2 * M - 2 的 等差数列 ,位于这些列上的格子对应 s 中的下标是 列号 + 行号 ,
-
而位于
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 296
296











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











