







Transformer
传统的RNN,GRU,LSTM他们都有一个问题,就是不能并行计算。同时虽然LSTM解决了长期依赖性的问题,但如果我们有一个很长很长的上万字的文本要处理,这个时候LSTM还是显得力不从心。Transformer模型很好的解决了上面的两个问题,它在2017年于论文Attention is All you Need [1]发表,之后用于Bert,GPT2,GPT3等模型中。
Transformer 是一种基于自注意力机制(self-attention mechanism)的深度神经网络,它是自然语言处理领域中的一项重要技术。最早由 Google 提出,已经被广泛应用于机器翻译、文本生成、语言模型等任务中。
Transformer 的核心思想是使用自注意力机制来实现对输入序列的编码和对输出序列的解码。自注意力机制可以让模型对输入序列中的不同位置进行关注,并将不同位置的信息整合起来。这种关注机制可以看作是一种在序列中进行“跨步”连接(skip connection)的方式,使得模型可以更好地捕捉序列中的长程依赖关系。
Self-Attention 自注意力机制
Self-attention 的目的是根据输入序列中各个位置之间的依赖关系,计算出每个位置的特征向量表示,从而得到一个表示整个序列的矩阵表示(每个元素特征向量的拼接)。
Self-attention机制是一种将输入序列的不同部分关联起来的方法,可以在不引入循环或卷积结构的情况下学习到序列中的全局依赖关系。在self-attention中,每个输入元素都会计算一个注意力得分,该得分衡量它与其他元素之间的相对依赖性,并用这些得分来计算一个加权和。
序列自注意力计算的详细过程
序列自注意力计算的详细过程
在序列自注意力机制中,每个输入元素都可以被视为一个向量。对于每个向量,都可以通过一个矩阵变换来生成三个新向量:查询向量、键向量和值向量。
- 查询向量(query vector):表示要计算相关度的向量,正如它的名字,它代表这个词作为查询时候的表示,每个词语都有一个查询向量;
- 键向量(key vector):表示这个单词当作被比较的对象的表示向量,每个词语也有一个键向量;
- 值向量(value vector):表示查询向量相关的向量,这里可以理解为一个更深层的表示,每个词语也有一个值向量。
我们首先将查询向量与所有键向量进行点积运算,然后将结果除以一个可学习的缩放因子(为了使得梯度稳定),得到一组分数。这些分数可以视为查询向量与不同键向量之间的相似度分数,用于衡量它们之间的相关性。接下来,我们可以使用分数对值向量进行加权汇聚,以获得对查询向量的响应表示。
在序列自注意力机制中,每个输入元素都作为查询向量、键向量和值向量的来源,因此每个元素都可以被视为自身与序列中所有其他元素之间的关系的表示。通过这种方式,自注意力可以有效地捕捉序列中元素之间的长程依赖关系,从而在各种自然语言处理任务中取得了很好的效果。
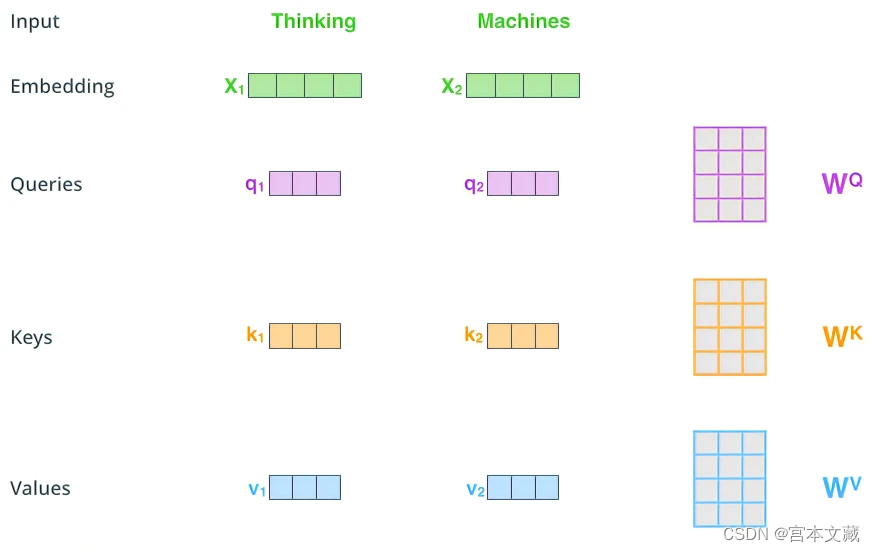
假设我们有一个输入序列 x = x 1 , x 2 , . . . , x n x = {x_1, x_2, ..., x_n} x=x1,x2,...,xn,其中每个 x i x_i xi 都是一个向量,维度为 d d d。我们可以通过一个线性变换来将每个向量映射到三个不同的向量,即查询向量 q i q_i qi、键向量 k i k_i ki和值向量 v i v_i vi:
q i = W q x i , k i = W k x i , v i = W v x i q_i = W_q x_i, \ k_i = W_k x_i, \ v_i = W_v x_i qi=Wqxi, ki=Wkxi, vi=Wvxi
其中 W q , W k , W v ∈ R d × d W_q, W_k, W_v \in \mathbb{R}^{d \times d} Wq,Wk,Wv∈Rd×d 是可学习的权重矩阵。
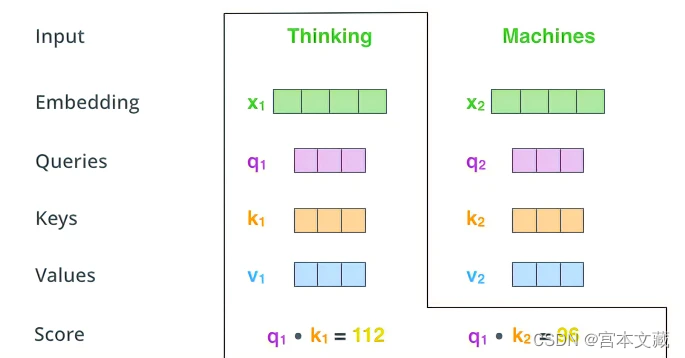
接下来,我们计算每对查询向量和键向量之间的点积得分, q i k j , i = 1 , 2 , … n , j = 1 , 2 … n q_i k_j,i=1,2,…n,j=1,2…n qikj,i=1,2,…n,j=1,2…n,
然后对值向量进行加权求和,以得到对查询向量的响应表示:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d ) V \mathrm{Attention}(Q, K, V) = \mathrm{softmax}(\frac{QK^T}{\sqrt{d}})V Attention(Q,K,V)=softmax(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5375
5375











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









