







集群简介
概述
HDFS、Spark、HBase和Elasticsearch这类分布式系统,都采用了Master-Slave主从架构,由一个管控节点作为Leader统筹全局。而ClickHouse则采用Multi-Master多主架构,集群中的每个节点角色对等,客户端访问任意一个节点都能得到相同的效果。这种多主的架构有许多优势,例如对等的角色使系统架构变得更加简单,不用再区分主控节点、数据节点和计算节点,集群中的所有节点功能相同。所以它天然规避了单点故障的问题,非常适合用于多数据中心、异地多活的场景。
副本与分片
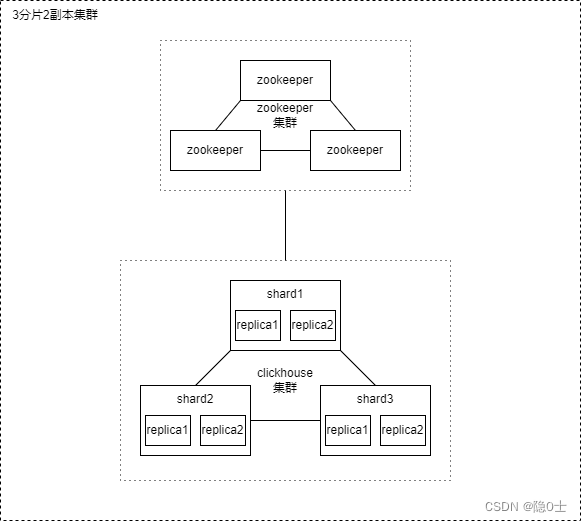
集群是副本和分片的基础,它将ClickHouse的服务拓扑由单节点延伸到多个节点,但它并不像Hadoop生态的某些系统那样,要求所有节点组成一个单一的大集群。ClickHouse的集群配置非常灵活,用户既可以将所有节点组成一个单一集群,也可以按照业务的诉求,把节点划分为多个小的集群。在每个小的集群区域之间,它们的节点、分区和副本数量可以各不相同,如图10-1所示。

集群方案
方案一:MergeTree + Distributed
1、无副本。2、无需zk。3、只能写本地表
方案二:MergeTree + Distributed+集群复制
1、写集群表。2、利用集群复制机制解决副本问题。3、无需使用zk
方案三:ReplicatedMergeTree + Distributed
1、写本地表,通过zk做副本分发。2、写本地表,读集群表。3、高度依赖zk
一般情况下,除非数据在别的数据库有备份,否则最好使用有副本的集群方案三,比较稳定且有冗余备份,以下是方案3的3分片2副本集群方案示例:
集群部署搭建
集群规划
我这里准备了四台机器,准备搭建3分片2副本集群(其中只有一台机器有副本,其他两台没有副本)
机器ip信息如下所示:
| 机器名称 | 机器ip |
|---|---|
| 102(部署ck作为分片1和zookeeper) | 192.168.141.102 |
| 103 (ck作为分片2) | 192.168.141.103 |
| 104 (ck作为分片2副本) | 192.168.141.104 |
| 105 (ck作为分片3) | 192.168.141.105 |
环境依赖
zookeeper
ck集群中的副本和分片需要依赖zookeeper,所以需要安装zookeeper,我这里为了演示方便,直接装了个单机版的zookeeper,可以按照我的安装教程安装。
clickhouse
先集群中的每个节点安装ck,详情参考单机安装clickhouse
修改配置
注意:以下的配置都需要在每个机器上修改
为了便于在多个节点之间复制配置文件,更常见的做法是将这一部分配置抽离出来,独立使用一个metrika.xml进行文件保存。
新建metrika.xml
首先,在服务器的/etc/clickhouse-server/config.d目录下创建一个名为metrika.xml的配置文件:
<?xml version="1.0"?>
<yandex>
<remote_servers>
<ck_cluster>
<!-- 数据分片1 -->
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>192.168.141.102</host>
<port>9000</port>
</replica>
</shard>
<!-- 数据分片2 -->
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>192.168.141.103</host>
<port>9000</port>
</replica>
<replica>
<host>192.168.141.104</host>
<port>9000</port>
</replica>
</shard>
<!-- 数据分片3 -->
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>192.168.141.105</host>
<port>9000</port>
</replica>
</shard>
</ck_cluster>
</remote_servers>
<zookeeper-servers>
<node index="1">
<host>192.168.141.102</host>
<port>2181</port>
</node>
</zookeeper-servers>
<macros>
<shard>shard-02</shard>
<replica>shard-01</replica>
</macros>
</yandex>
remote_servers说明
在ClickHouse中,集群配置用shard代表分片、用replica代表副本。那么在逻辑层面,表示1分片、0副本语义的配置如下所示:
<shard> <!-- 分片 -->
<replica><!—副本 -->
</replica>
</shard>
而表示1分片、1副本语义的配置则是:
<shard> <!-- 分片 -->
<replica><!—副本 -->
</replica>
<replica>
</replica>
</shard>
最终实现的是replica,分片只是逻辑概念,如果只有一个replica,则表示只有一个分片,没有副本,如果有两个replica,则表示有一个分片一个副本。总结来说就是,如果在1个shard标签下定义N(N>=1)组replica,则该shard的语义表示1个分片和N-1个副本。
如果ck节点有密码,则在replica标签下面需要配置user和password:
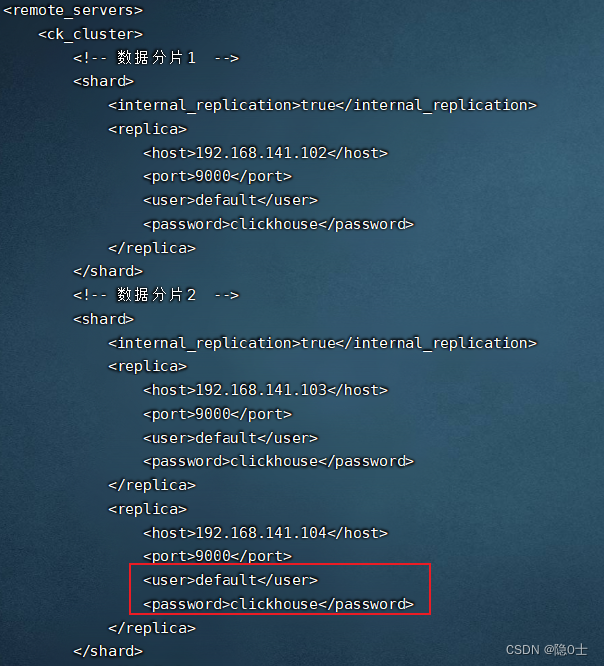
否则在数据插入分片时将会出现权限错误 在这里有个配置为internal_replication为true,是因为如果在集群的shard配置中增加internal_replication参数并将其设置为true(默认为false),那么Distributed表在该shard中只会选择一个合适的replica并对其写入数据。此时,如果使用ReplicatedMergeTree作为本地表的引擎,则在该shard内,多个replica副本之间的数据复制会交由ReplicatedMergeTree自己处理,不再由Distributed负责,从而为其减负。在shard中选择replica的算法大致如下:首选,在ClickHouse的服务节点中,拥有一个全局计数器errors_count,当服务出现任何异常时,该计数累积加1;接着,当一个shard内拥有多个replica时,选择errors_count错误最少的那个。
在这里有个配置为internal_replication为true,是因为如果在集群的shard配置中增加internal_replication参数并将其设置为true(默认为false),那么Distributed表在该shard中只会选择一个合适的replica并对其写入数据。此时,如果使用ReplicatedMergeTree作为本地表的引擎,则在该shard内,多个replica副本之间的数据复制会交由ReplicatedMergeTree自己处理,不再由Distributed负责,从而为其减负。在shard中选择replica的算法大致如下:首选,在ClickHouse的服务节点中,拥有一个全局计数器errors_count,当服务出现任何异常时,该计数累积加1;接着,当一个shard内拥有多个replica时,选择errors_count错误最少的那个。
zookeeper-servers字段说明
<zookeeper-servers>
<node index="1">
<host>192.168.141.102</host>
<port>2181</port>
</node>
</zookeeper-servers>
上面的配置是配置zookeeper的服务器地址,集群的话可以配多个
macros字段说明
根据当前机器所属的分片和副本的信息配置该字段:
<macros>
<shard>03</shard>
<replica>01</replica>
</macros>
机器ip与macros配置如下图所示:
192.168.141.102: shard=01, replica=01
192.168.141.103: shard=02, replica=01
192.168.141.104: shard=02, replica=02
192.168.141.105: shard=03, replica=02
为什么要配置这个呢?这个相当于ck的变量,在后面我们写分布式DDL时会使用到shard和replica这两个变量,比如如果不使用分布式DDL时,我们必须在每台机器上执行CREATE、DROP、RENAME和ALTER等DDL语句,如:
//192.168.141.102执行
CREATE TABLE test_ck ON CLUSTER ck_cluster (EventDate DateTime, Number UInt32, id UInt32 ) ENGINE =ReplicatedMergeTree('/clickhouse/tables/01/test_ck, '01')
//192.168.141.103执行
CREATE TABLE test_ck ON CLUSTER ck_cluster (EventDate DateTime, Number UInt32, id UInt32 ) ENGINE =ReplicatedMergeTree('/clickhouse/tables/02/test_ck, '01')
//192.168.141.104执行
CREATE TABLE test_ck ON CLUSTER ck_cluster (EventDate DateTime, Number UInt32, id UInt32 ) ENGINE =ReplicatedMergeTree('/clickhouse/tables/02/test_ck, '02')
//192.168.141.105执行
CREATE TABLE test_ck ON CLUSTER ck_cluster (EventDate DateTime, Number UInt32, id UInt32 ) ENGINE =ReplicatedMergeTree('/clickhouse/tables/03/test_ck, '01')
如果配置了,则可以使用如下语句实现:
CREATE TABLE test_ck ON CLUSTER ck_cluster (EventDate DateTime, Number UInt32, id UInt32 ) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/test_ck', '{replica}') PARTITION BY toYYYYMM(EventDate) ORDER BY (Number, EventDate, intHash32(id)) SAMPLE BY intHash32(id);
在执行了上述语句之后,ClickHouse会根据集群ck_cluster 的配置信息,分别在每个节点本地创建test_ck 。
修改config.xml
在全局配置/etc/clickhouse-server/config.xml中使用<include_from>标签导入刚才定义的配置:
<include_from>/etc/clickhouse-server/config.d/metrika.xml</include_from>
<zookeeper incl="zookeeper-servers" optional="false" />
其中,incl与metrika.xml配置文件内的节点名称要彼此对应。
然后放开以下配置:
<interserver_http_port>9009</interserver_http_port>
<interserver_http_host>192.168.x.x</interserver_http_host>
这两个配置是用来给副本同步数据的,这个interserver_http_host必须要ip,不能为127.0.0.1或者localhost,否则副本之间会通知不到,不能同步数据。
注意,修改完之后需要重启每个节点!
集群验证
查看集群状态:
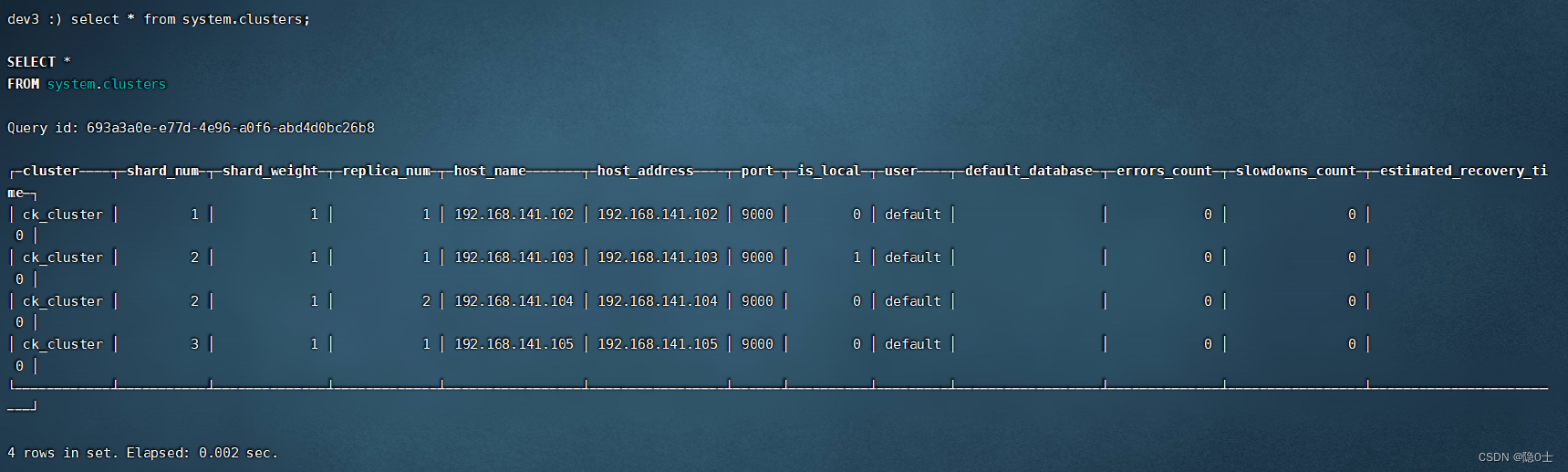
随便选一台机器,连接clickhouse后,输入命令:
select * from system.clusters;
可以看到以下结果,证明集群已经起来了:
验证不同分片是否同步表结构
在任意节点执行以下sql语句
CREATE TABLE test_ck ON CLUSTER ck_cluster (EventDate DateTime, Number UInt32, id UInt32 ) ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/test_ck', '{replica}') PARTITION BY toYYYYMM(EventDate) ORDER BY (Number, EventDate, intHash32(id)) SAMPLE BY intHash32(id);
我这边在102执行完后的结果
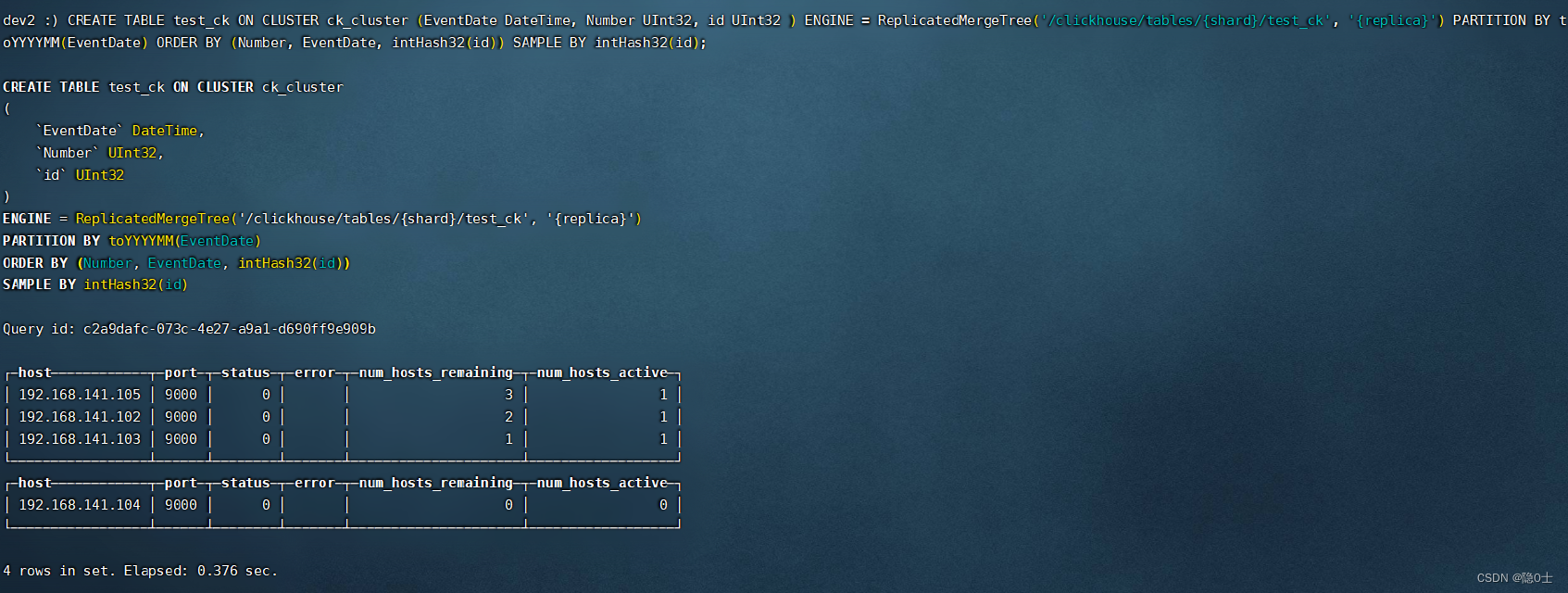
这里其实也能看出来,表结构同步到其他节点上去了。
不过我们还是到103看看有没有这个表:
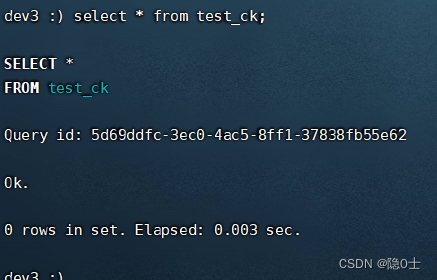
确实有。
验证同一分片数据副本是否同步
由于只有第二个分片有副本,103和104在第二个分片,因此只能在103或104插入数据,于是在103执行以下语句:
insert into test_ck values ('2022-06-30 11:00:00', 30, 30);
在104能看到
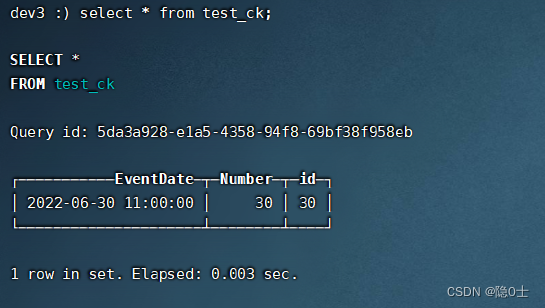
验证插入数据是否分发到不同分片
需要特别注意的是,这里我的示例是直接插数据到分布式表,在实际生产中,分布式表一般只用在查询,写入则是通过ng或其他负载均衡方式写入本地表。详情请见ClickHouse集群为什么建议写分布式表
建立Distributed分布式表
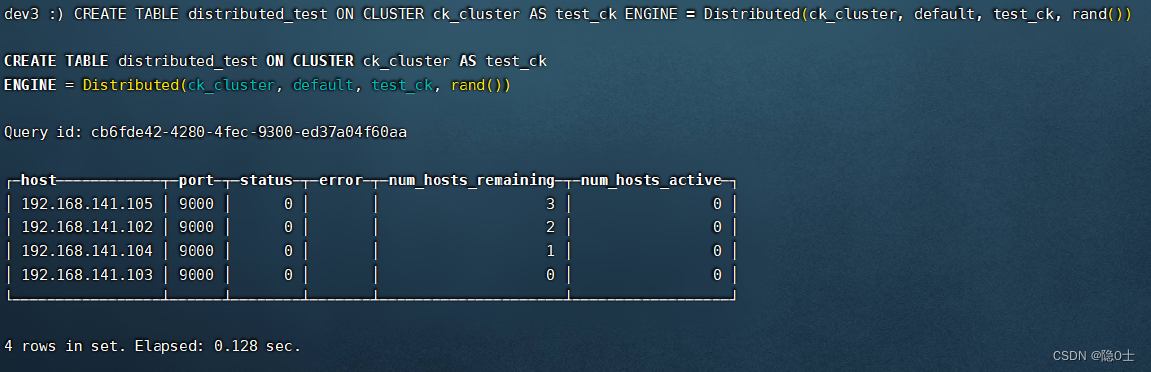
在任意节点执行以下语句创建分布式表:
CREATE TABLE distributed_test ON CLUSTER ck_cluster AS test_ck ENGINE = Distributed(ck_cluster, default, test_ck, rand())
Distributed的参数说明如下:
**ck_cluster:**集群名称
**default:**数据库名
**test_ck:**表名
**rand():**分布式表采用的分配算法,除了这个还有sipHash64(字段名)
插入数据
insert into distributed_test values ('2021-07-01 11:00:00', 1,11);
insert into distributed_test values ('2021-07-01 12:00:00', 2,22);
insert into distributed_test values ('2021-07-01 13:00:00', 3,33);
insert into distributed_test values ('2021-07-01 14:00:00', 4,44);
insert into distributed_test values ('2021-07-01 15:00:00', 5,55);
insert into distributed_test values ('2021-07-01 16:00:00', 6,66);
验证结果
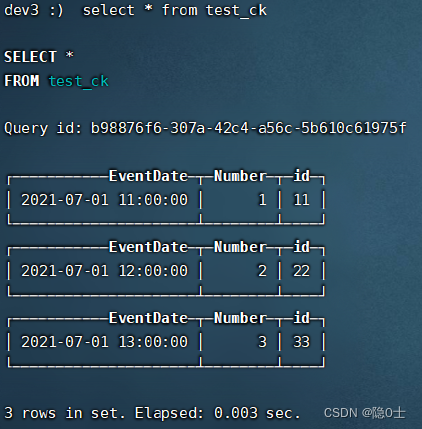
在三个分片的任一节点使用select * from distributed_test语句都能查出所有数据则表示成功。
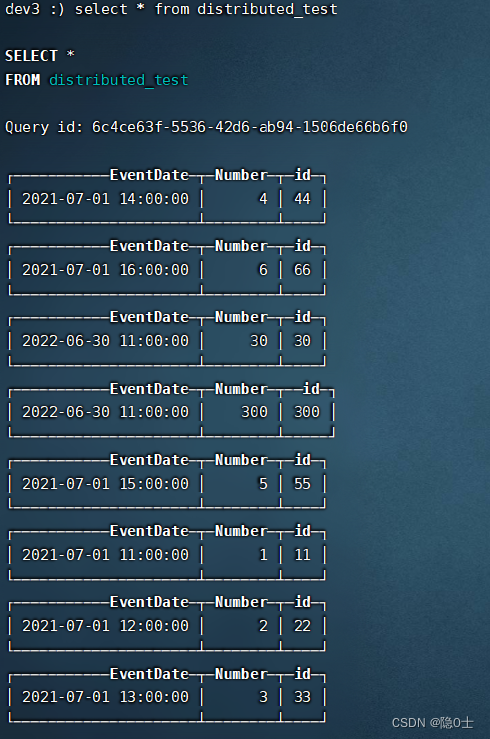
在三个分片的各节点使用select * from test_ck都能查出不同的数据
102
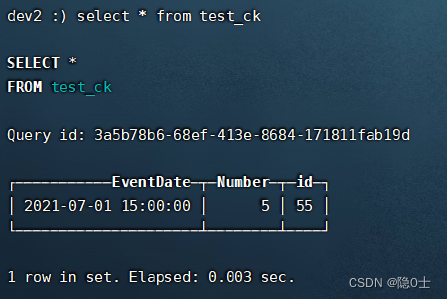
103
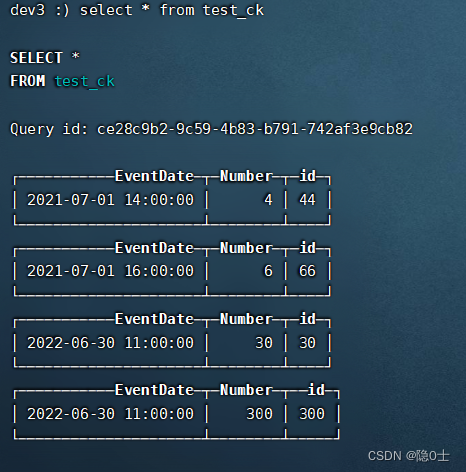
105
















 1951
1951











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









