







 这篇博客是对论文《Deep learning》的概述,作者包括Yann LeCun, Yoshua Bengio & Geoffrey Hinton。博客重点介绍了深度学习的基础概念,包括深度学习、监督学习、反向传播和卷积神经网络(CNN)。深度学习在图像识别、语音转文字等领域展现出优越性,克服传统机器学习在数据处理和表示能力上的局限。监督学习涉及带标签的训练数据,通过损失函数优化模型参数。反向传播用于多层神经网络的参数更新,通过链式法则计算梯度。卷积神经网络讲解了卷积层、池化层和全连接层的工作原理,以及CNN的局部连接、参数共享、池化等特性。"
127928546,9133624,Qt模型视图编程指南,"['Qt开发', '模型视图', '数据模型']
这篇博客是对论文《Deep learning》的概述,作者包括Yann LeCun, Yoshua Bengio & Geoffrey Hinton。博客重点介绍了深度学习的基础概念,包括深度学习、监督学习、反向传播和卷积神经网络(CNN)。深度学习在图像识别、语音转文字等领域展现出优越性,克服传统机器学习在数据处理和表示能力上的局限。监督学习涉及带标签的训练数据,通过损失函数优化模型参数。反向传播用于多层神经网络的参数更新,通过链式法则计算梯度。卷积神经网络讲解了卷积层、池化层和全连接层的工作原理,以及CNN的局部连接、参数共享、池化等特性。"
127928546,9133624,Qt模型视图编程指南,"['Qt开发', '模型视图', '数据模型']
这篇文章从期末前写到期末后,因为内容实在太多了...这篇论文包含了深度学习中比较常见的几个概念,但因为我主要方向是图像领域,因此只对前半部分进行了学习。最近同时在看李宏毅老师的课程,没有专门记笔记,但是把一些内容融合在了下面概念的理解中。
论文阅读:Deep learning—Yann LeCun, Yoshua Bengio & Geoffrey Hinton
这是一篇概述性论文,作为深度学习论文学习的入门篇,作者是非常有名的几位老师。借这样一篇文章来学习几个基本概念:深度学习,监督学习,反向传播和卷积神经网络等。
深度学习(Deep learning)
在一些机器学习的应用领域中,比如确认图片中的物体,将语音转化为文本,根据用户兴趣为其匹配产品等,深度学习的使用越来越多。因为在这些领域中,传统的机器学习方法面临一些问题:
- 传统的机器学习方法处理原始形式数据的能力有限 ,它们需要人为地将数据转化为分类器可以处理的形式,这其中包括对特征进行筛选等特征工程。由于应用领域的不同,特征工程会需要该领域的专业知识对特征进行处理,有一定的门槛;尤其是对于大量数据,手动特征工程的效率和效果都不理想;
- 传统的机器学习方法的表示能力(representation ability)有限。相比之下,深度学习是将多个具有表示(representation)能力的模块(module)叠加,可以得到不同水平的representation,逐步地将原始数据表示成更抽象,复杂的形式。
- 在某些领域,需要对数据的一部分特性具有强选择性,保留了强分辨能力;另一方面模型需要对数据的一部分具有鲁棒性,即不受该部分数据干扰,比如背景,光照等等。这种强建模能力需要通过深度学习来实现。(也就是深度学习会具有平移不变等特性)
监督学习(Supervised learning)
监督学习是最常见的机器学习模式。监督学习中必须要有标记好的训练数据,也就是标签(label)。训练前,模型并不知道正确的建模方向(参数未知,需要随机初始化)。在训练过程中,模型被给予数据和正确的结果,模型的建模能力可以将模型根据数据输出的结果与正确的标记结果进行对比得知。为了具体化这个建模能力,可以求两个结果间的差值,差值小,则表示建模是更向正确方向靠近的。为了提高模型的建模能力,需要不断调整参数以使差值最小。
损失函数(loss function)/目标函数(object function)
定义一个包含上述差值的函数,那么提高建模能力这个目标就可以转化为最小化这个函数,因此可以称为目标函数(对于一批数据,目标函数应该是这批数据的损失和或均值);这个函数表示的是建模结果和正确结果间的差值,也就是误差/损失,因此又可以成为损失函数。
参数
参数指的是模型中一些需要设定的系数,这些系数决定了模型的建模方向。这些参数会出现在损失函数中,因此上述的最小化损失函数的具体措施就是调整这些参数,使损失函数取到局部最小值。
梯度下降
找到参数使得包含参数的函数尽快地取得最小值,就会涉及到求梯度,当然该梯度是损失函数对于参数的梯度。梯度表示了该损失函数在参数微微变化时的变化剧烈程度,对其取负值,就是最快的下降方向。那么参数就要沿该方向以一定的步长变化,使得损失函数迅速减小。不断地更新参数, 直到损失函数不会再下降。
随机梯度下降:每次从训练数据中随机抽取一部分数据作为一个小集合来训练模型,也就是利用这些数据的模型输出结果和它们的正确结果构建损失函数,然后通过梯度下降的方法更新模型的参数,然后再次从训练数据中获取另一个小集合接着训练,直到损失函数取到最小。由于每次用来训练模型的都只是整体训练数据中的一小部分,损失函数和参数都是具有一定的噪声/偏差。但这种方法非常有效而且迅速。
反向传播(Back propagation)
深度学习是一层层模型叠加的,其实就是一层层神经网络叠加,所以参数其实是分布在不同层的。由于层与层之间是递进的关系(上一层的输出作为下一层的输入,因此有时序关系),不同层的参数是不可能同时更新的,而是从整个深度学习的模型(事实上就是神经网络)的输出反向向输入一层层更新。每一层的更新都是上文提到的损失函数求梯度然后更新参数的过程。不过对于中间的层,如何得到损失函数对这一层参数的梯度呢?因为这一层的输出是一个中间值,在整个模型中是不会输出的,但这个中间值会通过下一层的参数继续影响后续的网络层,直到整个网络的输出。根据链式求导的原理,其实就是复合函数求导,我们可以根据最外层的结果来一层层向内求导得到输出对里层参数的导数。这个一层层求导的过程就利用了反向传播,把每一层参数的变化方向传递给该层,然后该层参数进行更新。所有层的参数完成一次更新后,整个网络才完成一次更新。
反向传播的理论基础是链式求导,根据具体的神经网络模型我们来推导反向传播的基本形式。
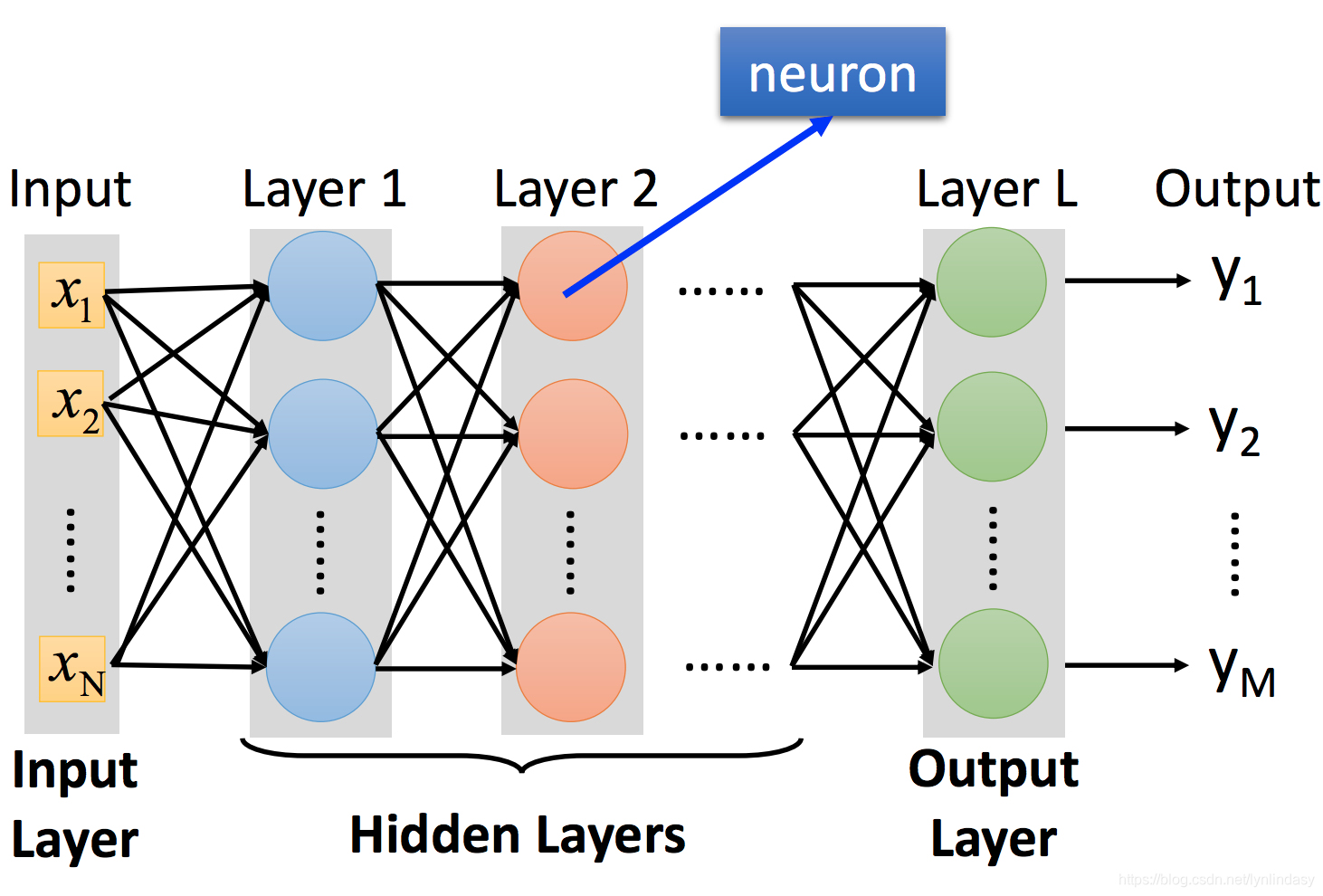
上图为一个简单的神经网络,输入用向量x表示,输出用向量y表示,中间是一层层堆叠的隐藏层。输入x会经过一个线性组合也就是图中的箭头(可以表示为矩阵相乘)得到Wx,在加上偏置向量b得到图中Layer 1的输入,这里所有变量和参数的上标1均表示神经网络中的第一层隐藏层(输入层其实可以视为第零层也就是
),第一层中的神经元也就是图中蓝色的圆圈会对这个输入进行非线性操作,也称作激活(activation),我们用式子
表示,
就表示activation后的结果也就是这层网络的输出,后面的每一层网络都进行上述的操作,直到输出层也就是第L层
就是输出向量y。这就是神经网络的前向计算过程(forwad pass)。
整个网络的流程可以表示为。
网络的loss function我们定义为,这只是其中一种形式,也可以定义为交叉熵形式等,其中
为数据的标签(label)。为了简化推导过程
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 627
627

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









