







为什么选择序列模型
序列数据的例子:语音识别,音乐生成(输入是1,2,3等音符或者空),情感分类(输入一段文字,输出电影评分),视频行为识别,人名识别(给出一段文字,识别出里面的人名)

注:输入输出的长度可以不等。
数学符号
- 做一张词表,包含很多的词
- 用one-hot方法表示出句子中的每一个词,

循环神经网络
特点之一:三类参数在每个时间步共享,相同。即Wax,Waa,Wya。

RNN----前向传播的两个公式的由来

RNN的时间反向传播损失是每个时间步的损失和。
不同类型的循环神经网络
(一对一,一对多,多对多)


RNN模型的例子
预测句子中下一个次词是什么。
每一步的输出y指的是它是某个词的概率(基数是词典)

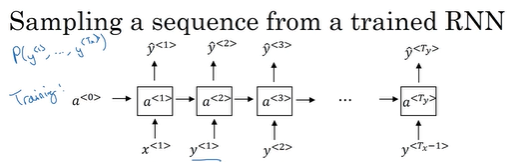
从训练好的RNN模型中生成一个随机选择的句子(新序列采样)
步骤:
- 刚开始输入0,生成词典中每个词的概率,选择概率大的那个为输出值。
- 将第一个输出作为第二个时间步的输入,去预测第二个输出值。
- 后面同上。
标准的神经网络建模的弊端
- 不共享从文本不同位置上学到的特征。包括:
以前输入的是类似于一个表格里,列名是属性,行是一个个样本。如果神经网络学习了在位置1出现的Harry可能是人名,一旦它出现在其他位置,可能就识别不出来了。 在A位置学习到识别人名的能力,但是B位置学不到,当人名出现在B位置时,B就识别不出来。 - 训练参数量巨大。输入网络的特征往往是one-hot或者embedding向量,维度大;当输入网络的序列长度很长时,输入向量巨大。
- 没有办法体现出序列的前因后果。
RNN的缺点
当序列太长时,容易导致梯度消失。参数更新只能扑捉到局部依赖关系,没法捕捉到序列之间的长期关联或者依赖关系。

LSTM
- RNN是想把所有的信息都记住,不管是有用的还是没用的信息。
- LSTM:设计一个记忆细胞,具备选择性记忆功能,过滤掉噪声信息,减轻记忆负担。
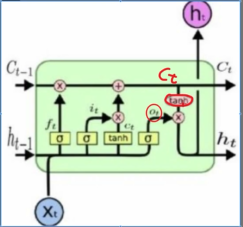
- 前向传播(举例)
Ct-1:前一阶段学到的高数知识;
Xt:当前复习线代;
ht-1:前一阶段的状态值;
第一个遗忘门 Ct-1×ft,表示过滤掉高数中对线代没有用处的知识;
第二个更新门gt×it,表示过滤掉线代中对考试无关的知识,比如背景知识;
第三个输出门Ot×tanh(Ct),表示学到了很多知识,但是在考试中可能只用到了5成;
Ht:表示这一阶段的状态,考试结果
Ct:表示这一阶段总的有效知识。


RNN中的梯度爆炸和梯度消失问题

LSTM如何缓解梯度消失
特点:参数特别多----》容易过拟合
数据集少时倾向于使用GRU,但是数据集大的话,用LSTM性能更好。

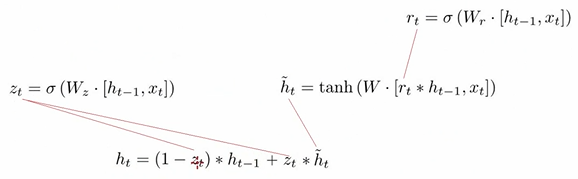
GRU——门控循环单元
LSTM有三个门,GRU只有两个门,分别是
重置门:有助于捕捉短期依赖关系;
更新门:有助于捕捉时间序列中长期的依赖关系。


举例子:




双向RNN(BRNN)
什么情况下需要双向RNN

还有那种带有LSTM的双向RNN。
缺点是:需要读入整个句子,要能够获取整个句子。
深层RNN
















 4562
4562











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









