







1. Ajax 介绍
Ajax 即“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),是指一种创建交互式、快速动态网页应用的网页开发技术,无需重新加载整个网页的情况下,能够更新部分网页的技术。
通过在后台与服务器进行少量数据交换,Ajax 可以使网页实现异步更新。这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新。(百度百科),网易新闻的页面就属于这一类,如下,只要一直往下拉,新闻就会一直出现

2. 爬取逻辑
【找到新闻资讯所在位置】 -> 【确定资源的url】 -> 【获取json数据】 -> 【按需求获取数据并存入数据库或者保存本地】
针对爬取逻辑封装两个函数:
1) 获取资源url的函数
def get_url(n):
n:爬取数据的页数
return返回值: json数据对应url的列表
2) 获取需求数据并存入数据库
def get_data(url,dic_h,table):
url:json数据对应的url
dic_h:请求头
table:数据库表格
return返回值:数据爬取量计数
3. 资源url获取
1) 解析json数据文件
首先解析一下网易新闻的页面,在某一新闻页面(比如这里选择的就是’要闻’界面),右键检查,进行测试,和之前获取headers和cookies的操作步骤类似,寻找json数据接口
操作如下:【右键进入检查界面】-> 【选中菜单栏Network】-> 【点击刷新按钮】-> 【查找右下角中的文件】-> 【找到包含json数据的文件】-> 【下拉左侧原界面】-> 【按规律找到全部包含json数据的文件】
图解如下:(因为找到包含json数据的文件是cm_开头的,所以为了过滤掉其他的信息文件,这里直接就只查看所有包含json数据的文件,可以看出没刷新一次页面就会有一个callback文件出现在Name栏下面)
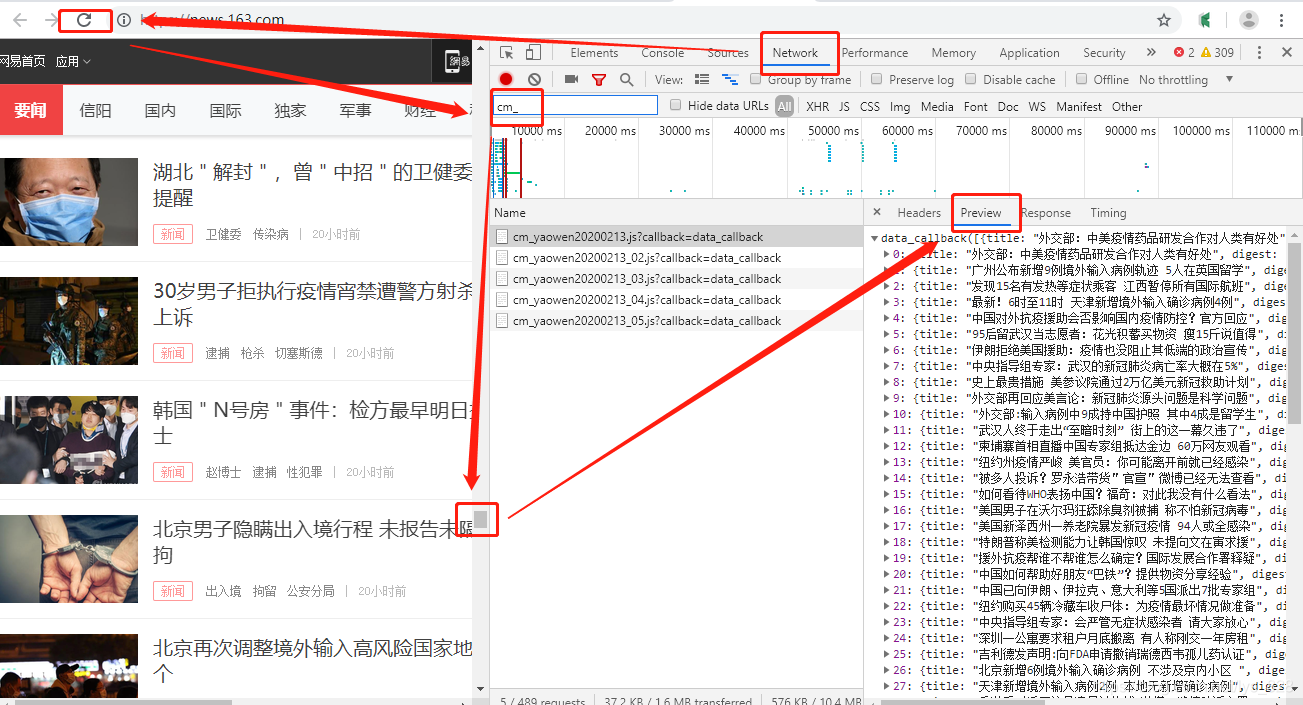
2) 确定json文件对应的url
在上面的步骤的基础上,点击Preview左侧的Headers,其中Request URL后面的内容就是json数据对应的url了,对应如下
u1 = https://temp.163.com/special/00804KVA/cm_yaowen20200213.js?callback=data_callback
u2 = https://temp.163.com/special/00804KVA/cm_yaowen20200213_02.js?callback=data_callback
u3 = https://temp.163.com/special/00804KVA/cm_yaowen20200213_03.js?callback=data_callback
u4 = https://temp.163.com/special/00804KVA/cm_yaowen20200213_04.js?callback=data_callback
u5 = https://temp.163.com/special/00804KVA/cm_yaowen20200213_05.js?callback=data_callback
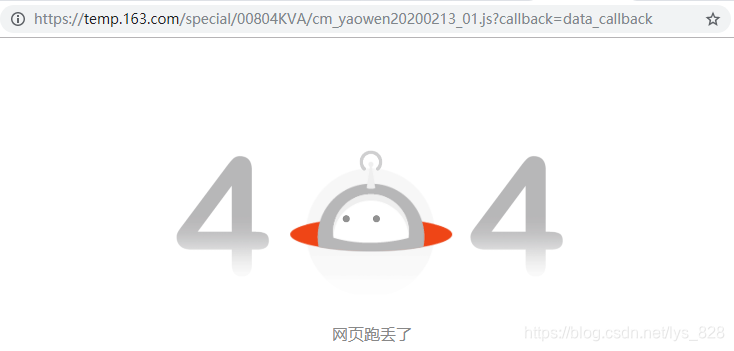
这里列举了前五页的url,是不是就像最初爬取网页那样也类似的规律呢,也就是第一页的url是可以写成xxx20200213_01.js?xxx类似的格式呢?可以尝试一下,在浏览器界面输入下面这个网址,看看是否真的有规律可循,如下
https://temp.163.com/special/00804KVA/cm_yaowen20200213_01.js?callback=data_callback
–> 输出结果为:(按照相同的方式,发现其他的网页都可以按照原网址进行打开,也就是说这里的首页的url是不符合之前爬虫的网页的规律的,因此需要单独进行判断)
3) 封装第一个函数,返回url列表
def get_url(n):
urllst = []
url_fixed = 'https://temp.163.com/special/00804KVA/cm_yaowen20200213.js?callback=data_callback'
urllst.append(url_fixed)
urllst.extend([f'https://temp.163.com/special/00804KVA/cm_yaowen20200213_0{i}.js?callback=data_callback' for i in range(2,n+1)])
# for i in range(2,n+1):
# urllst.append(f'https://temp.163.com/special/00804KVA/cm_yaowen20200213_0{i}.js?callback=data_callback')
return urllst
get_url(5)
–> 输出结果为:(对比可以发现这五条数据和在网页上找的url是一致的,在浏览器界面打开后均有数据返回)
['https://temp.163.com/special/00804KVA/cm_yaowen20200213.js?callback=data_callback',
'https://temp.163.com/special/00804KVA/cm_yaowen20200213_02.js?callback=data_callback',
'https://temp.163.com/special/00804KVA/cm_yaowen20200213_03.js?callback=data_callback',
'https://temp.163.com/special/00804KVA/cm_yaowen20200213_04.js?callback=data_callback',
'https://temp.163.com/special/00804KVA/cm_yaowen20200213_05.js?callback=data_callback']
5. 需求数据的爬取并将数据存入数据库
1) 先配置数据库参数
这里使用mongo数据库作为数据存储,比较简单便捷,总共只需要四行代码就配置好数据库,关于mongo数据库的安装可以查看mongo快速入门
#导入数据库模块
import pymongo
# 链接上服务器
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
#创建一个数据库
db = myclient['腾讯新闻']
#在该数据库下创建一个'表格'保存数据
table = db['data1']
2) 数据爬取试错
在进行大量数据爬取之前,先测试一下能否进行某一页的信息数据的获取,如果没有问题了再进行下一步操作,这样就可以避免出现问题后再回过头来查找错误,节省时间。
在将数据清洗为json可转化的数据类型过程中,要查找位置索引的问题,在之前的python爬取酷狗音乐中已经介绍过,下面直接给出代码
def get_data(url,dic_h,table):
count = 0
ri = requests.get(url,headers = dic_h)
start = ri.text.index('[')
end = ri.text.index('])') + 1
datas = json.loads(ri.text[start:end])
return datas
urllst = get_url(5)
dic_h = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'}
get_data(urllst[0],dic_h,table)
–> 输出结果为:(这里以第一个url进行试错,查看是否可以成功的返回请求的数据,只截取其中的一条信息)
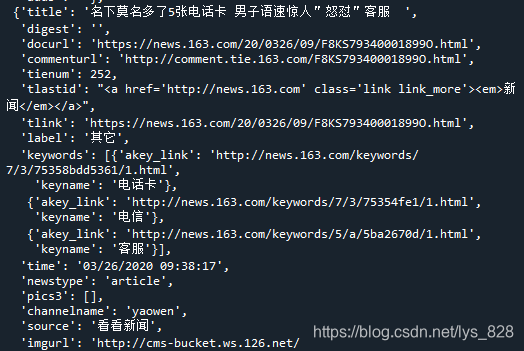
3) 获取需求字段信息
在试错无误后就可以或许需求的字段信息了,其中关于keywords字段信息的获取这里可以讲一下,通过上面的输出图片可以发现,所有的信息都是以键值对的形式存储,其他的字段信息都是为字符串,而keywords字段信息是列表中嵌套着字典,因此要提取出里面的keyname信息,还是需要点技巧的,代码如下
for data in datas:
dic = {}
dic['title'] = data['title']
dic['docurl'] = data['docurl']
dic['commenturl'] = data['commenturl']
dic['source'] = data['source']
dic['time'] = data['time'].split(' ')[0]
dic['keywords'] = ','.join(x['keyname'] for x in data['keywords'])
count += 1
#table.insert_one(dic)
print(dic)
–> 输出结果为:(时间字段进行空格分隔,只选择年月日即可,其他的字段直接可以选取,keywords字段信息需要先遍历表格然后取出里面的keyname信息,再将信息以逗号的形式组成字符串,这样所有需要的字段信息都获取完毕了,也可以添加一些其他的字段爬取信息,未防止审核不通过,下面只截取部分结果)
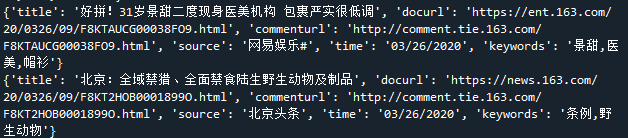
4) 获取全部数据并保存在数据库
数据插入数据库的操作就是一条指令table.insert_one(dic),打开上面的注释即可,最后进行url的遍历循环即可,为了防止出错,可以加上try-except进行异常处理
error_lst = []
count = 0
for u in urllst:
try:
count += get_data(urllst[0],dic_h,table)
print(f'成功爬取并存储{count}条数据')
except :
print('未能爬取数据网址为:',u)
error_lst.append(u)
6. 全部代码及运行结果
如果要将结果数据
import pymongo
#import pandas as pd
import json,requests
def get_url(n):
urllst = []
url_fixed = 'https://temp.163.com/special/00804KVA/cm_yaowen20200213.js?callback=data_callback'
urllst.append(url_fixed)
urllst.extend([f'https://temp.163.com/special/00804KVA/cm_yaowen20200213_0{i}.js?callback=data_callback' for i in range(2,n+1)])
# for i in range(2,n+1):
# urllst.append(f'https://temp.163.com/special/00804KVA/cm_yaowen20200213_0{i}.js?callback=data_callback')
return urllst
get_url(5)
def get_data(url,dic_h,table):
n = 0
ri = requests.get(url,headers = dic_h)
start = ri.text.index('[')
end = ri.text.index('])') + 1
datas = json.loads(ri.text[start:end])
#data_lst = []
for data in datas:
dic = {}
dic['title'] = data['title']
dic['docurl'] = data['docurl']
dic['commenturl'] = data['commenturl']
dic['source'] = data['source']
dic['time'] = data['time'].split(' ')[0]
dic['keywords'] = ','.join(x['keyname'] for x in data['keywords'])
table.insert_one(dic)
n += 1
#print(dic)
#data_lst.append(dic)
return n
if __name__ == '__main__':
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
db = myclient['网易新闻']
table = db['data1']
urllst = get_url(5)
dic_h = {'user-agent': 'Mozilla/5.0'}
error_lst = []
count = 0
for u in urllst:
try:
count += get_data(urllst[0],dic_h,table)
print(f'成功爬取并存储{count}条数据')
except :
print('未能爬取数据网址为:',u)
error_lst.append(u)
–> 输出结果为:
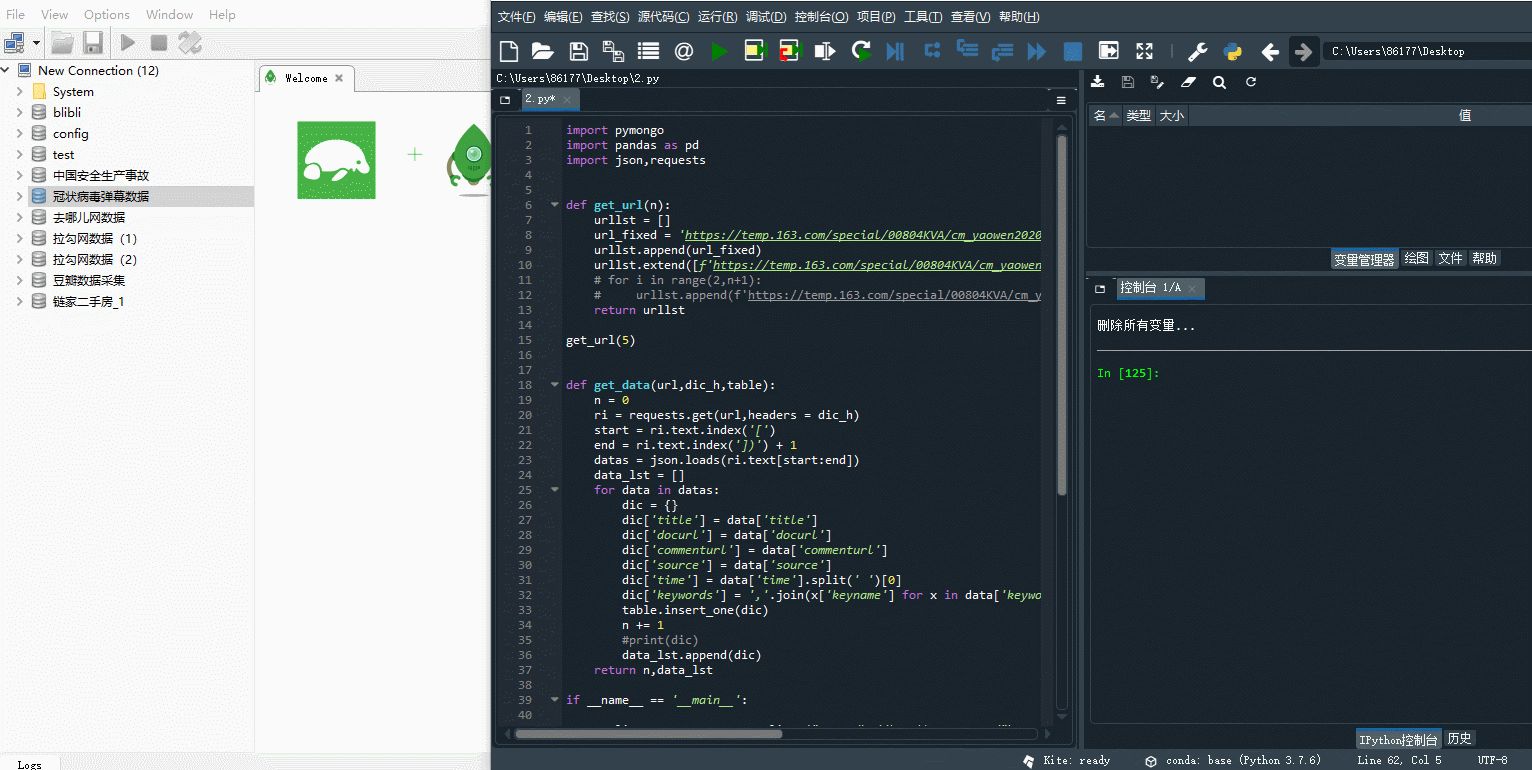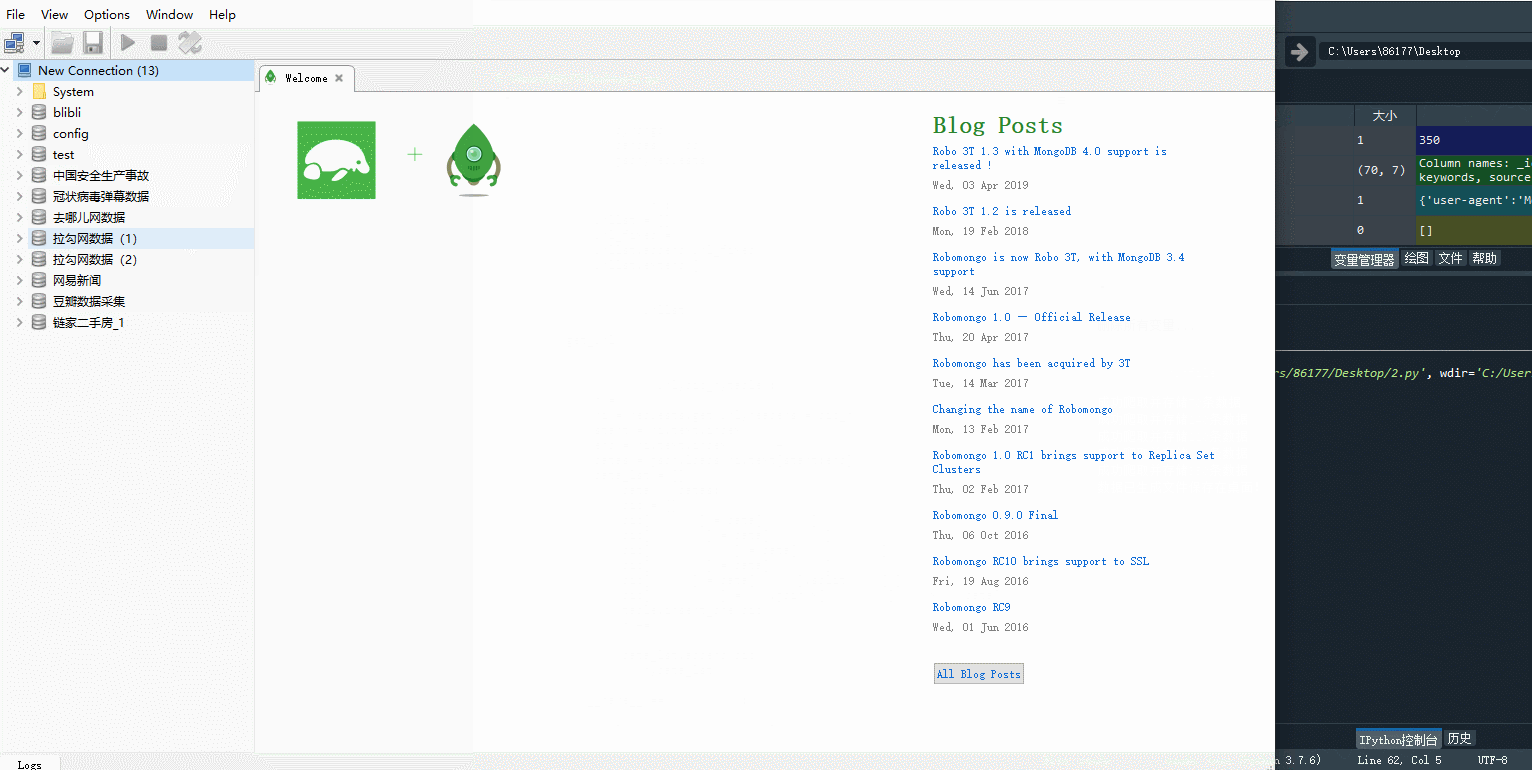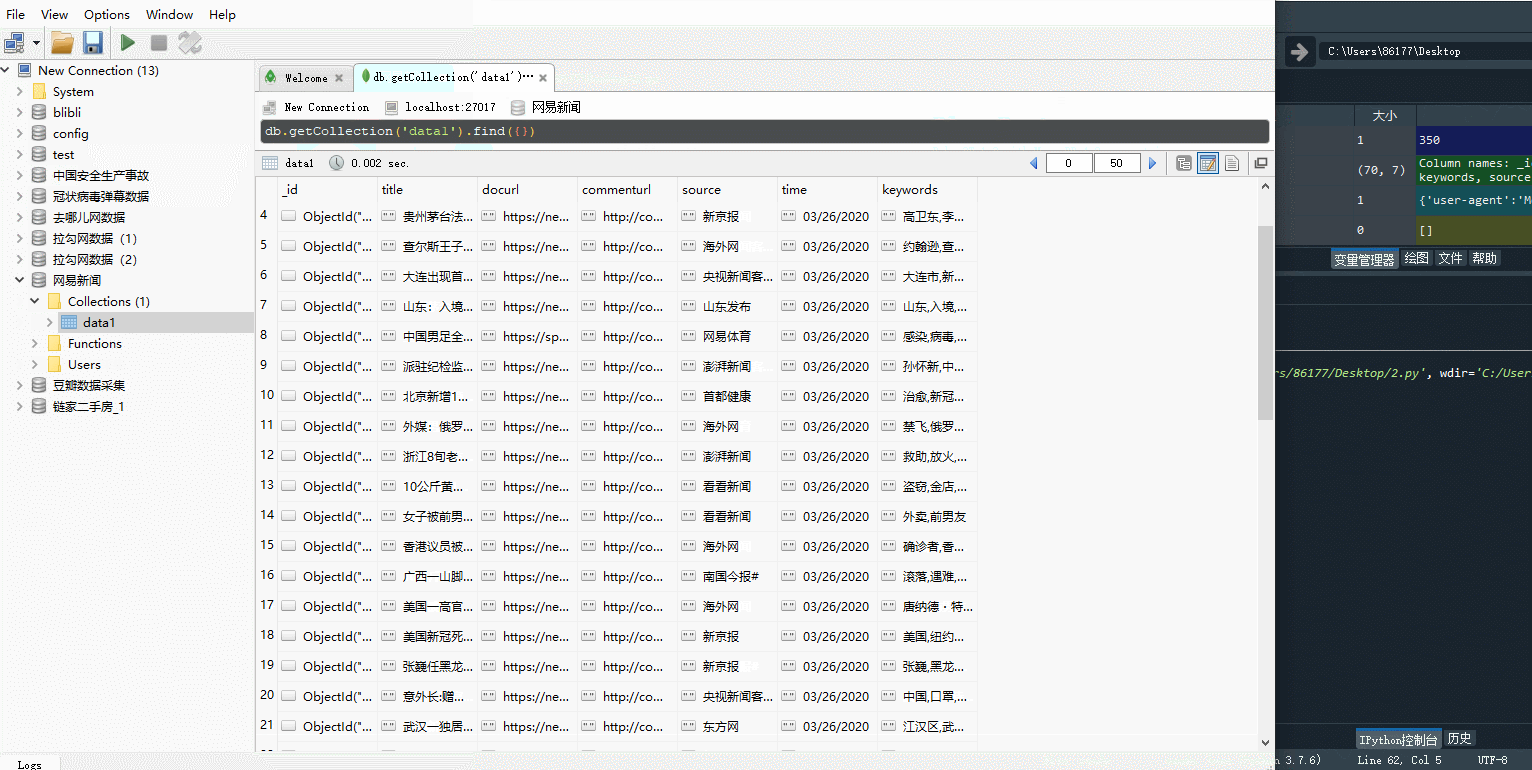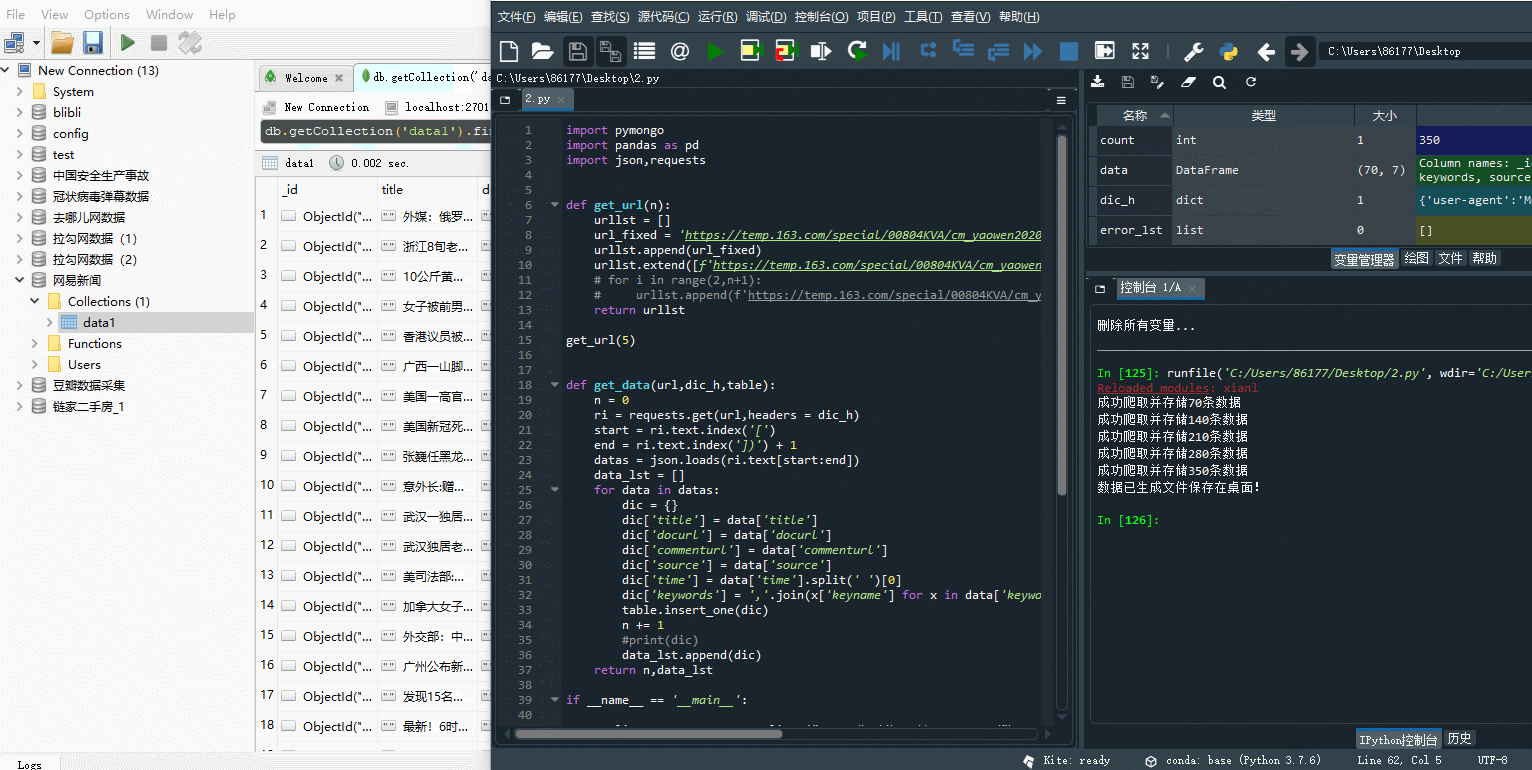
生成桌面的文件如下:(截取部分)
















 1434
1434











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











