







利用决策树进行年龄与音乐类型喜好分类预测
手动反爬虫,禁止转载: 原博地址 https://blog.csdn.net/lys_828/article/details/122041951(CSDN博主:Be_melting)
知识梳理不易,请尊重劳动成果,文章仅发布在CSDN网站上,在其他网站看到该博文均属于未经作者授权的恶意爬取信息
1 利用决策树进行年龄与音乐类型喜好分类预测
1.1 导入模块与加载数据
import pandas as pd
music_df1= pd.read_csv('../data/music.csv')
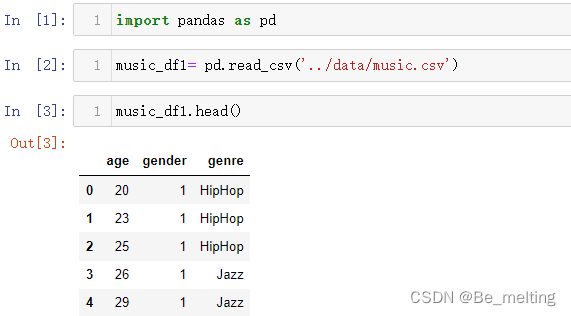
music_df1.head()
输出结果如下。
数据读入之后,可以简单看一些各个字段的情况,使用info()方法进行输出。
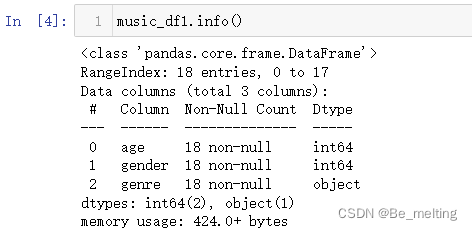
music_df1.info()
输出结果如下。本案例属于对于决策树模型使用的基本流程进行认知,数据已经被处理干净,而且字段相对较少。
1.2 划分数据
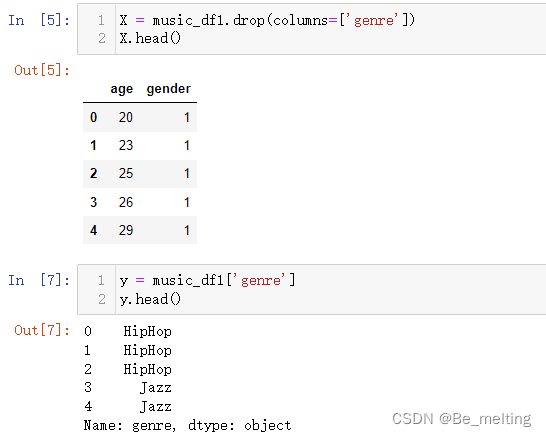
划分特征数据和标签数据。
X = music_df1.drop(columns=['genre'])
X.head()
y = music_df1['genre']
y.head()
输出结果如下。
1.3 模型创建与训练
导入创建模型的模块,此案例是进行决策树分类,注意不是回归,然后再进行模型初始化。这里没有进行训练模型和测试模型的划分,而是直接将全部的数据进行应用到模型中。
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
model.fit(X,y)
输出结果如下。

1.4 模型应用
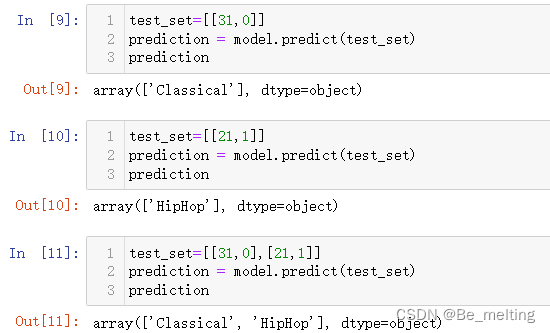
模型训练完毕后,可以直接用于预测,也可以将模型保存在本地,遇到问题时候再调用。首先进行直接预测,比如任意输入两个字段的数据,看看模型最终预测的结果如何。
test_set=[[31,0]]
prediction = model.predict(test_set)
prediction
test_set=[[21,1]]
prediction = model.predict(test_set)
prediction
test_set=[[31,0],[21,1]]
prediction = model.predict(test_set)
prediction
输出结果如下。注意predict()方法中传入的是二维列表,其中可以放置单一的两个字段的数据,也可以输出多个两字段的数据,即完成单数据的分类预测和多数据的分类预测。
介绍完直接进行模型的分类预测使用,有时候模型训练一次消耗大量的时间,因此就需要提前把模型调整到最优状态下,如果需要使用时再直接调用本地训练好的模型即可。需要使用joblib模块,加载后将模型保存本地,需要使用时候再调用,代码如下。
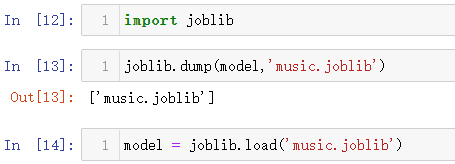
import joblib
joblib.dump(model,'music.joblib')
model = joblib.load('music.joblib')
输出结果如下。dump()是将模型保存到本地,load()是将本地的模型加载到当前运行的环境中。
还是以刚刚进行预测的数据进行测试,看看结果是否一致。
test_set=[[31,0]]
prediction = model.predict(test_set)
prediction
test_set=[[21,1]]
prediction = model.predict(test_set)
prediction
输出结果如下,对比核实无误。

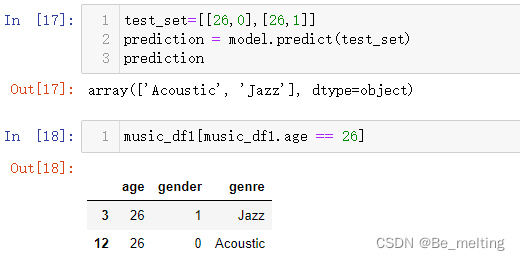
也可以取其中26岁,男女信息各一个进行分类预测,代码及核验代码如下。
test_set=[[26,0],[26,1]]
prediction = model.predict(test_set)
prediction
music_df1[music_df1.age == 26]
输出结果如下,预测结果和实际真实结果一模一样。
1.5 模型可视化
决策树进行分类预测的一个优势就是在于流程和结果都可以可视化展示,通过树图的方式呈现。
from sklearn import tree
tree.export_graphviz (model,out_file='music-dt.dot',feature_names=['age','gender']
,class_names=sorted(y.unique()),label='all',rounded=True,filled=True)
输出结果如下。其中第一个参数是训练好的模型变量,第二个是输出的可视化文件,第三个就是指定特征字段,第四个是标签字段,第五个是label显示设置,最后两个可以调用说明文档进行查看,此外还有很多的参数可以进行设置。

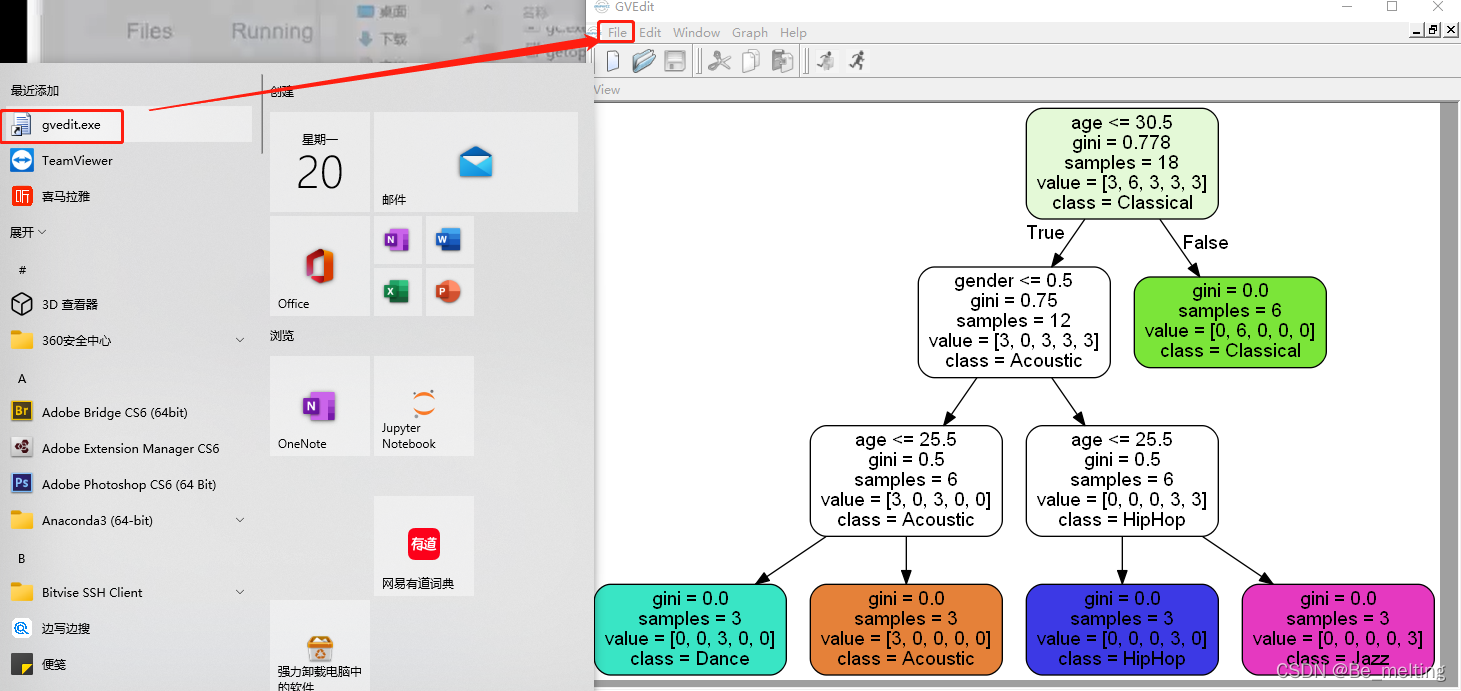
进行可视化,还需要有一个可视化专门软件,课程中提供的有graphviz-2.38.msi安装包,直接进行双击安装后即可。

安装完毕后在开始菜单就会添加这个程序,打开后选择File菜单项,再把生成的music.dot文件添加进来就可以进行可视化展现了。
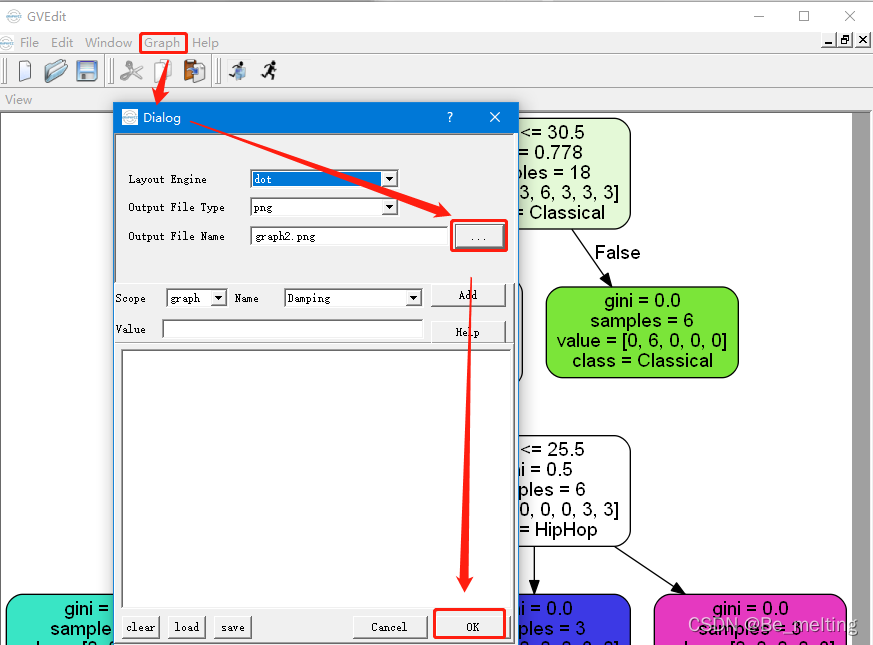
如果要把可视化的结果进行保存到本地也很简单,点击Graph菜单栏,然后选择Setting后,跳出的窗口中指定保存的文件的位置和名称,指定完毕后点击下方的OK按钮即可。特别注意,保存到本地时候文件路径中不能有中文名称,否则无法识别路径,程序运行报错。
比如将图片保存到桌面,然后可以进一步加载到Jupyter notebook中,代码如下。
from IPython.display import Image
Image(r"C:\Users\86177\Desktop\1.png")
输出结果如下。
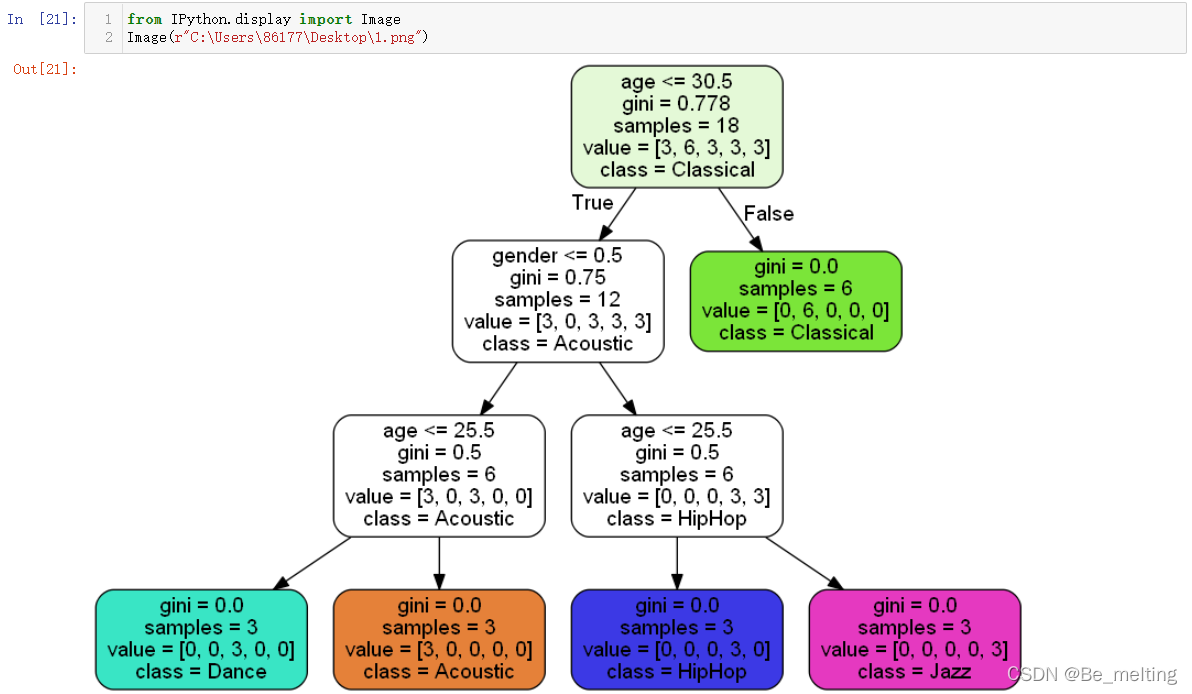
1.6 数据核验
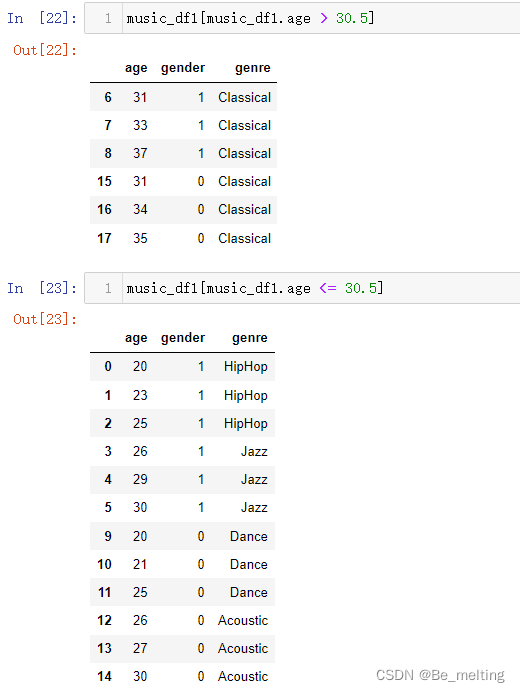
对于生成的可视化图形结果还可以进一步核实,比如这里的根节点选择的是age小于等于30.5,可以按照这个标准对原数据进行筛选,代码如下。
music_df1[music_df1.age > 30.5]
music_df1[music_df1.age <= 30.5]
输出结果如下,核验无误。结果中确实是有6个Classical类别,剩下的12条数据中每种类别均为3个,输出的树图可以代表决策树最终的分类预测结果。















 7962
7962











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











