







本文主要通过调取sklearn库中的tree模块来构建在鲍鱼数据集上的决策树,并对测试集鲍鱼的年龄进行预测,本文仅供参考。
目录
前言
本文主要通过调取sklearn库中的tree模块来构建在鲍鱼数据集上的决策树,并对测试集鲍鱼的年龄进行预测。
以下是本篇文章正文内容
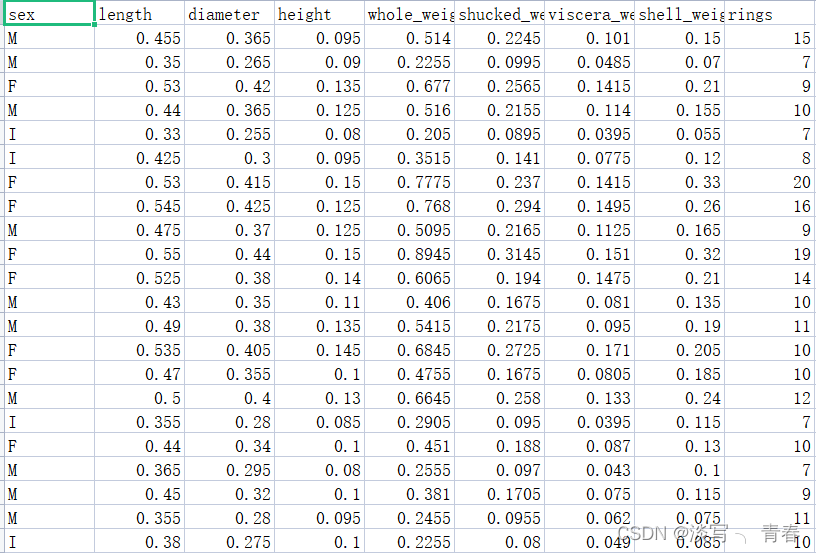
一、数据集
训练集:
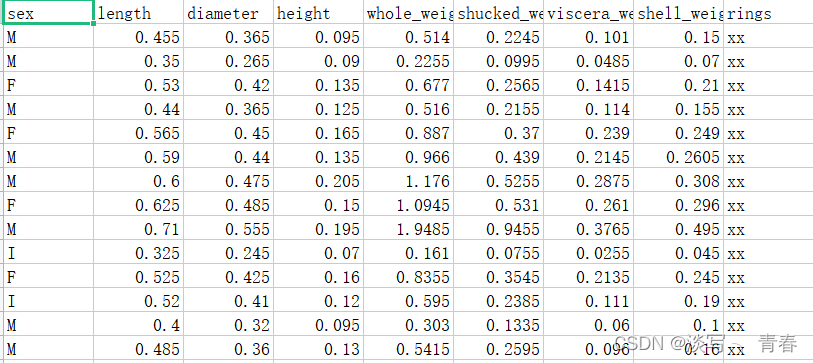
测试集:
二、步骤
1.引入库
代码如下(当然有些库没有用到):
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import precision_score
from scipy.stats import multivariate_normal
from mpl_toolkits.mplot3d import Axes3D
import copy
2.读入数据
代码如下:
# 读取数据
train_datas=pd.read_csv(path1,header=None)
test_datas=pd.read_csv(path2,header=None)
注:其中的path1和path2换成自己的文件路径
3.数据预处理
3.1将数据集中的性别一列的属性值M、F、I换成0、1、2
train_datas=train_datas.replace(['M','F','I'],[0,1,2])
test_datas=test_datas.replace(['M','F','I'],[0,1,2])3.2去除测试集最后一列
test_data=test_datas.drop(columns=[8])3.3去除属性名这一行,并将训练集和数据集转换为列表形式
#转换成列表
train_data=np.array(train_datas[1:][:]).tolist()
testData=np.array(test_data[1:][:]).tolist()3.4标签处理
label=train_datas[:1][:]
labels=np.array(label).tolist()[0][:-1]3.5预处理数据集
x_train=np.array(train_data)[:,:8].tolist()
y_train=np.array(train_data)[:,8].tolist()
x_test=testData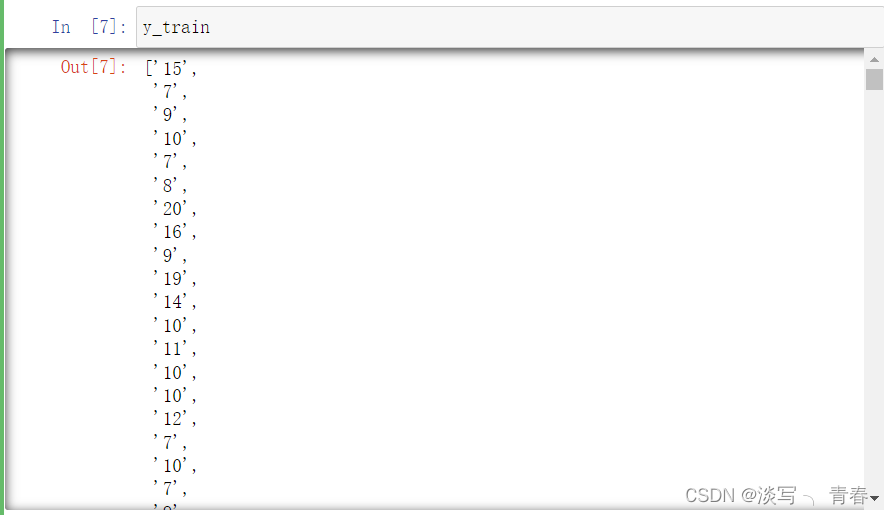
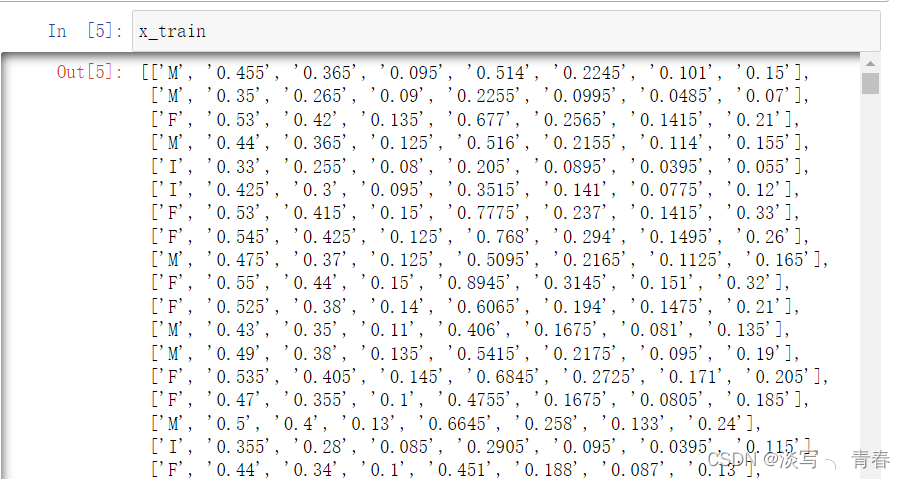
 到这里数据集的预处理就算完成了。
到这里数据集的预处理就算完成了。
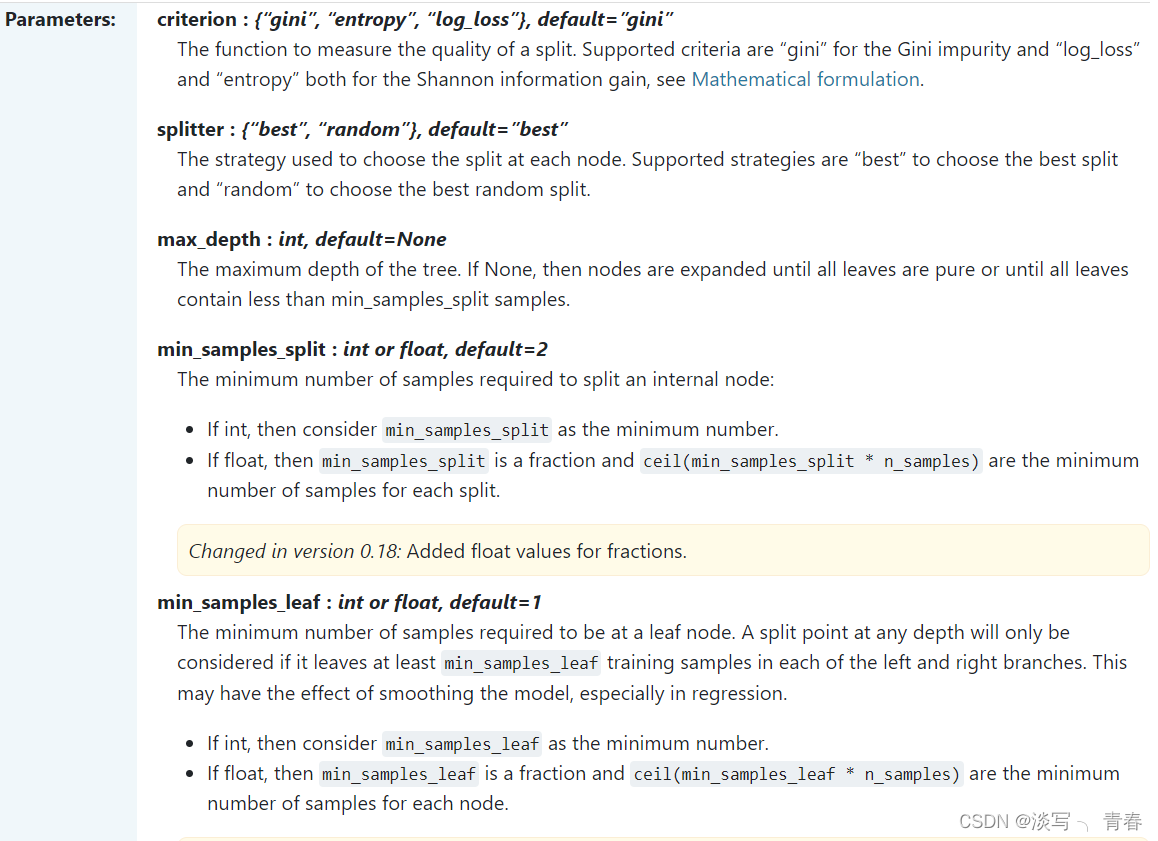
4.构造决策树
注:参数请自行设置
# 调库
from sklearn import tree#导入模块
DF_model=tree.DecisionTreeClassifier(criterion='entropy',random_state=30,splitter='random')#实例化
clf=DF_model.fit(x_train,y_train)#用训练集数据训练模型5.绘制特征图
pd.Series(DF_model.feature_importances_,index=labels).sort_values().plot(kind='barh',title='Importance of Feature ') 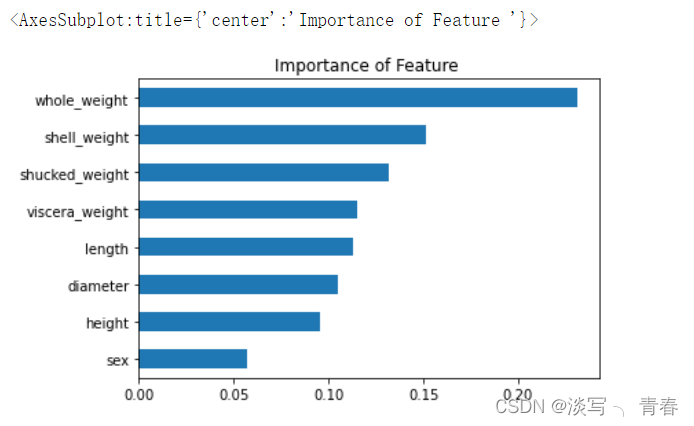
6.绘制决策树
from sklearn.tree import export_graphviz
from IPython.display import Image
import pydotplus
class_names=train_datas
export_graphviz(DF_model,out_file='tree.dot',feature_names=labels,rounded=True,filled=True,
class_names=list(set(y_train)))
graph=pydotplus.graph_from_dot_file('tree.dot')
注:若不熟悉export_graphviz的可以参考下面这篇文章,同时因为运行export_graphviz需要安装一些东西,要不然可能会报错,也可参考这篇文章,里面有解决办法。
https://www.jianshu.com/p/93f20701a634![]() https://www.jianshu.com/p/93f20701a634 调用export_graphviz()出现问题的的可以加上这行代码
https://www.jianshu.com/p/93f20701a634 调用export_graphviz()出现问题的的可以加上这行代码
import os
os.environ["PATH"] += os.pathsep + './windows_10_msbuild_Release_graphviz-3.0.0-win32/Graphviz/bin'
绘图:
Image(graph.create_png()) 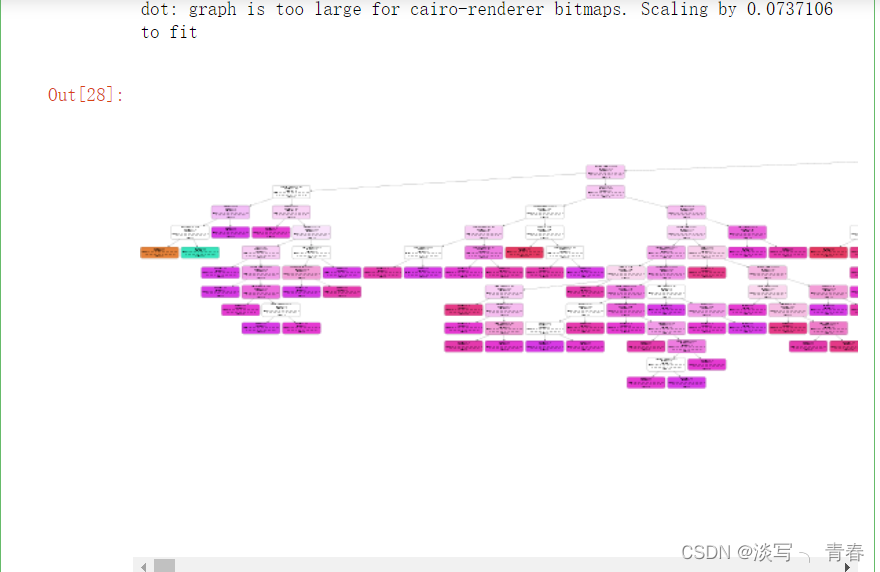
7.预测
pred_y=clf.predict(x_test)
print("ring为:",pred_y) 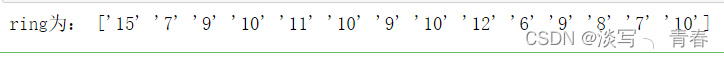
年龄预测:(ring+1.5=age)
#对环的数量加1.5,即为鲍鱼的年龄
pred_year=[float(i)+1.5 for i in pred_y]
print("年龄为:",pred_year) 
总结
以上就是本篇文章的所有内容了,当然本文只是调库实现决策树的绘制,并没用按照ID3算法的每一步去具体实现它,这也是本文的不足吧,当然你也可以自己去按照书上的算法去实现它。
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









