







1. 前言
1. 先看一个最简单的爬虫。
import requests
url = "http://www.cricode.com"
r = requests.get(url)
print(r.text)2. 一个正常的爬虫程序
上面那个最简单的爬虫,是一个不完整的残疾的爬虫。因为爬虫程序通常需要做的事情如下:
- 1)给定的种子 URLs,爬虫程序将所有种子 URL 页面爬取下来
- 2)爬虫程序解析爬取到的 URL 页面中的链接,将这些链接放入待爬取 URL 集合中
- 3)重复 1、2 步,直到达到指定条件才结束爬取
因此,一个完整的爬虫大概是这样子的:
import requests # 用来爬取网页
from bs4 import BeautifulSoup # 用来解析网页
# 我们的种子
seeds = [
"http://www.hao123.com",
"http://www.csdn.net",
"http://www.cricode.com"
]
# 设定终止条件为:爬取到 100000个页面时就停止爬取
end_sum = 0
def do_save_action(text=None):
pass
while end_sum < 10000:
if end_sum < len(seeds):
r = requests.get(seeds[end_sum])
end_sum = end_sum + 1
do_save_action(r.text)
soup = BeautifulSoup(r.content)
urls = soup.find_all('a') # 解析网页
for url in urls:
seeds.append(url)
else:
break3. 现在来找茬。上面那个完整的爬虫,缺点实在是太多。下面一一列举它的N宗罪:
- 1)我们的任务是爬取1万个网页,按上面这个程序,一个人在默默的爬取,假设爬起一个网页3秒钟,那么,爬一万个网页需要3万秒钟。MGD,我们应当考虑开启多个线程(池)去一起爬取,或者用分布式架构去并发的爬取网页。
- 2)种子URL 和 后续解析到的URL 都放在一个列表里,应该设计一个更合理的数据结构来存放这些待爬取的 URL ,比如:队列或者优先队列。( scrapy-redis 是 种子URL 在 redis的 list 里面,后续解析到的URL 在 队列里面 )
- 3)对各个网站的 url,我们一视同仁,事实上,我们应当区别对待。大站好站优先原则应当予以考虑。
- 4)每次发起请求,都是根据 url 发起请求,而这个过程中会牵涉到 DNS 解析,将 url 转换成 ip 地址。一个网站通常由成千上万的 URL,因此,可以考虑将这些网站域名的 IP 地址进行缓存,避免每次都发起 DNS 请求,费时费力。
- 5)解析到网页中的 urls 后,我们没有做任何去重处理,全部放入待爬取的列表中。事实上,可能有很多链接是重复的,我们做了很多重复劳动。
- 6)…..
4.找了这么多茬后,现在讨论一下问题的解决方案。
- 1)并行爬取问题。我们可以有多种方法去实现并行。多线程或者线程池方式,一个爬虫程序内部开启多个线程。同一台机器开启多个爬虫程序,如此,我们就有N多爬取线程在同时工作。能大大减少时间。此外,当我们要爬取的任务特别多时,一台机器、一个网点肯定是不够的,我们必须考虑分布式爬虫。常见的分布式架构有:主从(Master——Slave)架构、点对点(Peer to Peer)架构,混合架构等。说到分布式架构,那我们需要考虑的问题就有很多,我们需要分派任务,各个爬虫之间需要通信合作,共同完成任务,不要重复爬取相同的网页。分派任务我们要做到公平公正,就需要考虑如何进行负载均衡。负载均衡,我们第一个想到的就是Hash,比如根据网站域名进行hash。负载均衡分派完任务之后,千万不要以为万事大吉了,万一哪台机器挂了呢?原先指派给挂掉的哪台机器的任务指派给谁?又或者哪天要增加几台机器,任务有该如何进行重新分配呢 ?一个比较好的解决方案是用一致性 Hash 算法。
- 2)待爬取网页队列。如何对待待抓取队列,跟操作系统如何调度进程是类似的场景。不同网站,重要程度不同,因此,可以设计一个优先级队列来存放待爬起的网页链接。如此一来,每次抓取时,我们都优先爬取重要的网页。当然,你也可以效仿操作系统的进程调度策略之多级反馈队列调度算法。
- 3)DNS缓存。为了避免每次都发起DNS查询,我们可以将DNS进行缓存。DNS缓存当然是设计一个hash表来存储已有的域名及其IP。
- 4)网页去重。说到网页去重,第一个想到的是垃圾邮件过滤。垃圾邮件过滤一个经典的解决方案是 Bloom Filter(布隆过滤器)。布隆过滤器原理简单来说就是:建立一个大的位数组,然后用多个 Hash 函数对同一个 url 进行 hash 得到多个数字,然后将位数组中这些数字对应的位置为1。下次再来一个url时,同样是用多个Hash函数进行hash,得到多个数字,我们只需要判断位数组中这些数字对应的为是全为1,如果全为1,那么说明这个url已经出现过。如此,便完成了url去重的问题。当然,这种方法会有误差,只要误差在我们的容忍范围之类,比如1万个网页,我只爬取到了9999个,也是可以忍受滴。。。
- 5)数据存储的问题。数据存储同样是个很有技术含量的问题。用关系数据库存取还是用 NoSQL,或是自己设计特定的文件格式进行存储,都大有文章可做。
- 6)进程间通信。分布式爬虫,就必然离不开进程间的通信。我们可以以规定的数据格式进行数据交互,完成进程间通信。
- 7)……
如何实现上面这些东西 ???
实现的过程中,你会发现,我们要考虑的问题远远不止上面这些。纸上得来终觉浅,觉知此事要躬行!
2. 如何 "跟踪" 和 "过滤"
在很多情况下,我们并不是只抓取某个页面,而需要 "顺藤摸瓜",从几个种子页面,通过超级链接索,最终定位到我们想要的页面。Scrapy 对这个功能进行了很好的抽象:
from abc import ABC
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
from scrapy.selector import Selector
from scrapy.item import Item
class Coder4Spider(CrawlSpider, ABC):
name = 'coder4'
allowed_domains = ['xxx.com']
start_urls = ['http://www.xxx.com']
rules = (
Rule(LinkExtractor(allow=('page/[0-9]+',))),
Rule(LinkExtractor(allow=('archives/[0-9]+',)), callback='parse_item'),
)
def parse_item(self, response):
self.log(f'request url : {response.url}')在上面,我们用了 CrawlSpider 而不是 Spider。其中 name、 allowed_domains、start_urls 就不解释了。
重点说下 Rule:
-
第 1 条不带 callback 的,表示只是 “跳板”,即只下载网页并根据 allow 中匹配的链接,去继续遍历下一步的页面,实际上 Rule 还可以指定 deny=xxx 表示过滤掉哪些页面。
-
第 2 条带 callback 的,是最终会回调 parse_item 函数的网页。
3. 如何 "过滤重复" 的页面
Scrapy 支持通过 RFPDupeFilter 来完成页面的去重(防止重复抓取)。
DUPEFILTER_CLASS = 'scrapy.dupefilters.RFPDupeFilter'RFPDupeFilter 实际是根据 request_fingerprint 实现过滤的。
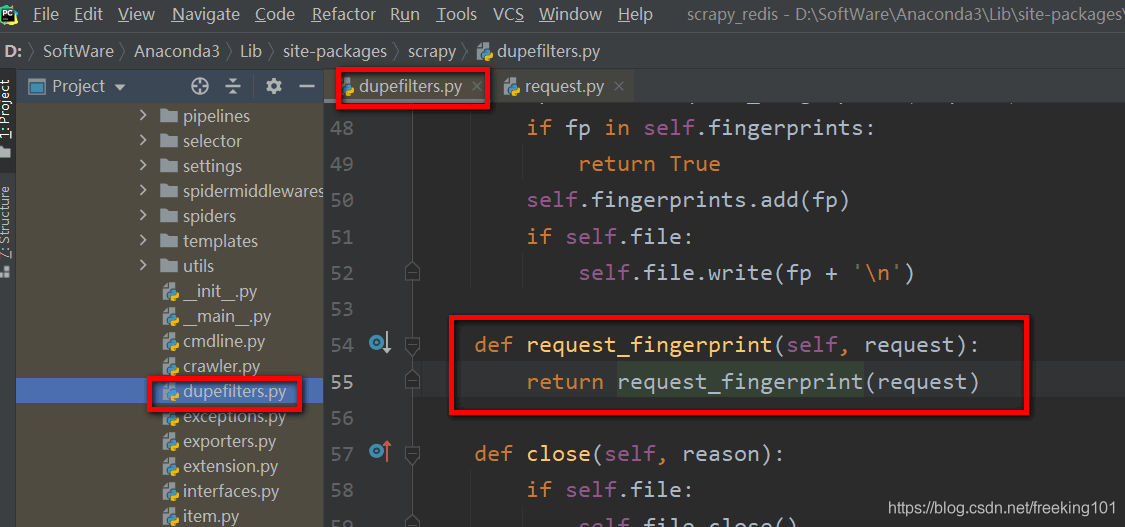

源码中实现如下:
def request_fingerprint(request, include_headers=None, keep_fragments=False):
if include_headers:
include_headers = tuple(to_bytes(h.lower()) for h in sorted(include_headers))
cache = _fingerprint_cache.setdefault(request, {})
cache_key = (include_headers, keep_fragments)
if cache_key not in cache:
fp = hashlib.sha1()
fp.update(to_bytes(request.method))
fp.update(to_bytes(canonicalize_url(request.url, keep_fragments=keep_fragments)))
fp.update(request.body or b'')
if include_headers:
for hdr in include_headers:
if hdr in request.headers:
fp.update(hdr)
for v in request.headers.getlist(hdr):
fp.update(v)
cache[cache_key] = fp.hexdigest()
return cache[cache_key]我们可以看到,去重指纹是 sha1(method + url + body + header),所以,实际能够去掉重复的比例并不大。如果我们需要自己提取去重的 finger,需要自己实现 Filter,并配置上它。下面这个 Filter 只根据 url 去重:
from scrapy.dupefilters import RFPDupeFilter
class SeenURLFilter(RFPDupeFilter):
"""A dupe filter that considers the URL"""
def __init__(self, path=None):
self.urls_seen = set()
RFPDupeFilter.__init__(self, path)
def request_seen(self, request):
if request.url in self.urls_seen:
return True
else:
self.urls_seen.add(request.url)不要忘记配置上:
DUPEFILTER_CLASS ='scraper.custom_filters.SeenURLFilter'4. 海量数据处理算法 Bloom Filter
海量数据处理算法—Bloom Filter:https://www.cnblogs.com/zhxshseu/p/5289871.html
结合 Guava 源码解读布隆过滤器:http://cyhone.com/2017/02/07/Introduce-to-BloomFilter/
更多:https://www.baidu.com/s?wd=Bloomfilter%20%E7%AE%97%E6%B3%95
Bloom-Filter,即布隆过滤器,1970年由 Bloom 中提出。是一种多哈希函数映射的快速查找算法。通常应用在一些需要快速判断某个元素是否属于集合,但是并不严格要求100%正确的场合。Bloom Filter 有可能会出现错误判断,但不会漏掉判断。也就是Bloom Filter 如果判断元素不在集合中,那肯定就是不在。如果判断元素存在集合中,有一定的概率判断错误。。。
因此,Bloom Filter 不适合那些 "零错误" 的应用场合。而在能容忍低错误率的应用场合下,Bloom Filter 比其他常见的算法(如hash,折半查找)极大节省了空间。
- 优点是空间效率和查询时间都远远超过一般的算法,
- 缺点是有一定的误识别率和删除困难。
一. 实例
为了说明 Bloom Filter 存在的重要意义,举一个实例:假设要你写一个网络蜘蛛(web crawler)。由于网络间的链接错综复杂,蜘蛛在网络间爬行很可能会形成 “环”。为了避免形成“环”,就需要知道蜘蛛已经访问过那些 URL。给一个 URL,怎样知道蜘蛛是否已经访问过呢?稍微想想,就会有如下几种方案:
- 1. 将访问过的 URL 保存到数据库。
- 2. 用 HashSet 将访问过的 URL 保存起来。那只需接近 O(1) 的代价就可以查到一个 URL 是否被访问过了。
- 3. URL 经过 MD5 或 SHA-1 等单向哈希后再保存到 HashSet 或数据库。
- 4. Bit-Map 方法。建立一个 BitSet,将每个 URL 经过一个哈希函数映射到某一位。
方法 1~3 都是将访问过的 URL 完整保存,方法4 则只标记 URL 的一个映射位。以上方法在数据量较小的情况下都能完美解决问题,但是当数据量变得非常庞大时问题就来了。
- 方法 1 的 缺点:数据量变得非常庞大后关系型数据库查询的效率会变得很低。而且每来一个URL就启动一次数据库查询是不是太小题大做了?
- 方法 2 的 缺点:太消耗内存。随着 URL 的增多,占用的内存会越来越多。就算只有1亿个 URL,每个 URL 只算 50 个字符,就需要 5GB 内存。
- 方法 3 :由于字符串经过 MD5 处理后的信息摘要长度只有128Bit,SHA-1 处理后也只有 160Bit,因此 方法3 比 方法2 节省了好几倍的内存。
- 方法 4 :消耗内存是相对较少的,但缺点是单一哈希函数发生冲突的概率太高。还记得数据结构课上学过的 Hash 表冲突的各种解决方法么?若要降低冲突发生的概率到1%,就要将 BitSet 的长度设置为 URL 个数的 100 倍。
实质上,上面的算法都忽略了一个重要的隐含条件:允许小概率的出错,不一定要100%准确!也就是说少量 url 实际上没有没网络蜘蛛访问,而将它们错判为已访问的代价是很小的——大不了少抓几个网页呗。
二. Bloom Filter 的算法
废话说到这里,下面引入本篇的主角——Bloom Filter。其实上面方法4的思想已经很接近 Bloom Filter 了。方法四的致命缺点是冲突概率高,为了降低冲突的概念,Bloom Filter 使用了多个哈希函数,而不是一个。
Bloom Filter 算法如下:创建一个 m位 BitSet,先将所有位初始化为0,然后选择 k个 不同的哈希函数。第 i个 哈希函数对 字符串str 哈希的结果记为 h(i,str),且 h(i,str)的范围是 0 到 m-1 。
- (1) 加入字符串过程。下面是每个字符串处理的过程,首先是将字符串 str “记录” 到 BitSet 中的过程:对于字符串 str,分别计算 h(1,str),h(2,str)…… h(k,str)。然后将 BitSet 的第 h(1,str)、h(2,str)…… h(k,str)位设为1。下图是 Bloom Filter 加入字符串过程,很简单吧?这样就将字符串 str 映射到 BitSet 中的 k 个二进制位了。
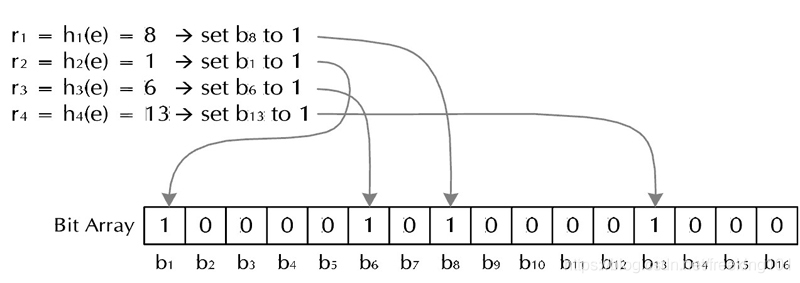
- (2) 检查字符串是否存在的过程。下面是检查字符串str是否被BitSet记录过的过程:对于字符串 str,分别计算 h(1,str),h(2,str)…… h(k,str)。然后检查 BitSet 的第 h(1,str)、h(2,str)…… h(k,str)位是否为1,若其中任何一位不为1则可以判定str一定没有被记录过。若全部位都是1,则 “认为” 字符串 str 存在。若一个字符串对应的 Bit 不全为1,则可以肯定该字符串一定没有被 Bloom Filter 记录过。(这是显然的,因为字符串被记录过,其对应的二进制位肯定全部被设为1了)。但是若一个字符串对应的Bit全为1,实际上是不能100%的肯定该字符串被 Bloom Filter 记录过的。(因为有可能该字符串的所有位都刚好是被其他字符串所对应)这种将该字符串划分错的情况,称为 false positive 。
三. Bloom Filter 参数选择
- (1) 哈希函数选择。哈希函数的选择对性能的影响应该是很大的,一个好的哈希函数要能近似等概率的将字符串映射到各个Bit。选择k个不同的哈希函数比较麻烦,一种简单的方法是选择一个哈希函数,然后送入k个不同的参数。
- (2) m,n,k 值,我们如何取值。我们定义:
可能把不属于这个集合的元素误认为属于这个集合(False Positive)
不会把属于这个集合的元素误认为不属于这个集合(False Negative)。
哈希函数的个数 k、位数组大小 m、加入的字符串数量 n 的关系。哈希函数个数k取10,位数组大小m设为字符串个数 n 的20倍时,false positive 发生的概率是0.0000889 ,即10万次的判断中,会存在 9 次误判,对于一天1亿次的查询,误判的次数为9000次。
哈希函数个数 k、位数组大小 m、加入的字符串数量 n 的关系可以参考参考文献 ( http://pages.cs.wisc.edu/~cao/papers/summary-cache/node8.html )。
| m/n | k | k=17 | k=18 | k=19 | k=20 | k=21 | k=22 | k=23 | k=24 |
| 22 | 15.2 | 2.67e-05 | |||||||
| 23 | 15.9 | 1.61e-05 | |||||||
| 24 | 16.6 | 9.84e-06 | 1e-05 | ||||||
| 25 | 17.3 | 6.08e-06 | 6.11e-06 | 6.27e-06 | |||||
| 26 | 18 | 3.81e-06 | 3.76e-06 | 3.8e-06 | 3.92e-06 | ||||
| 27 | 18.7 | 2.41e-06 | 2.34e-06 | 2.33e-06 | 2.37e-06 | ||||
| 28 | 19.4 | 1.54e-06 | 1.47e-06 | 1.44e-06 | 1.44e-06 | 1.48e-06 | |||
| 29 | 20.1 | 9.96e-07 | 9.35e-07 | 9.01e-07 | 8.89e-07 | 8.96e-07 | 9.21e-07 | ||
| 30 | 20.8 | 6.5e-07 | 6e-07 | 5.69e-07 | 5.54e-07 | 5.5e-07 | 5.58e-07 | ||
| 31 | 21.5 | 4.29e-07 | 3.89e-07 | 3.63e-07 | 3.48e-07 | 3.41e-07 | 3.41e-07 | 3.48e-07 | |
| 32 | 22.2 | 2.85e-07 | 2.55e-07 | 2.34e-07 | 2.21e-07 | 2.13e-07 | 2.1e-07 | 2.12e-07 | 2.17e-07 |
该文献证明了对于给定的 m、n,当 k = ln(2)* m/n 时出错的概率是最小的。(log2 e ≈ 1.44倍),同时该文献还给出特定的k,m,n的出错概率。例如:根据参考文献1,哈希函数个数k取10,位数组大小m设为字符串个数n的20倍时,false positive 发生的概率是 0.0000889 ,这个概率基本能满足网络爬虫的需求了。
四. Python 实现 Bloom filter
pybloomfiltermmap3 和 pybloom 是 不同 的包。。。。。
Python3 安装( pybloomfiltermmap3 ):pip install pybloomfiltermmap3
- pybloomfiltermmap3 github 地址:https://pypi.org/project/pybloomfiltermmap3/
- pybloomfiltermmap3 官方文档:https://pybloomfiltermmap3.readthedocs.io/en/latest/
- pybloomfiltermmap 的 github:https://github.com/axiak/pybloomfiltermmap
pybloomfiltermmap3 is a Python 3 compatible fork of pybloomfiltermmap by @axiak。pybloomfiltermmap3 的目标:在 python3 中为 bloom过滤器 提供一个快速、简单、可伸缩、正确的库。
Python 中文网:https://www.cnpython.com/pypi/pybloomfiltermmap3
#################################################################
Windows 安装报错解决方法:Python - 安装pybloomfilter遇到的问题及解决办法:https://blog.csdn.net/tianbianEileen/article/details/75059132
Stack Overflow 上的回答如下:
this problem looks like one “sys/mman.h:No such file or directory” And is a Unix header and is not available on Windows.
I suggest you should ues pybloom instead on windows:
pip install pybloom通过 pypi 搜索发现,最新的 pybloom 是 pybloom3 0.0.3
pybloom 的 github 地址:https://github.com/Hexmagic/pybloom3
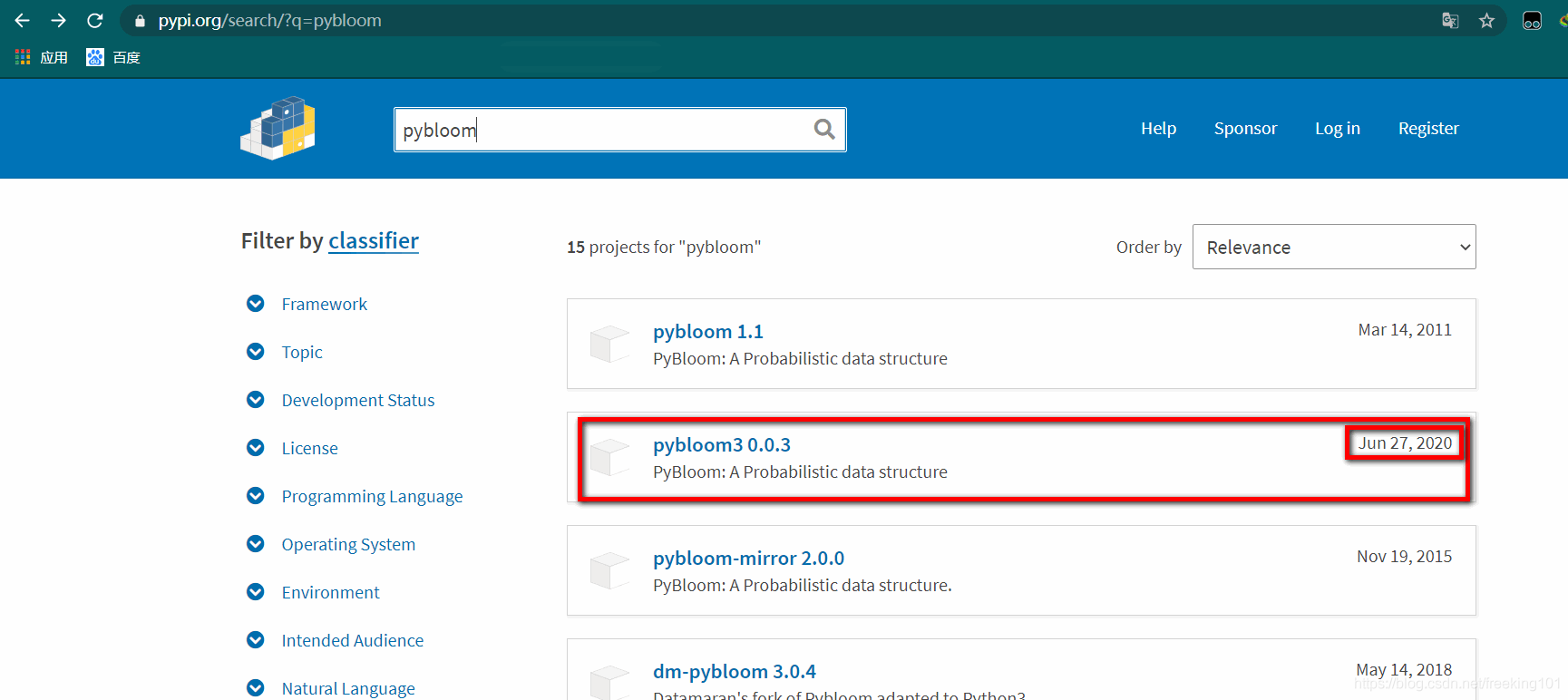
所以安装命令是:pip install pybloom3

and you should use the package like this:
from pybloom import BloomFilter#################################################################
pybloomfiltermmap3 快速示例:https://pybloomfiltermmap3.readthedocs.io/en/latest/
BloomFilter.copy_template(filename[, perm=0755]) → BloomFilter Creates a new BloomFilter object with the same parameters–same hash seeds, same size.. everything. Once this is performed, the two filters are comparable, so you can perform logical operators. Example:
>>> apple = BloomFilter(100, 0.1, '/tmp/apple')
>>> apple.add('apple')
False
>>> pear = apple.copy_template('/tmp/pear')
>>> pear.add('pear')
False
>>> pear |= appleBloomFilter.len(item) → Integer Returns the number of distinct elements that have been added to the BloomFilter object, subject to the error given in error_rate.
>>> bf = BloomFilter(100, 0.1, '/tmp/fruit.bloom')
>>> bf.add("Apple")
>>> bf.add('Apple')
>>> bf.add('orange')
>>> len(bf)
2
>>> bf2 = bf.copy_template('/tmp/new.bloom')
>>> bf2 |= bf
>>> len(bf2)
Traceback (most recent call last):
...
pybloomfilter.IndeterminateCountError: Length of BloomFilter object is
unavailable after intersection or union called.pybloom 快速示例:
from pybloom import BloomFilter
from pybloom import ScalableBloomFilter
f = BloomFilter(capacity=1000, error_rate=0.001)
print([f.add(x) for x in range(10)])
# [False, False, False, False, False, False, False, False, False, False]
print(all([(x in f) for x in range(10)]))
# True
print(10 in f)
# False
print(5 in f)
# True
f = BloomFilter(capacity=1000, error_rate=0.001)
for i in range(0, f.capacity):
_ = f.add(i)
print((1.0 - (len(f) / float(f.capacity))) <= f.error_rate + 2e-18)
# True
sbf = ScalableBloomFilter(mode=ScalableBloomFilter.SMALL_SET_GROWTH)
count = 10000
for i in range(0, count):
_ = sbf.add(i)
print((1.0 - (len(sbf) / float(count))) <= sbf.error_rate + 2e-18)
# True
# len(sbf) may not equal the entire input length. 0.01% error is well
# below the default 0.1% error threshold. As the capacity goes up, the
# error will approach 0.1%.五:Bloom Filter 的优缺点。
- 优点:节约缓存空间(空值的映射),不再需要空值映射。减少数据库或缓存的请求次数。提升业务的处理效率以及业务隔离性。
- 缺点:存在误判的概率。传统的 Bloom Filter 不能作删除操作。
六:Bloom-Filter 的应用场景
Bloom-Filter 一般用于在大数据量的集合中判定某元素是否存在。
- (1) 适用于一些黑名单,垃圾邮件等的过滤,例如邮件服务器中的垃圾邮件过滤器。像网易,QQ这样的公众电子邮件(email)提供商,总是需要过滤来自发送垃圾邮件的人(spamer)的垃圾邮件。一个办法就是记录下那些发垃圾邮件的 email 地址。由于那些发送者不停地在注册新的地址,全世界少说也有几十亿个发垃圾邮件的地址,将他们都存起来则需要大量的网络服务器。如果用哈希表,每存储一亿个 email地址,就需要 1.6GB的内存(用哈希表实现的具体办法是将每一个 email地址对应成一个八字节的信息指纹,然后将这些信息指纹存入哈希表,由于哈希表的存储效率一般只有 50%,因此一个 email地址需要占用十六个字节。一亿个地址大约要 1.6GB,即十六亿字节的内存)。因此存贮几十亿个邮件地址可能需要上百 GB的内存。而 Bloom Filter 只需要哈希表 1/8 到 1/4 的大小就能解决同样的问题。BloomFilter 决不会漏掉任何一个在黑名单中的可疑地址。而至于误判问题,常见的补救办法是在建立一个小的白名单,存储那些可能别误判的邮件地址。
- (2) 在搜索引擎领域,Bloom-Filte r最常用于网络蜘蛛(Spider)的 URL 过滤,网络蜘蛛通常有一个 URL 列表,保存着将要下载和已经下载的网页的 URL,网络蜘蛛下载了一个网页,从网页中提取到新的 URL 后,需要判断该 URL 是否已经存在于列表中。此时,Bloom-Filter 算法是最好的选择。
Google 的 BigTable。 Google 的 BigTable 也使用了 Bloom Filter,以减少不存在的行或列在磁盘上的查询,大大提高了数据库的查询操作的性能。
key-value 加快查询。
一般 Bloom-Filter 可以与一些 key-value 的数据库一起使用,来加快查询。一般 key-value 存储系统的 values 存在硬盘,查询就是件费时的事。将 Storage 的数据都插入Filter,在 Filter 中查询都不存在时,那就不需要去Storage 查询了。当 False Position 出现时,只是会导致一次多余的Storage查询。
由于 Bloom-Filter 所用空间非常小,所有 BF 可以常驻内存。这样子的话对于大部分不存在的元素,只需要访问内存中的 Bloom-Filter 就可以判断出来了,只有一小部分,需要访问在硬盘上的 key-value 数据库。从而大大地提高了效率。如图:

5. scrapy_redis 去重优化 ( 7亿数据 )
原文链接:https://blog.csdn.net/Bone_ACE/article/details/53099042
使用布隆去重代替scrapy_redis(分布式爬虫)自带的dupefilter:https://blog.csdn.net/qq_36574108/article/details/82889744
背景:
前些天接手了上一位同事的爬虫,一个全网爬虫,用的是 scrapy + redis 分布式,任务调度用的 scrapy_redis 模块。
大家应该知道 scrapy 是默认开启了去重的,用了 scrapy_redis 后去重队列放在 redis 里面,爬虫已经有7亿多条URL的去重数据了,再加上一千多万条 requests 的种子,redis 占用了160多G的内存(服务器,Centos7),总共才175G好么。去重占用了大部分的内存,不优化还能跑?
一言不合就用 Bloomfilter+Redis 优化了一下,内存占用立马降回到了二十多G,保证漏失概率小于万分之一的情况下可以容纳50亿条URL的去重,效果还是很不错的!在此记录一下,最后附上 Scrapy+Redis+Bloomfilter 去重的 Demo(可将去重队列和种子队列分开!),希望对使用 scrapy 框架的朋友有所帮助。
记录:
我们要优化的是去重,首先剥丝抽茧查看框架内部是如何去重的。
- 因为 scrapy_redis 会用自己 scheduler 替代 scrapy 框架的 scheduler 进行任务调度,所以直接去 scrapy_redis 模块下查看scheduler.py 源码即可。
-
在 open() 方法中有句:self.df = load_object(self.dupefilter_cls).from_spider(spider),其中 load_object(self.dupefilter_cls) 是根据对象的绝对路径而载入一个对象并返回,self.dupefilter_cls 就是 SCHEDULER_DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter',from_spider(spider) 是返回一个 RFPDupeFilter类 的实例。

再看下面的 enqueue_request() 方法,

里面有句 if not request.dont_filter and self.df.request_seen(request) ,self.df.request_seen()这就是用来去重的了。按住Ctrl再左键点击request_seen查看它的代码,可看到下面的代码:
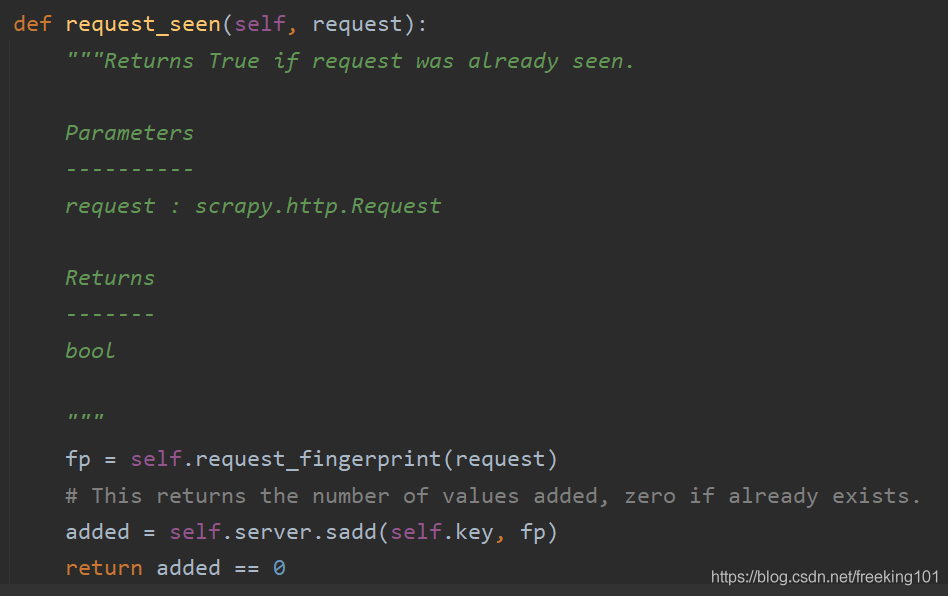
首先得到一个 request 的指纹,然后使用 Redis 的 set 保存指纹。可见 scrapy_redis 是利用 set 数据结构来去重的,去重的对象是 request 的 fingerprint。至于这个 fingerprint 到底是什么,可以再深入去看 request_fingerprint() 方法的源码(其实就是用 hashlib.sha1() 对 request 对象的某些字段信息进行压缩)。我们用调试也可以看到,其实 fp 就是 request 对象加密压缩后的一个字符串(40个字符,0~f)。
是否可用 Bloomfilter 进行优化?
以上步骤可以看出,我们只要在 request_seen() 方法上面动些手脚即可。由于现有的七亿多去重数据存的都是这个 fingerprint,所有 Bloomfilter 去重的对象仍然是 request 对象的 fingerprint。更改后的代码如下:
def request_seen(self, request):
fp = request_fingerprint(request)
if self.bf.isContains(fp): # 如果已经存在
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1517
1517











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









