







前言
集成学习(Ensemble Learning)是指用一系列分类\回归器共同对一个问题进行分类或回归的学习方法。其中,如果分类器都是同一类型的,比如都是决策树,那么这样的分类器称为同质分类器;反之如果分类器是不同类型的,那么就是异质分类器。常见的集成学习方法有Boost、Bagging、随机森林等等。其中Boost方法是主要用于二分类问题的用于减小偏差的一类方法,其主要通过将一系列基础分类器进行线性加权最终得到集成结果,并且其迭代及优化的过程有严谨的数学支撑。本文要实现的Bagging方法是一种可以减小方差的方法。而随机森林是将多个决策树\回归树的结果进行集成的方法。
一、Bagging的主要思想
Bagging是并行式集成学习方法最著名的代表。该方法基于自助采样法:给定包含m个样本的数据集,我们先随机取出一个样本放入采样集中,再把该样本放回初始数据集,使得下次采样时该样本仍有可能被选中。这样经过m次随机采样操作,我们得到一个含有m个样本的采样集。初试训练集中的样本有的在采样集中多次出现,有的则从未出现。一个样本从未出现的概率为
lim
m
→
∞
(
1
−
1
m
)
m
=
1
e
≈
0.268
\lim_{m\rightarrow \infty}{(1-\dfrac{1}{m})^{m}}=\dfrac{1}{e} \approx0.268
m→∞lim(1−m1)m=e1≈0.268,也就是说,训练集中大概有63.2%的样本出现在了采样集中。
按照上述步骤,我们可以采样出
T
T
T个含有
m
m
m个训练样本的采样集,然后基于每个采样集训练出一个基学习器,再将这些学习器进行组合。在对预测输出进行组合时,Bagging通常采用简单的投票法,即最终以数量较多的结果作为预测结果。其算法流程简化如下:
输入: 训练集
D
=
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
.
.
.
,
(
x
m
,
y
m
)
D=(x_{1},y_{1}),(x_{2},y_{2}),...,(x_{m},y_{m})
D=(x1,y1),(x2,y2),...,(xm,ym);
基学习算法
Σ
\mathcal{\Sigma}
Σ;
训练轮数
T
T
T。
过程:
1: for t=1,2,…,T do
2:
h
t
=
Σ
(
D
,
D
b
s
)
h_{t}=\Sigma(D,D_{bs})
ht=Σ(D,Dbs)
3:end for
输出:
H
(
x
)
=
arg max
y
∈
Y
∑
t
=
1
T
I
(
h
t
(
x
)
=
y
)
H(x)=\argmax_{y\in Y}\sum_{t=1}^{T}{I(h_{t}(x)=y)}
H(x)=y∈Yargmax∑t=1TI(ht(x)=y)
二、相关代码
可以看到,Bagging的流程其实非常简单,只需要以基学习器为基础,然后通过对训练集进行抽样出采样集,然后训练出T个基学习器,再简单搞个投票就可以了。本文使用上一篇的朴素贝叶斯分类器进行集成。
1.随机抽取采样集
代码如下:
sampleSetNum=10 #设定采样集的数量
length=data.shape[0] #获取原数据集的样本数
columns=data.columns
dataList=[]
for i in range(sampleSetNum):
indexs=np.random.randint(1,length,length)
dataFrame=pd.DataFrame(columns=columns)
for j in indexs:
dataFrame=pd.DataFrame.append(dataFrame,data.loc[j],ignore_index=True)
dataList.append(dataFrame)
2.生成各个采样集的贝叶斯概率表
代码如下:
pathList=[]
for i in range(sampleSetNum):
string="../Tabel/Tabel%i.npy"%i
pathList.append(string)
priorProbList=[] #保存先验概率
posterProbDict=[] #保存后验概率表
for i in range(len(dataList)):
temp=PosteriorProbDivided(dataList[i],columns[:-1],columns[-1],pathList[i])
priorProbList.append(temp)
posterProbDict.append(np.load(pathList[i],allow_pickle=True).item())
3.对每个基分类器进行结果预测并集成
def EnsembleBayes(data,label,priorProbList,posterProbDict):
length=data.shape[0]
acc=0
for i in range(length):
preList=[]
for j in range(len(priorProbList)):
tempPre=PosteriorFind(data.loc[i],posterProbDict[j],priorProbList[j])
preList.append(tempPre)
pre=np.argmax(np.bincount(preList)) #找出投票数最多的标签
if data[label][i]==pre:
acc+=1
ratio=acc/length
return ratio
效果
朴素贝叶斯对鸢尾花数据集的分类正确率

Bagging对鸢尾花数据集的分类正确率
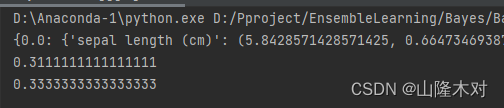
嗯…还是有所提升的















 1013
1013











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









