







斐波那契查找是一种在有序表中高效查找指定元素的算法,比折半查找要复杂一些,主要复杂在要多做不少准备工作。下面看它的工作流程:
1.计算并保存一个斐波那契序列的数组,方便以后取值。数组名记为f,例如f[1]=1,f[2]=1,f[3]=2,f[4]=3,f[5]=5,f[6]=8,f[7]=13,f[8]=21
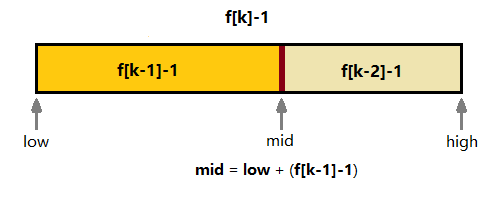
2.把有序数组的长度扩充到a.length=f[k]-1,k是满足条件的最小值,比如数组长度为13,那么就把它长度扩充到f[8]-1=20,所有在末尾添加的扩充元素都是原数组最后一个元素的复制品
3.找到mid元素,不断进行二分比较,直到找到目标元素为止,这一步的做法与折半查找一模一样,仅仅是计算mid的公式从(low+high)/2改为low+(f[k-1]-1)。
斐波那契查找的理解难点就一个:为什么需要把数组长度扩充到f[k]-1而不是f[k]或者f[k+1]?这是为了能正确递归计算mid值,看下图可发现 f[k]-1 = (f[k-1] + f[k-2]) - 1 = (f[k-1]-1) + 1 + (f[k-2]-1),中间的1就是我们二分的锚点mid,如果目标在左区,数组长度就缩到(f[k-1]-1),如果在右区,数组长度就缩到(f[k-2]-1),否则就等于mid完成查找。而(f[k-1]-1)又能拆成(f[k-2]-1)+1+(f[k-3]-1),这样递归分割下去就能不断的缩小区间直至找到目标。
斐波那契查找与折半查找的比较:
二者理论效率半斤八两,时间复杂度都是log2n,有人说斐波那契查找比折半查找效率高,理由有2个:1.斐波那契查找只用到加减法,而折半查找计算mid时要除以2,除法很影响效率;2.如果目标在low->mid区,只需要判断一次,而如果在mid->high需要判断2次(需要先判断不在low->mid区,再判断在mid->high区),斐波那契查找的low->mid区更大(0.618>0.5),有更多的概率只需要判断一次,所以总体判断次数更少。
原因1看起来有理,可是现在的编译器只要遇到/2操作,都会优化为>>1,位运算比加减法只快不慢,所以原因1不成立。原因2也貌似有些道理,可是如果按照这个道理推理下去,把分割点设在0.99岂不是更好?可0.99明显是个垃圾分割点,二分力度很差,所以这个理由我也不认可。
我在实际测试中也没有得到斐波那契查找更快的证据,二者总体上效率一致,甚至在我的测试数据中折半查找还要更快一点点,看来还是简单暴力的折半查找更得我心。















 536
536

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









