







动机
- 一些利用类别语义信息的图像多标签分类模型只是使用语义信息作为视觉特征的补充或指导区分量词推导的辅助信息,而没有关注语义空间、语义空间和视觉空间之间的相互关系。
贡献
- DSDL可以同时利用标签空间、语义空间和视觉空间;
- 针对深层语义词典学习,设计了一种新的训练策略,即交替参数更新策略(APUS),它在正向传播和反向传播中交替更新表示系数和语义词典。
方法
- Overview。该模型将多标签图像分类视为一个特质字典表示问题,利用类别的word embedding来生成语义词典,并将label embedding作为表示给定样本视觉特征的系数。
- 大体分为三个模块:特征学习模块、语义词典生成模块和视觉特征表示模块。

下面具体来看每一个模块。 - 特征学习模块
使用在ImageNet上预训练的ResNet101作为backbone。从最终的卷积层得到2048x14x14维的特征图。用全局最大池化获得2048维的全局特征f。输入图像被随机裁剪并调整为448x448大小。随机水平翻转用来进行数据增强。


-语义字典生成模块
使用自动编码器来非线性地完成字典的生成。NLP里大量的研究表明,自动编码器可以很好地利用语义空间,通过双向变换来缓解模型的过度拟合。

-视觉特征表示模块:利用学习到的语义词典来表示视觉特征

DSDL与传统的字典学习方法有很大的不同,传统的字典学习方式通常是过完备的(c>d),这篇论文里的字典是欠完备的(c<d)。 - 总体的目标函数与算法如下。算法整体包含了系数更新和语义词典更新两个阶段,在正向和反向传播

- 多标签图像分类

实验
- 数据集:voc 2007、voc 2012、coco
- 评价指标:整体精度、召回率、F1度量(OP、OR、OF1)和每类精度、召回率、F1度量(CP、CR、CF1)
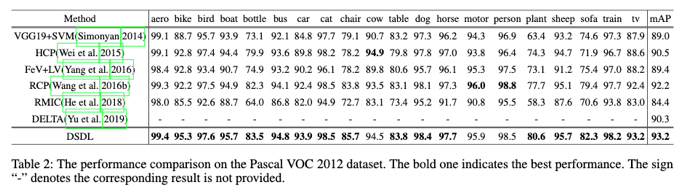
结果




总结
概况一下整篇论文。
提出了一种端到端的深度语义词典学习方法。DSDL采用字典学习技术,利用并协调所有涉及的空间,包括标签空间、语义空间和视觉空间,通过生成语义词典,将视觉特征的重构作为词典查询任务,得到归一化的表示系数作为标签的发生概率。















 1051
1051











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









