







激活函数:
神经元经过加权融合后一般还需要经过激活函数激活,主要作用就是为了增加神经网络模型的非线性。否则你想想,没有激活函数的每层都相当于矩阵相乘。就算你叠加了若干层之后,无非还是个矩阵相乘罢了。主要的激活函数有sigmoid、tanh、ReLU等。


损失函数(loss function)或代价函数(cost function):
是将随机事件或其有关随机变量的取值映射为非负实数以表示该随机事件的“风险”或“损失”的函数。在应用中,损失函数通常作为学习准则与优化问题相联系,即通过最小化损失函数求解和评估模型。例如在统计学和机器学习中被用于模型的参数估计(parametric estimation) [1] ,在宏观经济学中被用于风险管理(risk mangement)和决策 [2] ,在控制理论中被应用于最优控制理论(optimal control theory) [3] 。
简单来说就是预测值和真实值的平方差。
L2 LOSS

CROSS-ENTROPY LOSS(交叉熵损失函数)

在神经网络中,不论是哪种网络,最后都是在找层和层之间的关系(参数,也就是层和层之间的权重),而找参数的过程就称为学习,所以神经网路的目的就是不断的更新参数,去最小化损失函数的值,然后找到最佳解。选择合适的梯度下降优化方法可以让我们取得更好的结果,接下来我们简单的梳理梯度下降的优化算法。
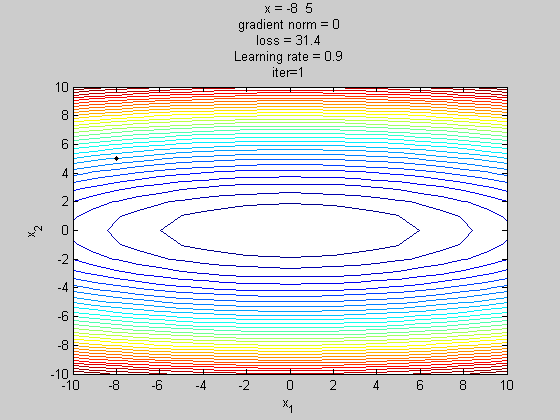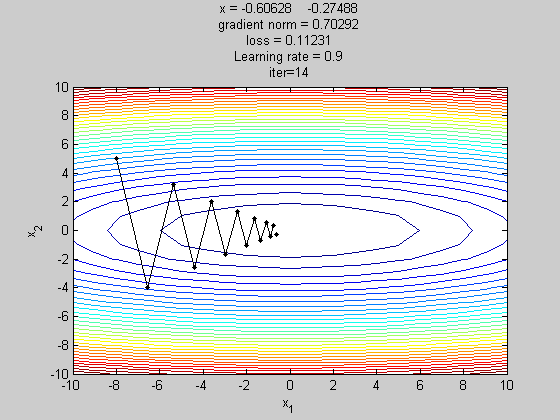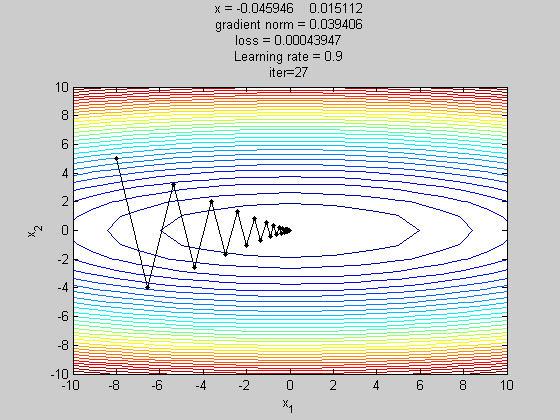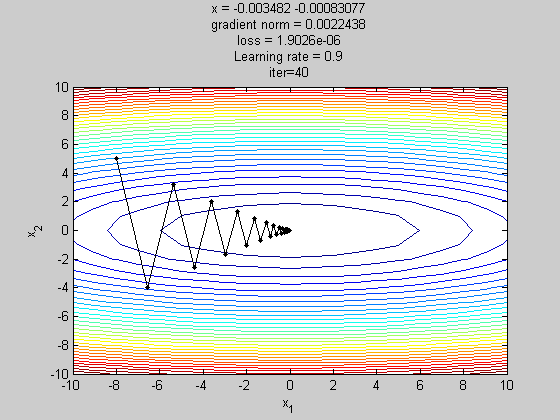
梯度下降法(gradient descent,GD)
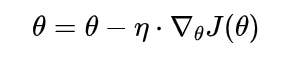
随机梯度下降法(Stochastic gradient descent, SGD)

Momentum
为了缓解SGD的在收敛时由于学习率过大导致在最优解附近波动的问题,Momentum在计算梯度时,当前时刻的梯度是从开始时刻到当前时刻的梯度指数加权平均。其中m是momentum项(一般设定为0.9)。主要是用在计算参数更新方向前会考虑前一次参数更新的方向,如果当下梯度方向和历史参数更新的方向一致,则会增强这个方向的梯度,反之,则梯度会衰退。然后每一次对梯度作方向微调。这样可以增加学习上的稳定性(梯度不更新太快),这样可以学习的更快,并且有摆脱局部最佳解的能力。如下图所示

Adam
上面的算法中的学习率都是固定不变的,Adam是对学习率自适应调整。Adam不仅和momentum一样计算参数更新方向前会考虑前一次参数更新的方向,还在学习率上依据梯度的大小对学习率进行加强或是衰减。

m t和v t分别是梯度的一阶动差函数和二阶动差函数(非去中心化)。因为m t和v t初始设定是全为0的向量,Adam的作者发现算法偏量很容易区近于0,因此他们提出修正项,去消除这些偏量。
激活函数
激活函数增加了神经网络模型的非线性,解决线性模型所不能解决的问题。下面我们介绍几个常用的激活函数:sigmoid、tanh、ReLu、Leaky ReLU。



















 806
806











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









