







机器学习(Machine Learning, ML)是人工智能的子集,聚焦于通过数据自动改进算法性能的理论。其核心理论源于统计学、计算学习理论与优化理论。
逻辑回归(Logistic Regression)是一种用于解决二分类(少数情况下可处理多分类)问题的机器学习算法,虽名为“回归”,但实际属于分类模型。其核心思想是通过构建线性回归模型![]() 拟合特征的线性组合,再利用 sigmoid函数
拟合特征的线性组合,再利用 sigmoid函数![]() 将输出值映射到 [0,1]区间,转化为样本属于正类的概率
将输出值映射到 [0,1]区间,转化为样本属于正类的概率![]() 。模型通过交叉熵损失函数衡量预测概率与真实标签的差异,利用梯度下降等优化算法更新参数w和 b,最终以概率阈值(如0.5)判断样本类别。逻辑回归具有简单高效、可解释性强(通过特征权重分析影响因素)的优点,常用于金融风控(如违约预测)、医学诊断(如疾病概率评估)、广告 CTR 预估等场景,但对非线性数据需依赖特征工程,且无法直接处理多分类问题(需通过 One-vs-Rest 等策略扩展)。
。模型通过交叉熵损失函数衡量预测概率与真实标签的差异,利用梯度下降等优化算法更新参数w和 b,最终以概率阈值(如0.5)判断样本类别。逻辑回归具有简单高效、可解释性强(通过特征权重分析影响因素)的优点,常用于金融风控(如违约预测)、医学诊断(如疾病概率评估)、广告 CTR 预估等场景,但对非线性数据需依赖特征工程,且无法直接处理多分类问题(需通过 One-vs-Rest 等策略扩展)。
其中,构建的线性回归模型就是下图中的蓝色的线。
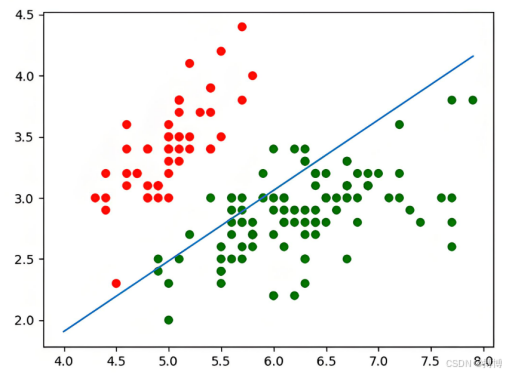
模型通过交叉熵损失函数衡量预测概率与真实标签的差异,利用梯度下降等优化算法不断地更新参数w和 b,最终以概率阈值(如0.5)判断样本类别,即实现了将上图中红点和蓝点划分开的目的。
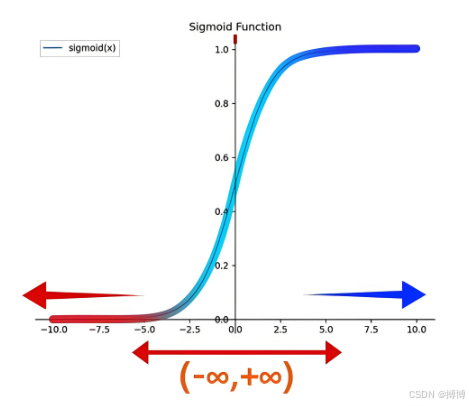
再利用 sigmoid函数(下图)将输出值映射到 [0,1]区间。
一、Python完整代码
这段代码实现了一个完整的机器学习工作流,使用逻辑回归模型对鸢尾花进行分类。
# 数据预处理与模型训练
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report
# 加载数据集
iris = load_iris()
X = iris.data # 特征:萼片/花瓣尺寸
y = iris.target # 标签:花类别
feature_names = iris.feature_names
# 划分训练集与测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 特征标准化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 训练逻辑回归模型
model = LogisticRegression(solver='lbfgs', random_state=42)
model.fit(X_train_scaled, y_train)
# 预测与评估
y_pred = model.predict(X_test_scaled)
accuracy = accuracy_score(y_test, y_pred)
print(f"测试集准确率:{accuracy:.2f}")
print("分类报告:")
print(classification_report(y_test, y_pred, target_names=iris.target_names))
# 模型解释:查看特征权重
print("\n特征权重:")
for name, weight in zip(feature_names, model.coef_[0]):
print(f"{name}: {weight:.4f}")二、数据处理流程
逻辑回归模型的数据处理流程如下:
以下从数据处理、模型训练、评估与解释三个方面进行详细解析。
(一)数据加载与理解
1.python代码示例:
在Python的scikit-learn(sklearn)库中,鸢尾花数据集(Iris Dataset)是一个经典的多分类基准数据集,常用于机器学习入门和分类算法验证。该数据集包含150个样本,分为3 个类别(山鸢尾Setosa、杂色鸢尾Versicolor、维吉尼亚鸢尾Virginica,各50个样本),每个样本描述了鸢尾花的4个特征:萼片长度(sepal length)、萼片宽度(sepal width)、花瓣长度(petal length)、花瓣宽度(petal width)(单位均为厘米)。数据集结构清晰,特征为连续数值型,标签为整数编码(0、1、2 分别对应三类),且类别间存在一定的线性可分性(如Setosa类可通过花瓣特征与其他两类明显区分),非常适合演示逻辑回归、决策树、支持向量机等分类算法的流程。
通过sklearn.datasets.load_iris()可直接加载该数据集,返回的对象包含.data(特征矩阵)、.target(标签数组)、.feature_names(特征名称)、.target_names(类别名称)等属性,是机器学习教学和实践中最常用的“Hello World”级数据集之一。
Python加载数据集:
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data # 特征矩阵:[萼片长度, 萼片宽度, 花瓣长度, 花瓣宽度]
y = iris.target # 标签:0=setosa, 1=versicolor, 2=virginica
feature_names = iris.feature_names # 特征名称列表2.数据集特点:
Iris Dataset核心信息
| 属性 | 详情 |
| 样本数 | 150 条(3 个类别,每类 50 条) |
| 特征数 | 4 个数值型特征(均为厘米单位) |
| 类别标签 | 0 = 山鸢尾(Setosa) 1 = 杂色鸢尾(Versicolor) 2 = 维吉尼亚鸢尾(Virginica) |
| 数据平衡性 | 完全平衡(每类样本数相等) |
| 应用场景 | 分类算法验证、模式识别教学、特征重要性分析 |
特征说明
| 特征名称 | 含义 | 数据类型 | 取值范围示例 |
| sepal length | 萼片长度 | 浮点数 | 4.3 ~ 7.9 cm |
| sepal width | 萼片宽度 | 浮点数 | 2.0 ~ 4.4 cm |
| petal length | 花瓣长度 | 浮点数 | 1.0 ~ 6.9 cm |
| petal width | 花瓣宽度 | 浮点数 | 0.1 ~ 2.5 cm |
示例数据(前5条 + 每类最后1条)
| 序号 | 萼片长度 (cm) | 萼片宽度 (cm) | 花瓣长度 (cm) | 花瓣宽度 (cm) | 类别编码 | 类别名称 |
| 1 | 5.1 | 3.5 | 1.4 | 0.2 | 0 | Setosa |
| 2 | 4.9 | 3.0 | 1.4 | 0.2 | 0 | Setosa |
| 3 | 4.7 | 3.2 | 1.3 | 0.2 | 0 | Setosa |
| 4 | 4.6 | 3.1 | 1.5 | 0.2 | 0 | Setosa |
| 5 | 5.0 | 3.6 | 1.4 | 0.2 | 0 | Setosa |
| 50 | 5.0 | 3.3 | 1.4 | 0.2 | 0 | Setosa |
| 51 | 7.0 | 3.2 | 4.7 | 1.4 | 1 | Versicolor |
| 100 | 5.9 | 3.0 | 4.2 | 1.5 | 1 | Versicolor |
| 101 | 6.3 | 3.3 | 6.0 | 2.5 | 2 | Virginica |
| 150 | 5.9 | 3.0 | 5.1 | 1.8 | 2 | Virginica |
类别特征分布差异
| 类别 | 萼片长度均值 | 萼片宽度均值 | 花瓣长度均值 | 花瓣宽度均值 |
| Setosa | 5.01 | 3.43 | 1.46 | 0.24 |
| Versicolor | 5.94 | 2.77 | 4.26 | 1.33 |
| Virginica | 6.59 | 2.97 | 5.55 | 2.03 |
关键区分特征:
(1)Setosa:花瓣长度和宽度显著小于其他两类(花瓣长度≈1.5cm)。
(2)Versicolor:各项特征值居中,与Virginica存在一定重叠。
(3)Virginica:花瓣长度和宽度最大(花瓣长度≈5.5cm)。
数据集总体特点:
(1)经典的多分类数据集,包含150个样本(每类50个)。
(2)特征为连续数值型,量纲可能不同(如萼片长度单位为厘米)。
(3)标签为整数编码,需注意其语义对应关系。
(二)数据集划分
1.python代码示例:
将数据集中的150个样本划分成两份,一份作为测试集,一份作为训练集。训练集是用于训练回归模型的,当训练好后,用测试集进行测试,看训练出来的模型,在测试集上预测的结果与训练集中的实际结果进行比较,看是否一致,或是判断误差大小。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)2.关键参数:
(1)test_size=0.3:将30%的数据作为测试集,70%作为训练集。
(2)random_state=42:固定随机种子,确保结果可复现。
这样划分的目的是分离训练数据和测试数据,避免模型对测试集过拟合,保证评估结果的客观性。
(三)特征标准化
1.python代码示例:
特征标准化(Feature Standardization)的核心目的是消除不同特征之间的量纲差异(如取值范围、单位),使模型能公平地对待所有特征,并提升算法的收敛效率和性能。具体而言:
(1)统一特征尺度:避免因特征取值范围差异(如“收入”以万元为单位、“年龄”以年为单位)导致模型过度关注数值大的特征,例如逻辑回归中,未标准化时,权重会偏向大尺度特征,而标准化后所有特征的权重可直接反映其对目标的影响程度。
(2)加速优化算法收敛:梯度下降类算法(如神经网络、支持向量机)在标准化后,损失函数的等高线更接近圆形,参数更新路径更直接,可显著减少迭代次数。例如,未标准化时,梯度可能沿陡峭方向震荡,而标准化后梯度方向更接近最优解方向。
(3)确保模型公平性与泛化性:标准化使特征具有相同的统计分布(通常为均值0、标准差1),避免因数据采集方式或单位不同引入的偏差,尤其适用于基于距离度量的算法(如K近邻、层次聚类),确保样本间距离计算不受尺度影响。
(4)典型场景:在使用线性模型(如逻辑回归)、深度学习模型或需要计算特征相似度的算法时,特征标准化通常是必要的预处理步骤。
说完了特征标准化的目的,接下来就是对数据集进行标准化:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train) # 计算均值、标准差并标准化训练集
X_test_scaled = scaler.transform(X_test) # 使用训练集的统计量标准化测试集标准化公式:![]()
其中,μ为训练集特征均值,σ为标准差。
2.关键细节:
仅使用训练集的统计量(fit_transform)标准化测试集(transform),避免数据泄露。
逻辑回归对特征尺度敏感,标准化可加速优化过程并提升模型稳定性。
三、模型训练与预测
(一)模型初始化与训练
1.python代码示例:
通过sklearn库进入模型函数LogisticRegression。
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(solver='lbfgs', random_state=42)
model.fit(X_train_scaled, y_train)2.逻辑回归原理:
(1)逻辑回归模型的本质
逻辑回归通过线性组合特征计算概率:
![]()
其中,w是特征权重,b 是偏置项。输出值通过sigmoid函数压缩到 [0,1] 区间,表示样本属于正类的概率。
(2)优化目标
通过最小化对数损失函数(Log Loss)估计参数:
![]()
其中,是真实标签,
是预测概率。正则化项(如 L2)会在损失函数中加入
![]() ,控制模型复杂度。
,控制模型复杂度。
(3)多分类扩展
通过softmax函数扩展到多分类:
![]()
本文中,对每个类别k,计算线性组合![]() ,并通过softmax函数转换为概率:
,并通过softmax函数转换为概率:
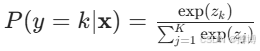
模型通过最大化对数似然函数(等价于最小化交叉熵损失)估计参数和
。
3.scikit-learn库中的LogisticRegression()函数
LogisticRegression()是scikit-learn库中实现逻辑回归算法的核心类,用于解决二分类或多分类问题。
核心参数详解
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(
penalty='l2', # 正则化类型(L2/L1/elasticnet)
C=1.0, # 正则化强度的倒数(值越小,正则化越强)
solver='lbfgs', # 优化算法(可选:lbfgs/newton-cg/liblinear/sag/saga)
max_iter=100, # 最大迭代次数
multi_class='auto', # 多分类策略(auto/binary/multinomial)
random_state=None, # 随机种子(控制训练过程的随机性)
class_weight=None, # 类别权重(处理不平衡数据)
...
)关键参数说明:
(1)penalty:防止过拟合的正则化方法。
'l2'(默认):适用于大多数场景,使权重更平滑。
'l1':生成稀疏解(部分权重为 0),可用于特征选择。
'elasticnet':结合L1和L2,仅支持solver='saga'。
(2)C:正则化强度的倒数。
较大的C:模型对训练数据拟合更紧密,可能过拟合。
较小的C:强制权重更接近 0,增强泛化能力。
(3)solver:优化算法选择。
'lbfgs'(默认):拟牛顿法优化器,适合小数据集和多分类,支持L2和无正则化。
'liblinear':支持L1正则化,不支持多分类的softmax。
'sag'/'saga':适合大数据集,支持稀疏矩阵。
(4)multi_class='multinomial' ,默认直接使用softmax函数(新版本,multi_class这个参数可以已经去掉了,可以不写)。类别间互斥时,使用multi_class='multinomial';二分类或独立二分类问题,使用multi_class='ovr'。'ovr' 表示对每个类别训练一个二分类器。
(5)random_state=42:固定初始化参数,确保结果可复现。
4.典型应用场景
(1)二分类:垃圾邮件检测(垃圾/非垃圾)、疾病诊断(阳性/阴性)。
(2)多分类:手写数字识别(0-9)、文本分类(政治/科技/娱乐)。
(3)概率预测:风险评估(违约概率)、点击率预估(CTR)。
(4)特征重要性分析:通过权重大小判断特征对结果的影响(如医学中各指标对疾病的贡献)。
5.优点
(1)高效可解释:训练和预测速度快,权重可直接解释特征重要性。
(2)概率输出:提供分类概率,而非仅硬分类结果。
(3)正则化支持:通过L1/L2防止过拟合,适合高维数据。
(4)扩展性强:可通过核技巧(Kernel Logistic Regression)处理非线性问题。
6.缺点
(1)线性假设:只能处理线性可分问题,需依赖特征工程引入非线性。
(2)对异常值敏感:异常样本可能显著影响模型参数。
(3)多分类局限性:处理多类别问题时,效果可能不如决策树或神经网络。
(二)模型预测
1.python代码示例:
Predict()为模型中的预测函数。
y_pred = model.predict(X_test_scaled) # 预测类别标签2.预测过程:
对每个测试样本,计算其属于各类别的概率,取概率最大的类别作为预测结果。
![]()
四、模型评估与解释
(一)准确率评估
1.python代码示例:
对以训练的模型进行评估。
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_test, y_pred)
print(f"测试集准确率:{accuracy:.2f}")2.准确率计算:
![]()
此例中准确率约为0.98(根据随机划分的训练集和测试集,数值会变化),表示模型在测试集上的预测正确率为98%。
(二)详细分类报告
1.python代码示例:
from sklearn.metrics import classification_report
print(classification_report(y_test, y_pred, target_names=iris.target_names))2.关键指标:
(1)精确率(Precision):预测为某类的样本中,实际为该类的比例。
(2)召回率(Recall):实际为某类的样本中,被正确预测的比例。
(3)F1分数:精确率和召回率的调和平均,综合评估分类性能。
(4)支持度(Support):各类别的实际样本数。
(三)特征重要性分析
1.python代码示例:
print("\n特征权重:")
for name, weight in zip(feature_names, model.coef_[0]):
print(f"{name}: {weight:.4f}")2.权重解释:
(1)model.coef_[0]对应类别0(setosa)的特征权重向量。
(2)权重绝对值越大,表示该特征对分类的影响越大;符号表示正/负相关性。
(3)例如,petal width (cm)的权重为1.0372,表明花瓣宽度越大,样本越可能属于setosa类。
五、代码执行流程与结果
(一)执行流程
(1)数据准备:加载鸢尾花数据集,划分为训练集(105样本)和测试集(45样本)。
(2)标准化:计算训练集特征的均值和标准差,应用于训练集和测试集。
(4)模型训练:使用标准化后的训练数据拟合逻辑回归模型。
(4)预测与评估:在测试集上预测并计算准确率和分类报告。
(5)解释分析:查看模型对各类别的特征权重,理解决策逻辑。
(二)典型输出示例
1.运行输出结果
将文章开头的代码,全部复制到一个文件中,可以用任意的开发工具,任意命名文件名。
确保本机已经安装了python,并已将python安装路径添加的path中。
之后打开CMD,先输入“py+空格”,之后将文件拖入到CMD中。回车就会执行。
可以参照我的上一篇文章:人工智能示例之基于规则的专家系统(动物识别)的python完整代码-CSDN博客
以下是运行结果示例。
测试集准确率:0.98
分类报告:
precision recall f1-score support
setosa 1.00 1.00 1.00 14
versicolor 0.95 1.00 0.97 16
virginica 1.00 0.94 0.97 15
accuracy 0.98 45
macro avg 0.98 0.98 0.98 45
weighted avg 0.98 0.98 0.98 45
特征权重:
sepal length (cm): 0.4474
sepal width (cm): -1.0683
petal length (cm): 1.7978
petal width (cm): 1.0372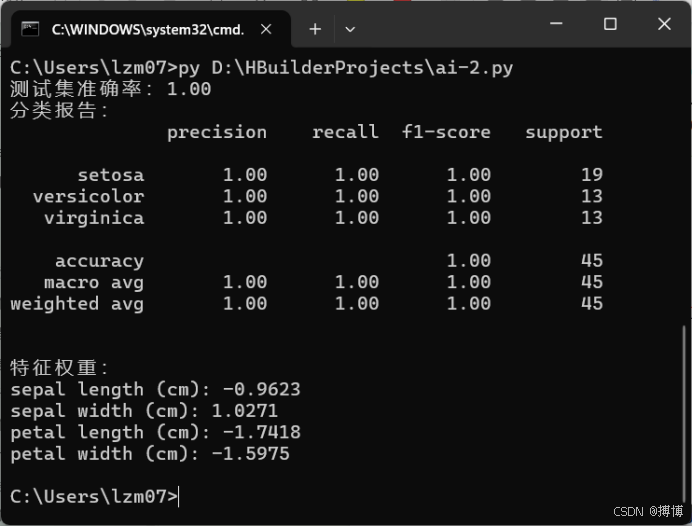
2.结果解读:
(1)模型对setosa类的预测完全正确(精确率、召回率均为1.00)。
(2)versicolor类有1个样本被误判为virginica,导致召回率为0.94。
(3)花瓣长度和宽度的权重较大,表明这两个特征对分类最为重要。
六、关键细节与最佳实践
(一)标准化的必要性
(1)逻辑回归基于梯度优化,特征尺度差异可能导致收敛缓慢或陷入局部最优。
(2)标准化后,所有特征的均值为0,标准差为1,避免了量纲影响。
(二)避免数据泄露
(1)测试集必须使用训练集的统计量(均值、标准差)进行标准化,不能重新计算。
(2)若对测试集单独标准化,会导致模型 “预见到” 测试数据的分布,高估真实性能。
(三)模型可解释性
线性模型的权重直观反映特征重要性,适合需要解释决策依据的场景(如医疗诊断)。
与树模型对比:树模型(如决策树)可通过特征重要性分数解释,神经网络则需依赖SHAP、LIME等后验解释方法。
(四)超参数选择
(1)solver='lbfgs':默认选择,适合小数据集和多分类问题。
(2)若数据量大,可选择solver='sag'或saga,支持随机梯度下降优化。
七、与传统AI的对比
| 维度 | 基于规则的专家系统 | 机器学习(逻辑回归) |
| 知识获取 | 人工定义规则 | 从数据中自动学习模式 |
| 可解释性 | 规则链透明(如“若A且B则C”) | 通过特征权重解释(如“花瓣长→更可能是 setosa”) |
| 数据依赖性 | 不需要或少量数据 | 依赖大量标注数据 |
| 泛化能力 | 依赖规则覆盖度,难以泛化 | 可学习数据中的隐含模式,泛化能力强 |
| 适应性 | 难以适应规则外的新场景 | 可通过增量训练适应新数据 |
通过此例可见,机器学习通过数据驱动的方式自动发现模式,避免了人工定义规则的局限性,但牺牲了部分直观解释性。


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











