






目录
① chmod命令 :修改指定文件的权限信息(读、写、执行)
一、引言
在大数据的浪潮中,Hadoop凭借其强大的数据处理能力成为了业界的佼佼者。而Hadoop分布式文件系统(HDFS)作为Hadoop的核心组件之一,为大数据存储提供了坚实的基础。本文将带您深入了解HDFS的本质、核心架构及其常用命令。
二、HDFS的本质
HDFS的中文翻译是Hadoop分布式文件系统(Hadoop Distributed File System)。它本质还是程序,主要还是以树状目录结构来管理文件(和linux类似,/表示根路径),且可以运行在多个节点上(即分布式)。HDFS是一个高度容错性的分布式文件系统,适用于处理大数据集。它能够跨机器存储大量的文件数据,并通过提供流式数据访问来处理各种应用程序。
| 高可靠性:通过冗余复制实现数据的持久性。 |
| 高扩展性:能够轻松处理PB级的数据。 |
| 高性能:适用于大数据集的批处理任务。 |
| 高容错性:能自动检测和处理硬件故障。 |
三、HDFS核心架构
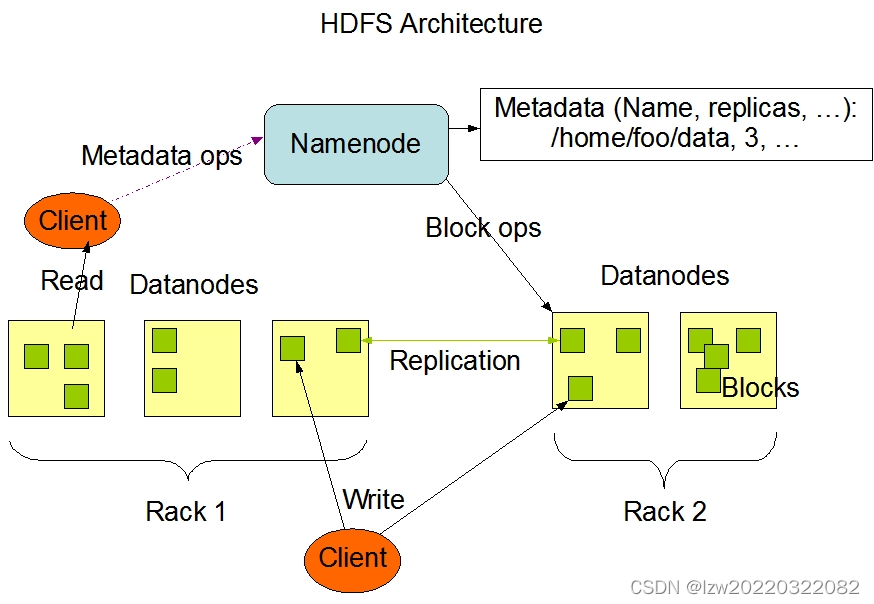
| 集群组成 | |
|---|---|
| NameNode | 管理HDFS的命名空间,配置副本策略,处理客户端读写请求, 管理文件系统的元数据,如文件目录结构、文件与数据块的映射关系等 |
| DataNode | 存储实际的数据块,并执行数据的读写操作, master下达命令,DataNode执行操作存储实际的数据块,执行数据块的读/写操作 |
| Secondary NameNode | 辅助NameNode进行元数据的合并操作,但并非NameNode的热备, 在紧急情况下,可以辅助恢复NameNode |
| 数据块与元数据 | |
|---|---|
| 数据块(Block) | HDFS中的文件被切分成多个大小相等的数据块进行存储。默认大小通常为128MB(可配置) |
| 元数据(Metadata) | 包括文件名、文件类型、权限、修改和访问时间以及文件与数据块的映射关系等信息 |
| 数据冗余与容错 | |
|---|---|
| 副本机制 | HDFS默认将每个数据块复制3份存储在不同的DataNode上,以确保数据的可靠性 |
| 心跳机制 | DataNode定期向NameNode发送心跳信号,报告自身状态及存储的数据块信息 |
| 校验和 | HDFS在数据块存储时生成校验和,并在读取时进行验证,以确保数据的完整性 |
四、HDFS的常用命令
1.文件系统操作
① ls命令 :显示HDFS指定路径下的所有文件
hdfs dfs -ls /
hdfs dfs -ls <path>
② mkdir命令 :在HDFS上创建文件夹
hdfs dfs -mkdir [-p] <path>
-p:如果要创建的目录的父目录不存在,则自动补上父目录
③ rm命令 :删除文件夹或目录
hdfs dfs -rm [-r] <path>
-r : 表示递归删除,即连同子目录一同删除
④ put命令 :上传本地文件到HDFS
hdfs dfs -put <local src path> <dst path>
dst path:HDFS目标路径,即文件将被上传到这个路径上
local src path:被上传的本地文件路径
⑤ cp命令 :在HDFS内部复制文件
hdfs dfs -cp <src path> <dst path>
⑥ mv命令 :在HDFS内部移动文件
hdfs dfs -mv <src path> <dst path>
⑦ get命令 :将HDFS的<src path>文件下载到本地文件系统的<local dst>路径
hdfs dfs -get <src path> <local dst>
src path:被下载的HDFS文件路径
local dst:本地文件系统目标路径,即文件将被下载到这个路径
2.文件内容操作
① cat命令 :查看文件
hdfs dfs -cat <path>
② tail命令 :查看文件末尾的内容
hdfs dfs -tail <path>
3.权限管理
① chmod命令 :修改指定文件的权限信息(读、写、执行)
chmod [可选项] <mode> <path>
可选项,常见的如-R:递归修改子目录
mode:权限设定字符串,语法:[ugoa][+-=][rwx]
(1)rwx:r表示可读取,w表示可写入,x表示可执行
(2)+-=:+表示增加权限、-表示取消权限、=表示唯一设定权限
(3)ugoa:u表示该文件的所有者,g表示所属组,o表示其他以外的人,a表示这三者皆是
② chown命令 :改变指定文件(夹)的所有者或者所属组
hdfs dfs -chown [-R] [OWNER][:[GROUP]] <path>
-R: 递归修改文件(夹)的所有者或者所属组。也就是路径下还有子目录,则一同修改。[OWNER][:[GROUP]]:指定所有者或所属组。
五、通过MapReduce任务管理HDFS文件系统
1.查看文件/文件夹
public class ls {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","192.168.220.100:8020");
//获取文件系统
FileSystem fs = FileSystem.get(conf);
//待访问的路径
Path path = new Path("/user/root");
//获取文件列表
FileStatus[] fileStatuses = fs.listStatus(path);
//遍历文件列表,查看文件/文件夹
for (FileStatus file : fileStatuses){
//只输出文件
if (file.isFile()){
System.out.println("只输出文件:"+file.getPath().toString());
}
//只输出文件夹
if (file.isDirectory()){
System.out.println("只输出文件夹:"+file.getPath().toString());
}
//路径下全输出
System.out.println("路径下全输出:"+file.getPath().toString());
}
fs.close();
System.out.println();
}
}2.创建文件夹
public class mkdir_folders {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","192.168.220.100:8020");
System.setProperty("HADOOP_USER_NAME","root");
//获取文件系统
FileSystem fs = FileSystem.get(conf);
//待访问的路径
Path path = new Path("/user/root/view_log/1/2");//要创建/2文件夹
//如果路径存在,返回提示已存在,不创建文件夹
if (fs.exists(path)){ //fs.exists判断路径是否存在
System.out.println("路径已存在,不需要重复创建");
}else{
fs.mkdirs(path);
System.out.println("已创建" + path + "路径");
}
String argss[] = new String[]{"/user/root/view_log/1/2"};
ls_R_2.main(argss);
fs.close();
}
}3.从HDFS下载文件到本地
public class get_files {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","192.168.220.100:8020");
System.setProperty("HADOOP_USER_NAME","root");
//获取文件系统
FileSystem fs = FileSystem.get(conf);
//待下载路径
Path frompath = new Path("/user/root/view_log/text.txt");
//下载到
Path topath = new Path("D:\\Hadoop\\idea-old\\project\\input");
File isfilepath = new File("D:\\Hadoop\\idea-old\\project\\input\\text.txt");
//判断本地Windows系统路径文件是否存在
if (isfilepath.exists()){
System.out.println("文件已存在,不需要重复下载");
}else {
//copyFromLocalFile 上传
//copyToLocalFile 下载
fs.copyToLocalFile(frompath, topath);
System.out.println("下载成功!");
}
fs.close();
}
}4.从本地上传文件到HDFS
public class put_files {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","192.168.220.100:8020");
System.setProperty("HADOOP_USER_NAME","root");
//获取文件系统
FileSystem fs = FileSystem.get(conf);
//待上传路径文件
Path frompath = new Path("D:\\Hadoop\\idea-old\\project\\input\\wordcount\\text.txt");
//上传到hdfs的路径
Path topath = new Path("/20220322082/data");
Path isfilepath = new Path("/20220322082/data");
//判断hdfs上文件是否存在
if (fs.exists(isfilepath)){
System.out.println("文件已存在,不需要重复上传!");
}else {
fs.copyFromLocalFile(frompath, topath);
System.out.println(isfilepath + "上传成功!");
}
fs.close();
}
}5.删除文件/文件夹
public class rm_files {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","192.168.220.100:8020");
System.setProperty("HADOOP_USER_NAME","root");
//获取文件系统
FileSystem fs = FileSystem.get(conf);
//待删除的文件路径
Path path = new Path("/user/root/view_log/text.txt");
if (fs.exists(path)){
fs.delete(path, true);
System.out.println(path + "已删除");
}else {
System.out.println("文件不存在!");
}
fs.close();
}
}














 6468
6468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









