







K-mean均值算法原理讲解和代码实战
前言
最近在学习吴恩达机器学习课程,刚刚学完第一个无监督学习算法,搭配着机器学习实战里面的k-mean实战,成功的将理论和实际结合了起来。接下来,咱们简单的分析算法原理之后,着重讲解一下源代码。
项目github地址:K-mean算法实战
文章目录
K-mean算法原理解析
K表示的是组的个数,也就是你想把这些数据分成几类。
算法主要思路:
- 随机选择k个点,作为聚类的中心点
- 将所有数据进行归类,归类标准是按照欧几里得距离,数据离哪个中心点近,就属于哪一类
- 移动聚类点。计算属于该中心点的数据的平均值,将聚类点移动到平均值位置
- 不断重复2、3,直到数据的归类不再发生变化
图形过程演示:
我使用了数据量是50,然后K值设定的是2,也就是分为两类
下面咱们看一下这个动图(文末有生成动图python代码地址):
接下来给大家解析一下:
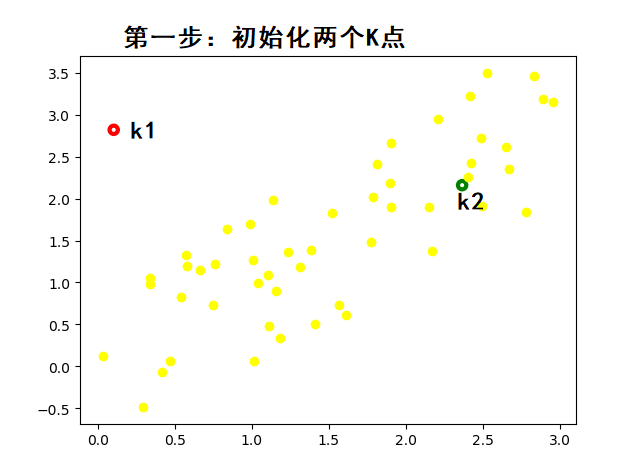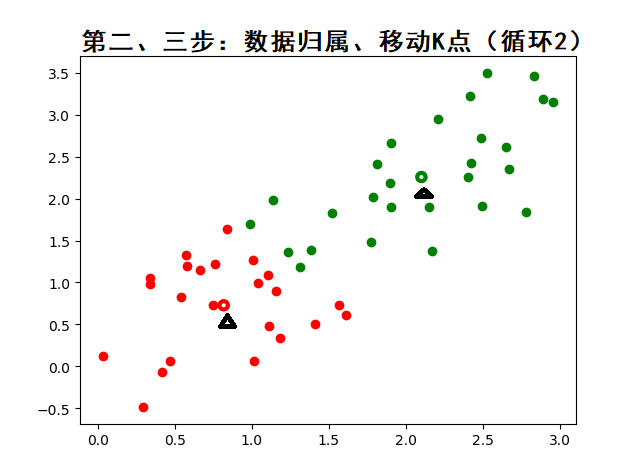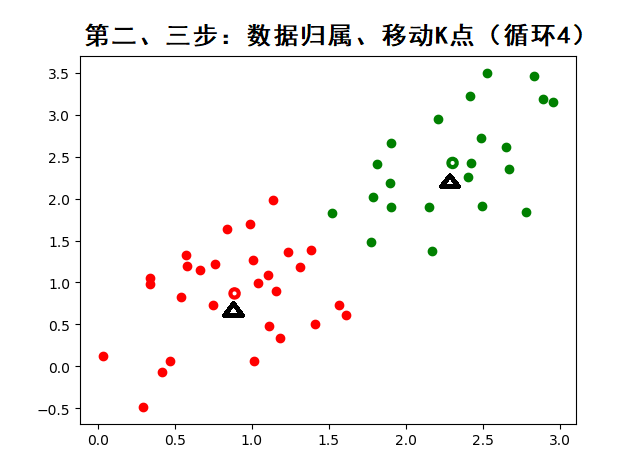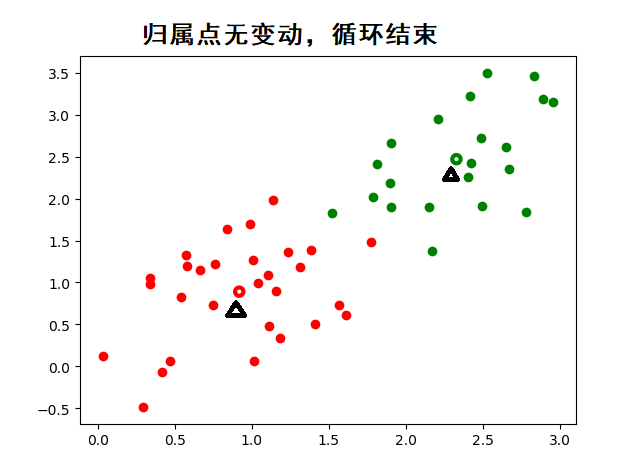
- 下图是随机初始化的两个K点,当然这个初始化是的范围是在数据点的范围之内

- 下图开始进行2、3步的循环:

- 直到数据归属不发生改变,则判定为当前K点为最佳值。数据归属是根据各个数据点距K点的距离判定的,使用的方法是欧几里得距离公式。

代码解析
一、生成数据
def CreatData():
x1 = np.random.rand(50)*3#0-3
y1 = [i+np.random.rand()*2-1 for i in x1]
with open('data.txt','w') as f:
for i in range(len(x1)):
f.write(str(x1[i])+'\t'+str(y1[i])+'\n')
二、读取数据
def loadDateSet(fileName):
dataMat=[]
fr = open(fileName)
for line in fr.readlines():
curline = line.strip().split('\t')
#map函数 对指定的序列做映射,第一个参数是function 第二个是序列
#此方法可以理解为进行字符串格式转换.这个函数可以深究
fltLine = map(float,curline)
dataMat.append(list(fltLine))
return dataMat
这里主要是说一下map这个方法
map(function,list) 此方法的作用是将第二个参数(列表或者迭代器)对前面的方法进行一一映射。
举个例子:
>>>def square(x) : # 计算平方数
... return x ** 2
...
>>> map(square, [1,2,3,4,5]) # 计算列表各个元素的平方
[1, 4, 9, 16, 25]
map(float,curline) 的作用可以理解为将curline 列表中的数字格式转换成float类型的。
三、欧几里得距离计算
def distEclud(vecA,vecB):
return np.sqrt(np.sum(np.power((vecA-vecB),2)))
四、显示变化数据变化过程
def showProcess(clusterAssment,centroids):
#显示过程
Index1 = np.nonzero(clusterAssment[:,0]==0)[0]
Index2 = []
for i in range 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3633
3633











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









