







 本文详细介绍了Pandas库在数据分析中的基础应用,包括数据读取、结构理解、查询、数据操作、合并等,重点展示了如何使用Pandas批量拆分和合并Excel文件的过程。
本文详细介绍了Pandas库在数据分析中的基础应用,包括数据读取、结构理解、查询、数据操作、合并等,重点展示了如何使用Pandas批量拆分和合并Excel文件的过程。
系列文章目录
第一章 Pandas 学习入门之pandas数据读取
第二章 Pandas 学习入门之pandas数据结构
第三章 Pandas 学习入门之pandas数据查询
第四章 Pandas 学习入门之pandas新增数据列
第五章 Pandas 学习入门之pandas数据统计函数
第六章 Pandas 学习入门之pandas处理缺失值
第七章 Pandas 学习入门之pandas数据排序
第八章 Pandas 学习入门之pandas字符串操作
第九章 Pandas 学习入门之pandas重要参数axis
第十章 Pandas 学习入门之pandas索引index用途
第十一章 Pandas 学习入门之pandas实现DataFrame的Merge
第十二章 Pandas 学习入门之pandas实现数据合并Concat
第十三章 Pandas 学习入门之pandas批量拆分Excel与合并Excel
随着人工智能的不断发展,数据分析这门技术也越来越重要,很多人都开启了学习数据分析,本文就介绍了pandas学习的基础内容。本章简单介绍了pandas批量拆分Excel与合并Excel。
前言
本章简单介绍了pandas批量拆分Excel与合并Excel。
提示:以下是本篇文章正文内容,下面案例可供参考
一、本章任务
实例演示:
- 将一个大Excel等份拆成多个Excel
- 将多个小Excel合并成一个大Excel并标记来源
二、准备工作
1.文件目录创建
代码如下(示例):
work_dir="./course_datas/c15_excel_split_merge"
splits_dir=f"{work_dir}/splits"
import os
if not os.path.exists(splits_dir):
os.mkdir(splits_dir)代码详解:
- 设置工作目录
work_dir为"./course_datas/c15_excel_split_merge"。- 设置
splits_dir为在work_dir下名为splits的目录路径。- 使用
os.path.exists()函数检查splits_dir是否存在。- 如果
splits_dir不存在(os.path.exists(splits_dir)返回False),则通过os.mkdir(splits_dir)创建该目录。- 代码正确地检查了
splits_dir目录(即"./course_datas/c15_excel_split_merge/splits")是否存在,如果不存在,则创建该目录。
2.引入库
import pandas as pd3.读取数据
df_source = pd.read_excel(f"{work_dir}/crazyant_blog_articles_source.xlsx")
df_source.head()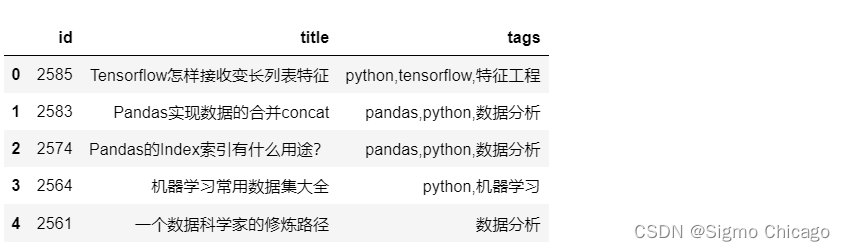
df_source.indexRangeIndex(start=0, stop=258, step=1)
df_source.shape(258, 3)
total_row_count = df_source.shape[0]
total_row_count258
shape返回的是一个元组( ,),功能类似于list
三、将一个大Excel等份拆成多个Excel
- 使用df.iloc方法,将一个大的dataframe,拆分成多个小dataframe
- 将使用dataframe.to_excel保存每个小Excel
1.计算拆分后的每个excel的行数
# 这个大excel,会拆分给这几个人
user_names = ["xiao_shuai", "xiao_wang", "xiao_ming", "xiao_lei", "xiao_bo", "xiao_hong"]# 每个人的任务数目
split_size = total_row_count // len(user_names)
if total_row_count % len(user_names) != 0:
split_size += 1
split_size43
2.拆分成多个dataframe
代码详解:
- 初始化一个空列表
df_subs,用于存储分割后的DataFrame信息。- 使用
enumerate(user_names)遍历用户名称列表,enumerate函数会返回每个元素的索引 (idx) 和值 (user_name)。- 计算每个子DataFrame的起始 (
begin) 和结束 (end) 索引,这些索引基于当前用户的索引和指定的分割大小 (split_size)。- 使用
.iloc[begin:end]从df_source中选取对应行范围的数据,创建一个子DataFrame (df_sub)。- 将当前的索引 (
idx)、用户名称 (user_name) 和子DataFrame (df_sub) 作为一个元组添加到列表df_subs中。idx是通过enumerate函数在遍历user_names列表时自动生成的索引值。enumerate是一个内置函数,它允许你在遍历一个序列(比如列表、字符串或元组)的同时,跟踪当前项的索引位置。
3.将每个dataframe存入excel
for idx, user_name, df_sub in df_subs:
file_name = f"{splits_dir}/crazyant_blog_articles_{idx}_{user_name}.xlsx"
df_sub.to_excel(file_name, index=False)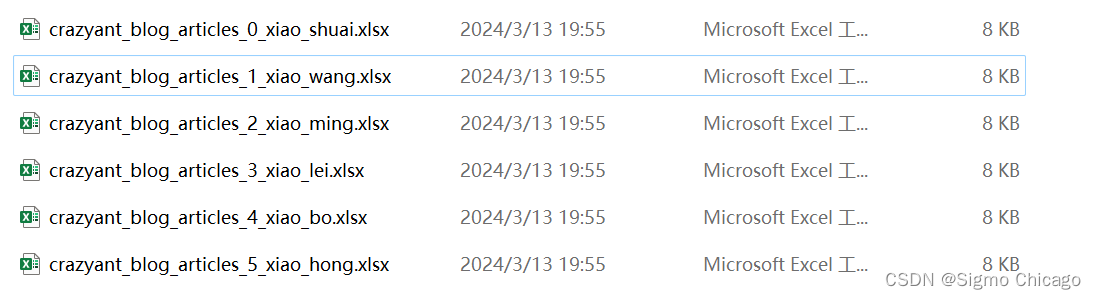
使用
index=False来避免将索引写入到Excel文件中。
四、合并多个小Excel到一个大Excel
- 遍历文件夹,得到要合并的Excel文件列表
- 分别读取到dataframe,给每个df添加一列用于标记来源
- 使用pd.concat进行df批量合并
- 将合并后的dataframe输出到excel
1.遍历文件夹,得到要合并的Excel名称列表
import os
excel_names = []
for excel_name in os.listdir(splits_dir):
excel_names.append(excel_name)
excel_names['crazyant_blog_articles_0_xiao_shuai.xlsx', 'crazyant_blog_articles_1_xiao_wang.xlsx', 'crazyant_blog_articles_2_xiao_ming.xlsx', 'crazyant_blog_articles_3_xiao_lei.xlsx', 'crazyant_blog_articles_4_xiao_bo.xlsx', 'crazyant_blog_articles_5_xiao_hong.xlsx']
2.分别读取到dataframe
df_list = []
for excel_name in excel_names:
# 读取每个excel到df
excel_path = f"{splits_dir}/{excel_name}"
df_split = pd.read_excel(excel_path)
# 得到username
username = excel_name.replace("crazyant_blog_articles_", "").replace(".xlsx", "")[2:]
print(excel_name, username)
# 给每个df添加1列,即用户名字
df_split["username"] = username
df_list.append(df_split)crazyant_blog_articles_0_xiao_shuai.xlsx xiao_shuai crazyant_blog_articles_1_xiao_wang.xlsx xiao_wang crazyant_blog_articles_2_xiao_ming.xlsx xiao_ming crazyant_blog_articles_3_xiao_lei.xlsx xiao_lei crazyant_blog_articles_4_xiao_bo.xlsx xiao_bo crazyant_blog_articles_5_xiao_hong.xlsx xiao_hong
!!dataframe没有append;list才有append方法!!
3.使用pd.concat进行合并
df_merged = pd.concat(df_list)
df_merged.shape(258, 4)
df_merged.head()
df_merged["username"].value_counts()username xiao_shuai 43 xiao_wang 43 xiao_ming 43 xiao_lei 43 xiao_bo 43 xiao_hong 43 Name: count, dtype: int64
4. 将合并后的dataframe输出到excel
df_merged.to_excel(f"{work_dir}/crazyant_blog_articles_merged.xlsx", index=False)总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。















 1388
1388











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









